Лабоцкий В.В. Управление знаниями
Подождите немного. Документ загружается.

121
Рис. 9.9
Рис. 9.10
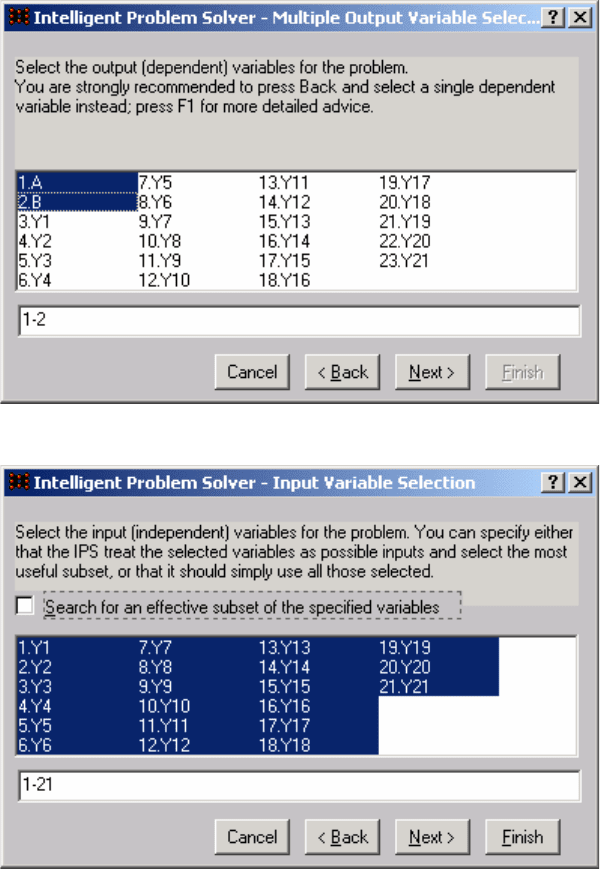
Весь входной массив будет поделен на три набора данных 50
значений для обучения (Traning), 25 – контрольных наблюдений для
проверки (Verification) и 25 – для независимого тестирования (Test). Опция
Randomly reassign… позволяет перемешать обучающие и контрольные
наблюдения в файле данных (рис. 9.11). Выберем
Multilayer Perceptron
(tree layer) (рис. 9.12). Выбор архитектуры сети для решения конкретной
задачи основывается на опыте разработчика. Поэтому предложенная ниже
архитектура сети является одним вариантом из множества возможных
конфигураций.
122
Рис. 9.11
Рис. 9.12
Отключите опцию Determine network complexity automatically на
рис. 9.13 и задайте число узлов на втором уровне 15.
123
Рис. 9.13
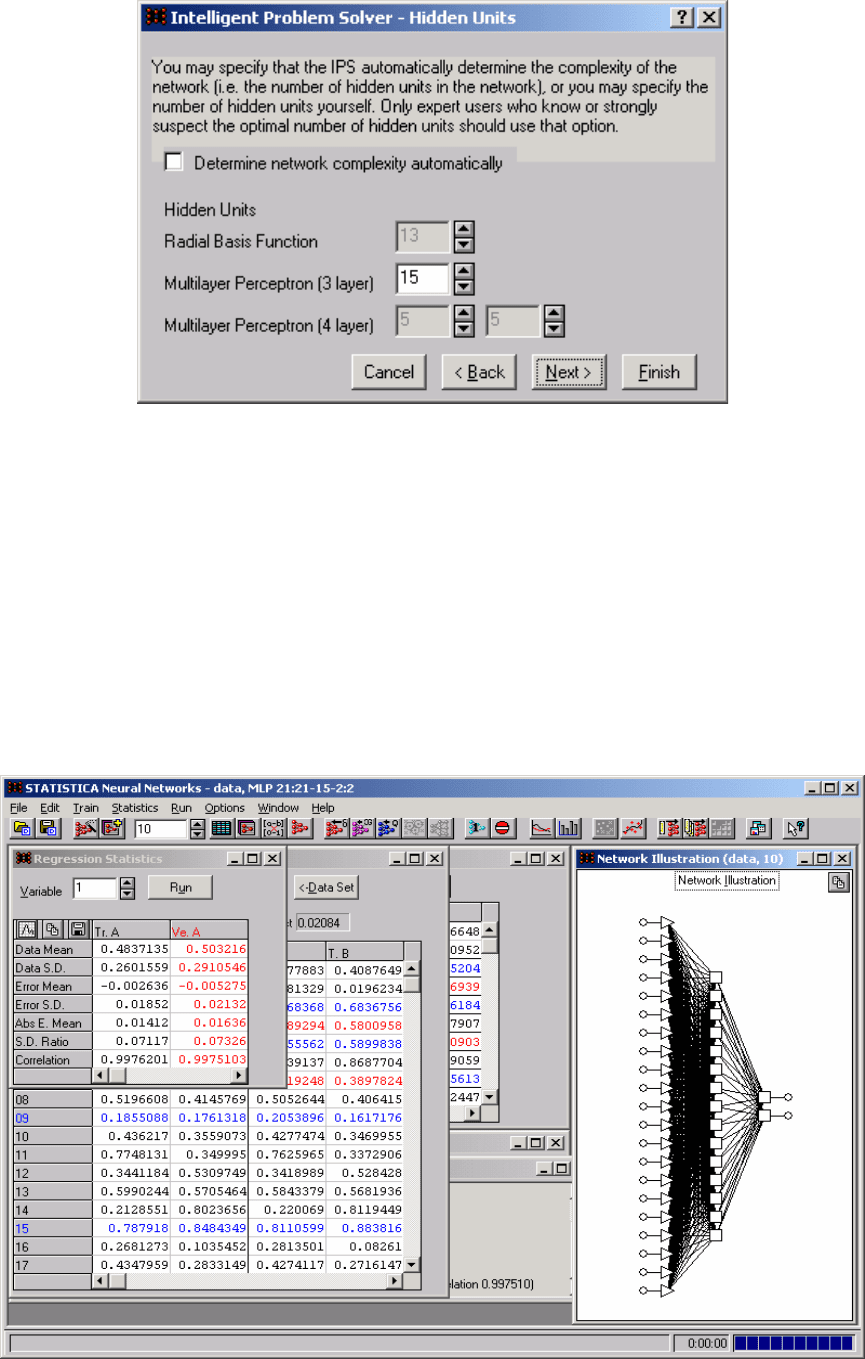
Нажимая три раза клавишу Next и не меняя никаких опций, после
нажатия на
Finish получим результат (рис. 9.14). На этом рисунке можно
увидеть саму сеть и результаты работы, а о том, насколько они хороши,
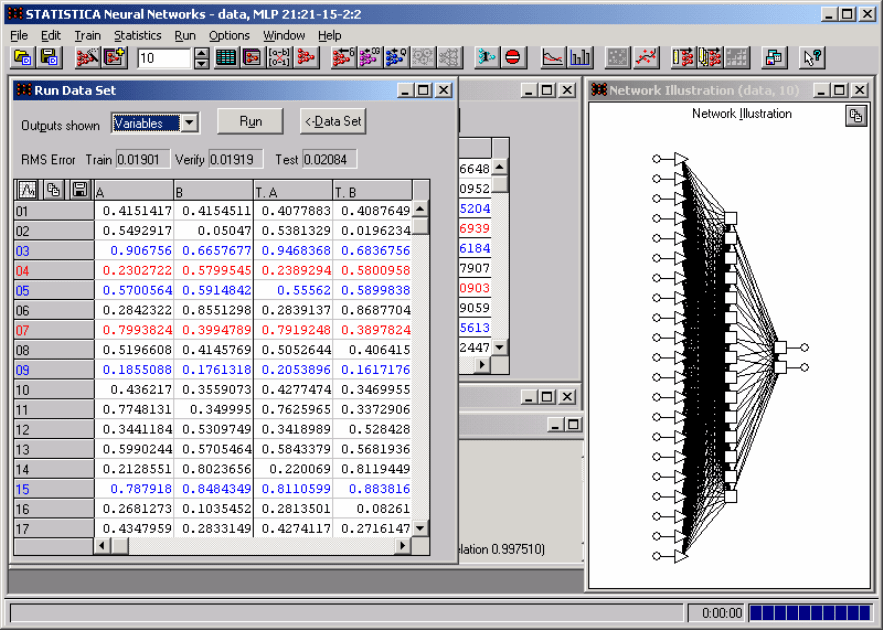
можно судить по команде
Run/Data Set (рис. 9.15). Черным цветом
выделен набор данных, на котором было выполнено обучение, красным
цветом – верификация, синим – независимое тестирование. В столбцах А и
В представлены оценки параметров
a
и
b
, а в столбцах T.A и T.B
"реальные (target)" значения этих параметров. Наилучшая нейронная сеть
имеет коэффициент корреляции равным 0,9975.
Рис. 9.14
124
Рис. 9.15
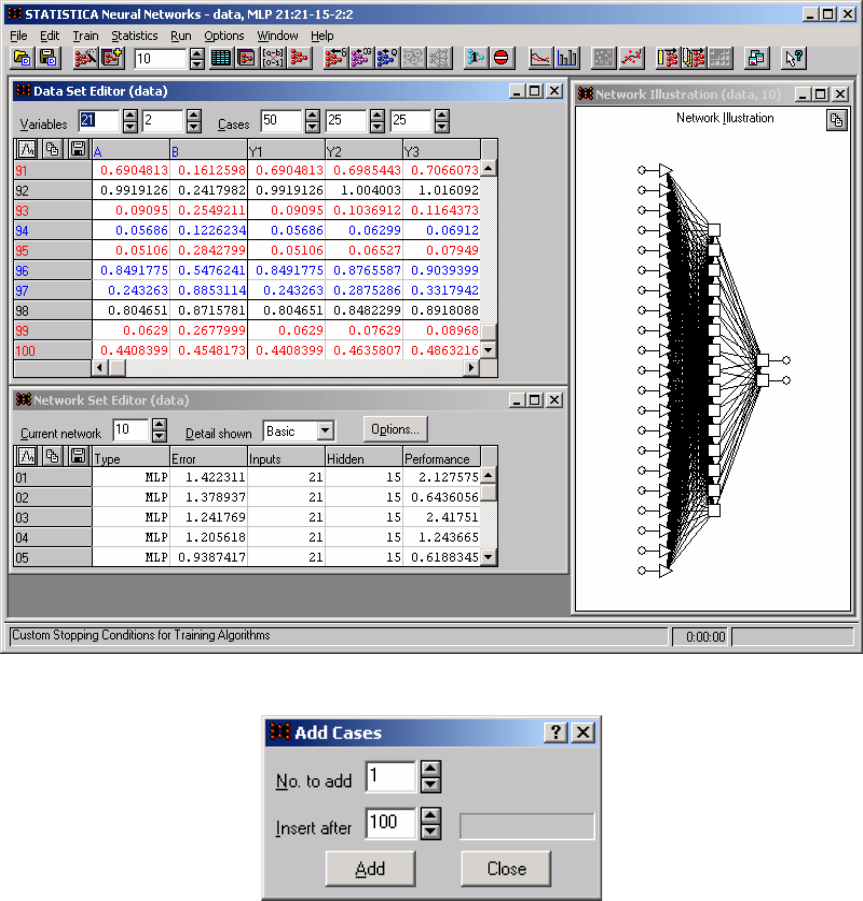
Попробуем применить полученную модель. Для этого сохраним
сначала нашу сеть по команде
Save/Network Set c именем data.bnt.
Перезапустим пакет
STATISTICA и откроем в модуле Neural Networks
файл data.sta, с соответствующей нейронной сетью (рис. 9.16). Дадим
команду
Edit/Cases/Add (рис. 9.17) и добавим одну строку, получим
результат (рис. 9.18).
125
Рис. 9.16
Рис. 9.17
126
Рис. 9.18
Рис. 9.19
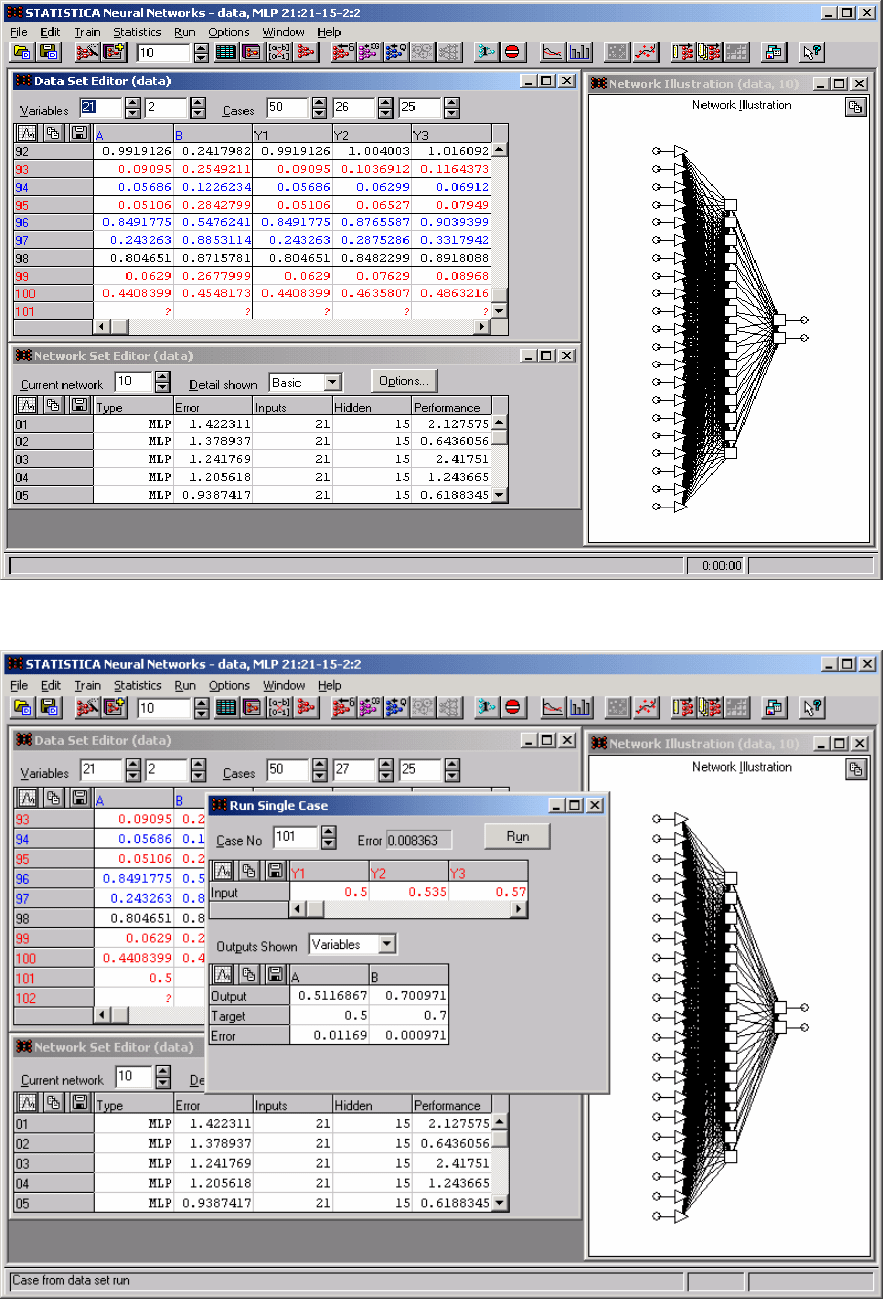
Пусть A=0.5 и B=0.7, тогда соответствующий входной вектор имеет
значения:
127
0,500 0,535 0,570 0,605 0,640 0,675 0,710 0,745 0,780 0,815 0,850 0,885
0,920 0,955 0,990 1,025 1,060 1,095 1,130 1,165 1,200.
Введем эти значения в таблицу. Выполним команду Run/Single Case
и зададим номер строки 101 – получим следующий результат (рис. 9.19),
что весьма близко к правильному результату:
Output 0.5116867 0.700971
Target 0.5 0.7
Error 0.01169 0.000971
9.4.2. Классификация
Задача классификации представляет собой задачу отнесения образца
к одному из нескольких попарно не пересекающихся множеств. Примером
таких задач может быть, например, задача определения
кредитоспособности клиента банка, решение задач управления портфелем
ценных бумаг (продать купить или "придержать" акции в зависимости от
ситуации на рынке), задача определения жизнеспособных и склонных к
банкротству фирм
.
Возможно несколько способов представления входных данных.
Наиболее распространенным является способ, при котором образец
представляется вектором. Компоненты этого вектора представляют собой
различные характеристики образца, которые влияют на принятие решения
о том, к какому классу можно отнести данный образец. Классификатор
относит объект к одному из классов в соответствии с определенным
разбиением N-мерного
пространства, которое называется пространством
входов, и размерность этого пространства является количеством
компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В
реальных задачах часто возникает ситуация, когда количество образцов
ограничено, что осложняет определение сложности задачи. Возможно
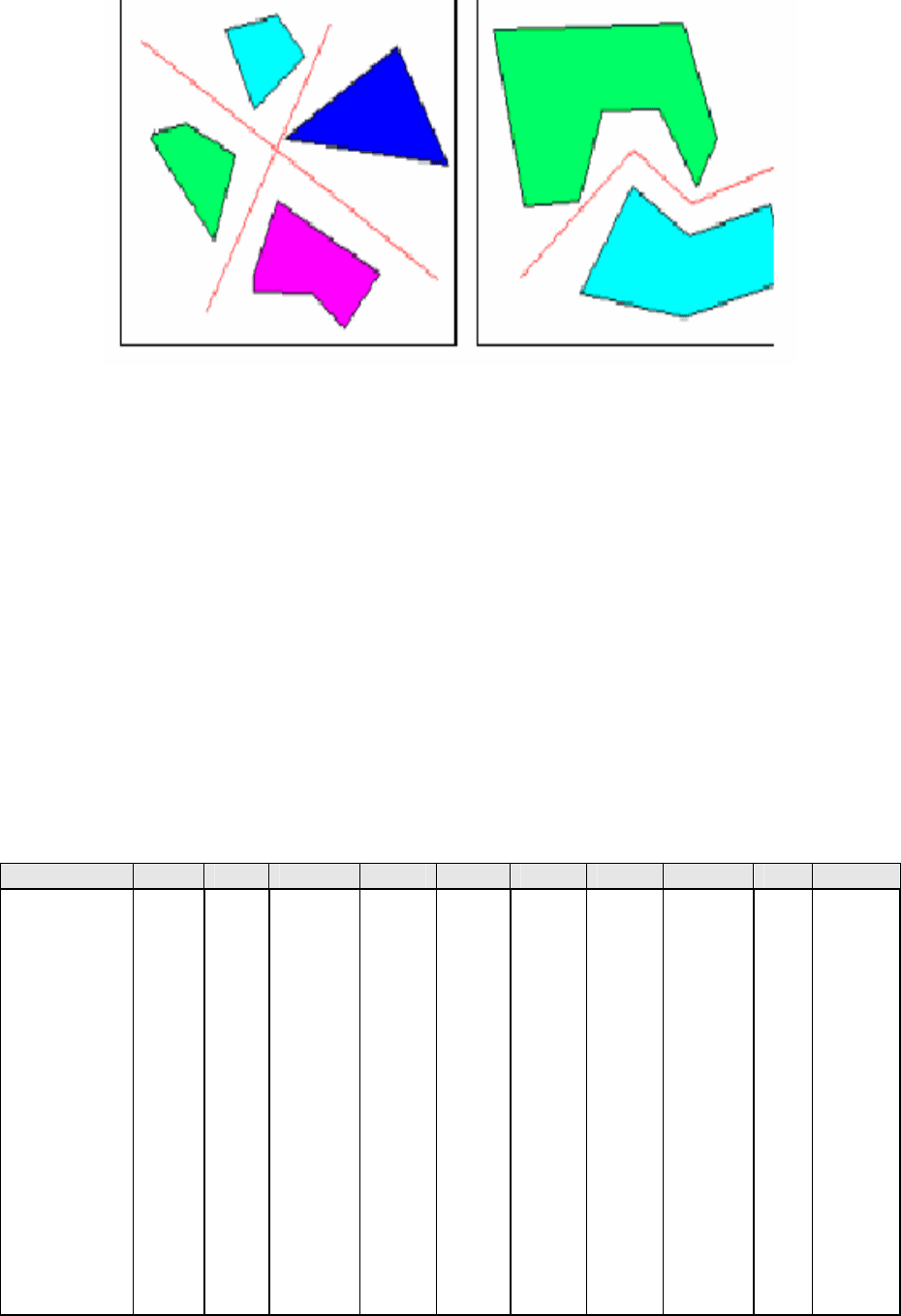
выделить три основных уровня сложности. Первый (самый простой) –
когда классы можно разделить прямыми линиями (
или гиперплоскостями,
если пространство входов имеет размерность больше двух) – так
называемая линейная разделимость. Во втором случае классы невозможно
разделить линиями (плоскостями), но их возможно отделить с помощью
более сложного деления – нелинейная разделимость (рис. 9.20). В третьем
случае классы пересекаются и можно говорить только о вероятностной
разделимости.
В идеальном варианте после предварительной
обработки мы должны
получить линейно разделимую задачу, так как после этого значительно
упрощается построение классификатора. К сожалению, при решении
реальных задач мы имеем ограниченное количество образцов, на
основании которых и производится построение классификатора. При этом
мы не можем провести такую предобработку данных, при которой будет
достигнута линейная разделимость образцов.
128
Рис. 9.20. Линейно и нелинейно разделимые классы
Далее необходимо определить способ представления входных
данных для нейронной сети, т.е. определить способ нормирования.
Нормировка необходима, поскольку нейронные сети работают с данными,
представленными числами в диапазоне 0..1, а исходные данные могут
иметь произвольный диапазон или вообще быть нечисловыми данными.
При этом возможны различные способы, начиная от простого линейного
преобразования в требуемый
диапазон и заканчивая многомерным
анализом параметров и нелинейной нормировкой в зависимости от
влияния параметров друг на друга.
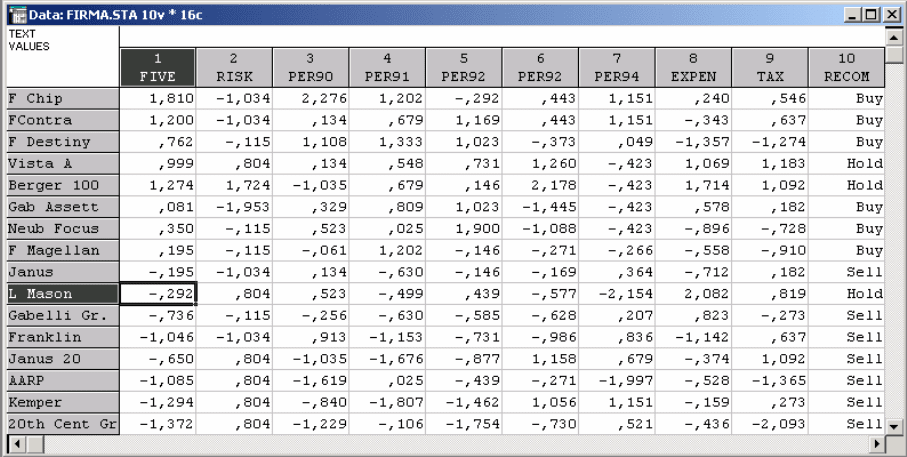
В качестве примера возьмем аналогичный пример из кластерного
анализа об инвестиционных фондах с целью оценки их состояния. С целью
удобства приведем исходные данные заново (табл. 9.2).
Таблица 9.2
Fund Five Risk Per90 Per91 Per92 Per93 Per94 Expens Tax Recom
Chip
FContra
F Destiny
Vista A
Berger 100
Gab Assett
Neub Focus
F Magellan
Janus
L Mason
Gabelli Gr.
Franklin
Janus 20
AARP
Kemper
20
th
Cent G
r
16476
15476
14757
15145
15596
13640
14081
13827
13187
13029
12301
11793
12441
11728
11386
11258
2
2
3
4
5
1
3
3
2
4
3
2
4
4
4
4
10
-1
4
-1
-7
0
1
-2
-1
1
-3
3
-7
-10
-6
-8
25
21
26
20
21
22
16
25
11
12
11
7
3
16
2
15
6
16
15
13
9
15
21
7
7
11
4
3
2
5
-2
-4
55
55
39
71
89
18
25
41
43
35
34
27
69
41
67
32
4
4
-3
-6
-6
-6
-6
-5
-1
-17
-2
2
1
-16
4
0
1,22
1,03
0,7
1,49
1,7
1,33
0,85
0,96
0,91
1,82
1,41
0,77
1,02
0,97
1,09
1
89
90
69
96
95
85
75
73
85
92
80
90
95
68
86
60
Buy
Buy
Buy
Hold
Hold
Buy
Buy
Buy
Sell
Hold
Sell
Sell
Sell
Sell
Sell
Sell
129
•
Запустите программу STATISTICA.
•
Появится диалоговое окно Statistica Module Switcher.
•
Выделите модуль Data Management/MFM и нажать кнопку
Switch To.
•
Откроется окно Data Management/MFM. Введите исходные
данные для переменных в столбцы VAR1 и VAR9 в следующем виде
(необходимо добавить 6 Cases) (табл. 8.2).
• Выполните команду Analysis/Standartize… Необходимо выбрать
все переменные (кроме RECOM) и все строки. Получим
стандартизованные значения исходных данных (рис. 9.21) и сохраним
полученные результаты.
Рис. 9.21
В системе STATISTICA выберем модуль Neural Networks и откроем
сохраненный ранее файл (рис. 9.22).
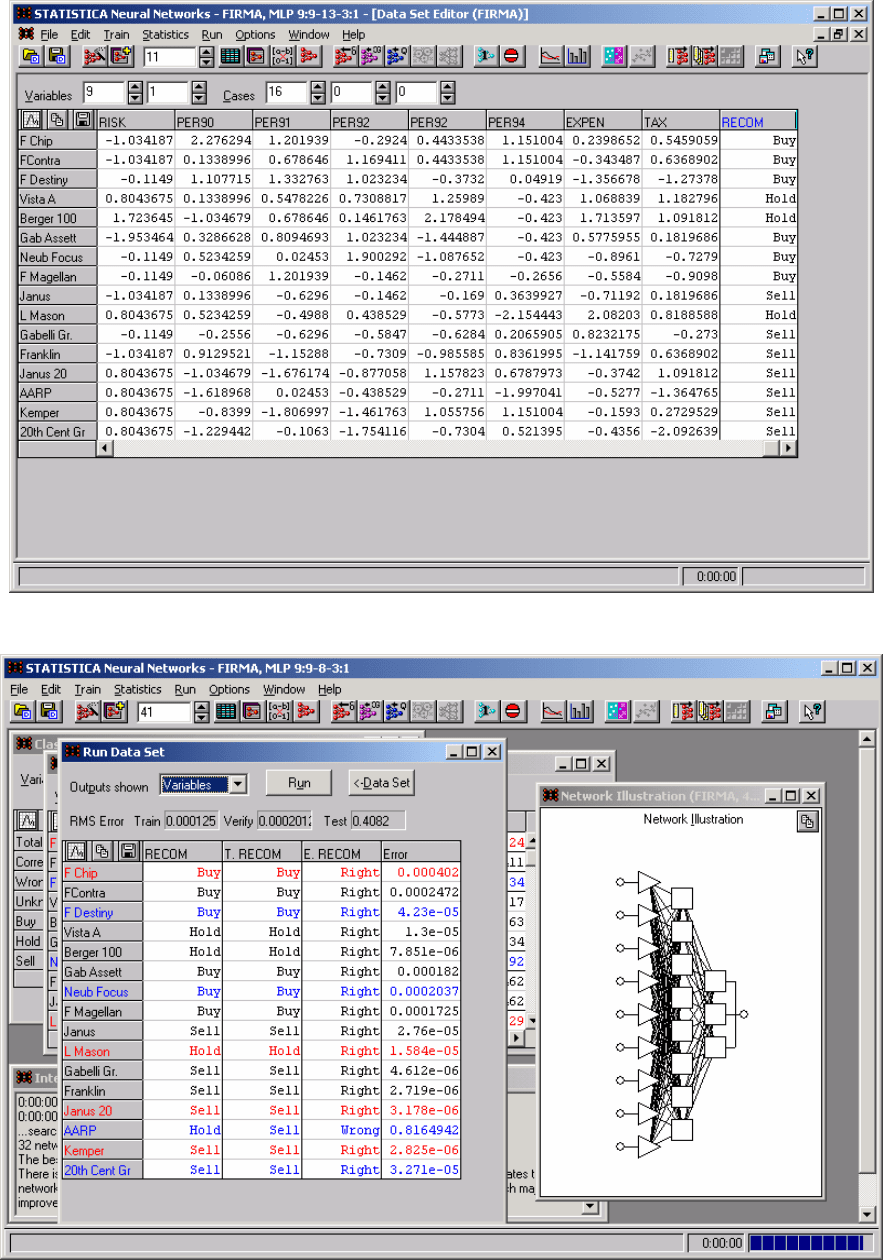
130
Рис. 9.22
Рис. 9.23
Попробуем полностью воспользоваться возможностями Inelligent
Problem Solver, не изменяя ничего в установках и получим следующий
результат (рис. 9.23).