Charles M. Kozierok The TCP-IP Guide
Подождите немного. Документ загружается.

The TCP/IP Guide - Version 3.0 (Contents) ` 1041 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
Recursive Resolution
When a client sends a recursive request to a name server, the server responds back with
the answer if it has the information sought. If it doesn't, the server takes responsibility for
finding the answer by becoming a client on behalf of the original client and sending new
requests to other servers. The original client only sends one request, and eventually gets
the information it wants (or an error message if it is not available). This technique is shown
in Figure 244.
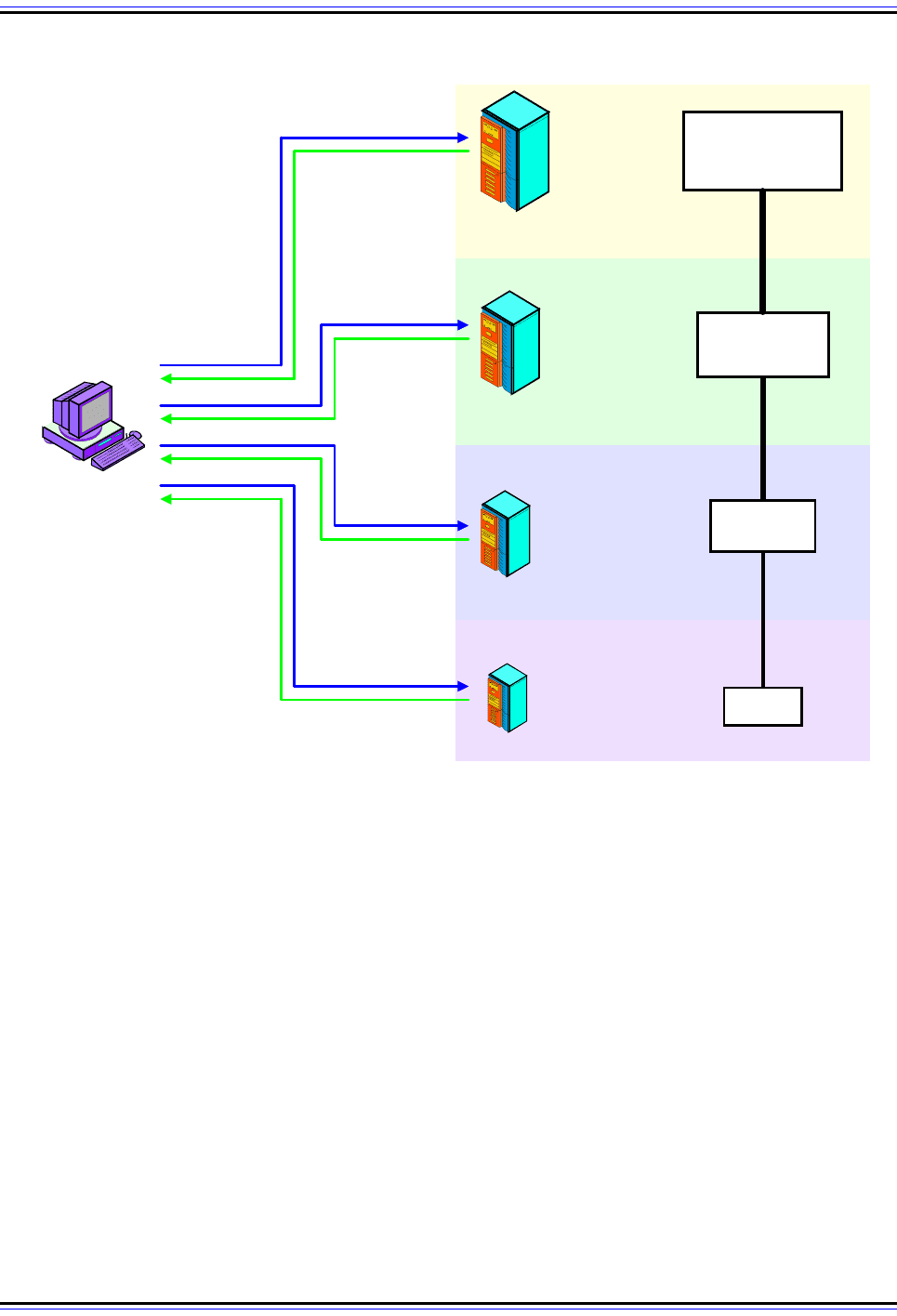
Figure 243: Iterative DNS Name Resolution
In this example, the client is performing a name resolution for “C.B.A.” using strictly iterative resolution. It is
thus responsible for forming all DNS requests and processing all replies. It starts by sending a request to the
root name server for this mythical hierarchy. That server doesn’t have the address of “C.B.A.”, so it instead
returns the address of the name server for “A.”. The client then sends its query to that name server, which
points the client to the server for “B.A.”. That name server refers the client to the name server that actually has
the address for “C.B.A.”, which returns it to the client. Contrast to Figure 244.
(root)
A
B
C
Root
Name
Server
Name
Server
for A.
Name
Server
for B.A.
Nam e
Serve r
for C.B.A.
Client
1. Resolution
Request
for C.B.A.
8. IP Address
for C.B.A.
2. Nam e Server
for A.
3. Resolution
Request
for C.B.A.
4. Nam e Server
for B.A.
5. Resolution
Request
for C.B.A.
6. Nam e Server
for C.B.A.
7. Resolution
Request
for C.B.A.

The TCP/IP Guide - Version 3.0 (Contents) ` 1042 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
Contrasting Iterative and Recursive Resolution
To help explain the difference between these methods, let's take a side-trip to a real-world
case. Suppose you are trying to find the phone number of your old friend Carol, with whom
you haven't spoken in years. You call your friend Joe; he doesn't have Carol's number, but
he gives you John's number, suggesting you call him. So you dial up John; he doesn't have
the information but he knows the number of Carol's best friend, Debbie, and gives that to
you. You call Debbie and she gives you Carol's information. This is an example of an
iterative process. In contrast, suppose you called Joe and Joe said “I don't know, but I think
I know how to find out “. He called John and then Debbie and called you back with the
phone number. That would be like recursive resolution.
Figure 244: Recursive DNS Name Resolution
This is the same theoretical DNS resolution that I showed in Figure 243, but this time, the client asks for the
name servers to perform recursive resolution and they agree to do so. As in the iterative case, the client sends
its initial request to the root name server. That server doesn’t have the address of “C.B.A.”, but instead of
merely returning to the client the address of the name server for “A.”, it sends a request to that server itself.
That name server sends a request to the server for “B.A.”, which in turn sends a request to the server for
“C.B.A.”. The address of “C.B.A.” is then carried back up the chain of requests, from the server of “C.B.A.” to
that of “B.A.”, then “A.”, then the root, and then finally, back to the client.
(root)
A
B
C
Root
Name
Server
Name
Server
for A.
Name
Server
for B.A.
Nam e
Serve r
for C.B.A.
Client
1. Resolution
Request
for C.B.A.
2. Resolution
Request
for C.B.A.
3. Resolution
Request
for C.B.A.
4. Resolution
Request
for C.B.A.
5. IP Address
for C.B.A.
8. IP Address
for C.B.A.
7. IP Address
for C.B.A.
6. IP Address
for C.B.A.
1. Resolution
Request
for A.B.C.D

The TCP/IP Guide - Version 3.0 (Contents) ` 1043 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
So in essence, iteration is doing the job yourself, while recursion is “passing the buck”. You
might think that everyone would always want to use recursion since it makes “the other guy”
do the work. This is true, but “passing the buck” is not considered good form if it is not done
with permission. Not all name servers support recursion, especially servers near the top of
the hierarchy. Obviously, we don't want to bog down the root name servers and the ones
that handle “.COM” and other critical TLDs with doing recursion. It is for this reason that
clients must request that name servers perform recursion for them.
One place where recursion is often used is with the local name server on a network. Rather
than making client machine resolvers perform iterative resolution, it is common for the
resolver to generate a recursive request to the local DNS server, which then generates
iterative requests to other servers as needed. As you can see, recursive and iterative
requests can be combined in a single resolution, providing significant flexibility to the
process as a whole. This is demonstrated in a more realistic example in the topic detailing
the DNS name resolution process.
Again, remember that for the purpose of understanding resolution, a DNS server can in fact
act as a client. As soon as a DNS server accepts a recursive request for resolution on a
name it cannot resolve itself, it becomes a client in the process. I should also point out that
it is common for resolvers to know the names of not one but two local DNS servers, so if a
problem occurs reaching the first they can try the second.
Key Concept: The two methods of name resolution in DNS are iterative resolution
and recursive resolution. In iterative resolution, if a client sends a request to a name
server that does not have the information the client needs, the server returns a
pointer to a different name server and the client sends a new request to that server. In
recursive resolution, if a client sends a request to a server that doesn’t have the requested
information, that server takes on the responsibility for sending requests to other servers to
find the necessary records, then returns them to the client. A server doing this takes on the
role of client for its requests to other servers.
DNS Name Resolution Efficiency Improvements: Caching and Local Resolution
The basic resolution techniques—iterative and recursive—can be considered “complete”
from an algorithmic standpoint. By starting at the top (root) and working our way down, we
are “guaranteed” to always eventually arrive at the server that has the information we need.
I put “guaranteed” in quotes only because as always, there are no real “guarantees” in
networking—we might have asked for a non-existent name, or a server might have bad
data for example. But in the absence of such atypical problems, the process leads to the
information eventually.

The TCP/IP Guide - Version 3.0 (Contents) ` 1044 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
The problem is that last word: “eventually”. Both iterative and recursive resolution will get us
to the right server, but they take a long time to do it, especially if the name we are trying to
resolve is in a “deep” part of the DNS hierarchy (for example, “F.E.D.C.B.A.”). Since
resolution is done so often, it is helpful to define changes to the basic resolution process
that improve efficiency as much as possible.
The Motivation for Caching: Locality of Reference
A computer science principle called locality of reference describes two common
phenomena related to how computers (and networks) are used. The first, sometimes called
spatial locality of reference, observes that a resource is more likely to be referenced if it is
near another resource that was recently referenced. The second, temporal locality of
reference, says a resource is more likely to be accessed if it was recently accessed.
We can observe both of these phenomenon by using the example of browsing the Web. To
observe spatial locality of reference, notice what happens when you visit a site such as
http://www.tcpipguide.com. The initial request asks the server for the main index document
of The TCP/IP Guide. However, that document contains links to several images and other
items, all of which are also located at the domain “tcpipguide.com”. When your browser
asks for the main document, it will shortly thereafter also ask for a number of graphics. Of
course, as you navigate the site, you will click links to go to other Web pages. Again here,
most of these will also be at the same domain, “tcpipguide.com”.
What this means is that if we resolve a particular domain name, it is likely that we will need
to resolve it again very soon in the future. It would be silly to have to interrogate the same
domain server dozens of times, each asking it to resolve the same name.
The second phenomenon, temporal locality of reference, is one you have probably noticed
yourself. You are far more likely to access a resource you have used recently than one you
have not looked at in a year. This means that maintaining information about recently-used
resources can be inherently advantageous.
Name Resolver Caching
These two phenomena are the rationale for caching in the computer world in general, and
as we have seen, in DNS servers in particular. The same advantages applies to resolvers,
and so many of them perform caching also, in a way rather similar to how it is done in
servers. On a particular client computer, once a particular name is resolved, it is cached
and remains ready for the next time it is needed. Again, this eliminates traffic and load on
DNS servers. (Note however that not all resolvers perform caching.)
You might be wondering why we bother having caching on both resolvers and servers. This
is not “redundant”, as it may appear. Or rather, it's redundant, but in a good way. To under-
stand why, we much recognize that a fundamental trade-off in caching is that a cache
provides better performance the closer it is the requestor of the data, but better coverage
the further it is from the user.

The TCP/IP Guide - Version 3.0 (Contents) ` 1045 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
If resolvers didn't cache results but our local server did, we could get the information from
the server's cache, but it would require waiting for the exchange of a query and response.
The resolver's cache is “closer” to the user and so more efficient. At the same time, this
doesn't obviate the need for caching at our network's local DNS server. The server is further
away from the user than the resolver, but its cache is shared by many machines. They can
all benefit from its cache, so that if I look up a particular name and then someone else does
a few minutes later, they can use my cached resolution even though they are typing it for
the first time.
Caching by name resolvers follows the same general principles and rules as caching by
name servers. The amount of time a resource record is specified by its Time To Live figure.
Also, resolvers will not cache the results of certain queries, such as reverse lookups, and
may also not cache a resolution if they suspect that for whatever reason the data returned
is unreliable or corrupted.
Key Concept: In addition to the caching performed by DNS name servers, many
(but not all) DNS resolvers also cache the results of recent resolution requests. This
cache is checked prior to beginning a name resolution, to save time when multiple
requests are made for the same name.
Local Resolution
One other area where resolution efficiency can be improved is the special case where we
are trying to resolve the names of computers in our own organizations. Suppose that I, an
employee at XYZ Industries, want to get some sales information using FTP from
“sales.xyzindustries.com”. My FTP client will invoke my local resolver to resolve that name,
by sending it to our local DNS server. Now, would it be smart for that server, which is here
inside the company, to start the resolution process up at the root name server? Not really.
The local DNS server that accepts local resolution requests from resolvers on the network
may in fact be the authoritative name server for “sales.xyzindustries.com”. In other cases, it
may know how to answer certain resolution requests directly. Obviously, it makes sense for
the server to check to see if it can answer a resolver's query before heading up to the root
server, since this provides a faster answer to the client and saves internetwork traffic. This
is called local resolution.
Most DNS servers will perform this check to see if they have the information needed for a
request before commencing the “formal” top-down resolution process. The exception is
DNS servers that do not maintain information about any zones: caching-only servers. In
some cases, DNS resolvers on client machines may also have access to certain local zone
information, in which case they can use it instead of sending a resolution query at all.

The TCP/IP Guide - Version 3.0 (Contents) ` 1046 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
There's one more thing I also want to point out: most operating systems also support the
use of the old host table mechanism, which can be useful for local machines on a network.
If a host has a host table, the resolver will check the host table to see if it can find a mapping
for a name before it will bother with the more time-consuming DNS resolution process. This
is not technically part of DNS, but is often used in conjunction with it.
DNS Name Resolution Process
In the previous topics I have described what name resolvers do, explained the basic top-
down resolution process using iterative and recursive resolution, and discussed how local
resolution and caching are used to improve resolution performance. Now I would like to tie
all this background material together and finally show you how the name resolution process
works as a whole!
As usual, the best way to do this is by example. Here, I will actually combine two examples
I have used earlier: the fictitious company “XYZ Industries” and the non-existent college,
Googleplex University. Let's say that XYZ Industries runs its own DNS servers for the
“xyzindustries.com” zone. The master name server is called “ns1.xyzindustries.com”, and
the slave is, ta-da, “ns2.xyzindustries.com”. These are also used as local DNS servers for
resolvers on client machines. We'll assume for this example that as is often the case, our
DNS servers will accept recursive requests from machines within our company, but will not
assume other machines will accept such requests. Let's also assume that both the server
and resolver perform caching, and that the caches are empty.
Let's say that Googleplex University runs its own DNS servers for the “googleplex.edu”
domain, as I gave in the example in the topic describing DNS zones. There are three
subdomains: finearts.googleplex.edu, compsci.googleplex.edu, and admin.googleplex.edu.
Of these, compsci.googleplex.edu is in a separate zone with dedicated servers, while the
other subdomains are in the “googleplex.edu” zone (this is shown in Figure 240.)
Resolution Process Steps
Now, suppose you are an employee within XYZ Industries and one of your clients is in
charge of the networking department at Googleplex U. You type into your Web browser the
address of this department's Web server, “www.net.compsci.googleplex.edu”. In simplified
terms, the procedure would involve the following set of steps (Figure 245 shows the
process graphically):
1. Your Web browser recognizes the request for a name and invokes your local resolver,
passing to it the name “www.net.compsci.googleplex.edu”.
2. The resolver checks its cache to see if it already has the address for this name. If it
does, it returns it immediately to the Web browser, but in this case we are assuming
that it does not. The resolver also checks to see if it has a local host table file. If so, it
scans the file to see if this name has a static mapping. If so, it resolves the name using
this information immediately. Again, let's assume it does not, since that would be
boring.
3. The resolver generates a recursive query and sends it to “ns1.xyzindustries.com”
(using that server's IP address, of course, which the resolver knows).

The TCP/IP Guide - Version 3.0 (Contents) ` 1047 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
4. The local DNS server receives the request and checks its cache. Again, let's assume
it doesn't have the information needed. If it did, it would return the information, marked
“non-authoritative”, to the resolver. The server also checks to see if it has in its zone
resource records that can resolve “www.net.compsci.googleplex.edu”. Of course it
does not, in this case, since they are in totally different domains.
5. “ns1.xyzindustries.com” generates an iterative request for the name and sends it to a
root name server.
6. The root name server does not resolve the name. It returns the name and address of
the name server for the “.edu” domain.
7. “ns1.xyzindustries.com” generates an iterative request and sends it to the name server
for “.edu”.
8. The name server for “.edu” returns the name and address of the name server for the
“googleplex.edu” domain.
9. “ns1.xyzindustries.com” generates an iterative request and sends it to the name server
for “googleplex.edu”.
10. The name server for “googleplex.edu” consults its resource records. It sees, however,
that this name is in the “compsci.googleplex.edu” subdomain, which is in a separate
zone. It returns the name server for that zone.
11. “ns1.xyzindustries.com” generates an iterative request and sends it to the name server
for “compsci.googleplex.edu”.
12. The name server for “compsci.googleplex.edu” is authoritative for
“www.net.compsci.googleplex.edu”. It returns the IP address for that host to
“ns1.xyzindustries.com”.
13. “ns1.xyzindustries.com” caches this resolution. (Note that it will probably also cache
some of the other name server resolutions that it received in steps #6, #8 and #10; I
have not shown these explicitly.)
14. The local name server returns the resolution to the resolver on your local machine.
15. Your local resolver also caches the information.
16. The local resolver gives the address to your browser.
17. Your browser commences an HTTP request to the Googleplex machine's IP address.
Seems rather complicated and slow. Of course, computers work faster than you can read
(or I can type, for that matter.) Even given that, the benefits of caching are obvious—if the
name was in the cache of the resolver or the local DNS server, most of these steps would
be avoided.
Changes to Resolution to Handle Special Cases
This example is highly simplified, and also only shows one possible way that servers might
be set up. For one thing, it is possible that even though “compsci.googleplex.edu” is in a
separate zone from “googleplex.edu”, they might use the same server. In that case, one
iteration in the process would be skipped. The example also above doesn't show what
happens if an error occurs in the process.
The TCP/IP Guide - Version 3.0 (Contents) ` 1048 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
If the domain name entered was an alias, indicated by a CNAME record, this would change
the processing as well. CNAME records are used to allow a “constant” name for a device to
be presented to the outside world while allowing the actual device that corresponds to the
name to vary inside the organization. When a CNAME is used, it changes the name
resolution process by adding an extra step: first we resolve the alias to the canonical name
and then resolve the canonical name.
For example, Web servers are almost always named starting with “www.”, so at XYZ Indus-
tries we want people to be able to find our Web site at “www.xyzindustries.com”. However,
the Web server may in fact be shared with other services on “bigserver.xyzindustries.com”.
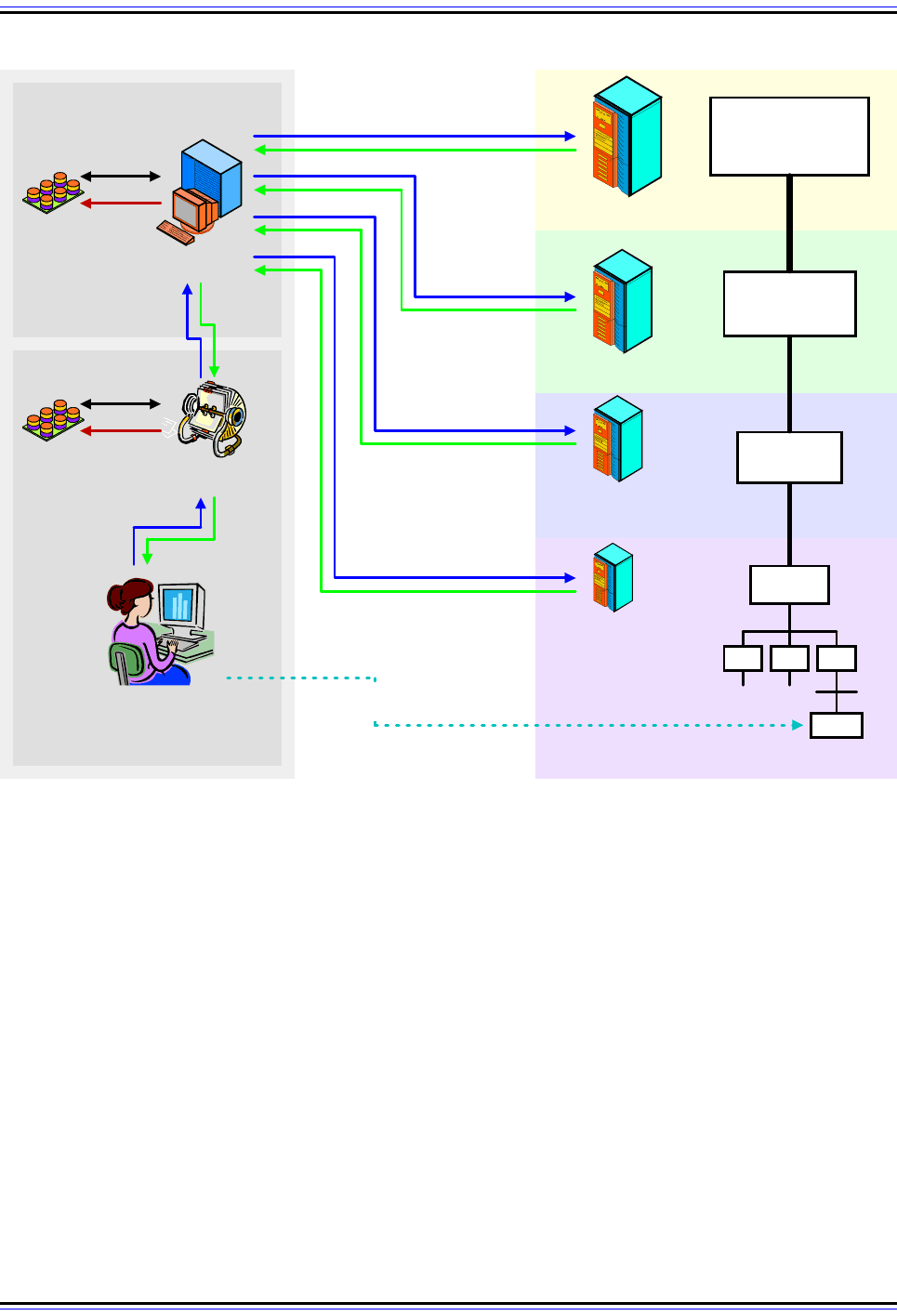
Figure 245: Example Of The DNS Name Resolution Process
This fairly complex example illustrates a typical DNS name resolution using both iterative and recursive
resolution. The user types in a DNS name (“www.net.compsci.googleplex.edu”) into a Web browser, which
causes a DNS resolution request to be made from her client machine’s resolver to a local DNS name server.
That name server agrees to resolve the name recursively on behalf of the resolver, but uses iterative requests
to accomplish it. These requests are sent to a DNS root name server, followed in turn by the name servers for
“.edu”, “googleplex.edu” and ‘compsci.googleplex.edu”. The IP address is then passed to the local name
server and then back to the user’s resolver and finally, her Web browser software.
(root)
edu
googleplex
compsci
...
Root Name Server
.edu Name Server
googleplex.edu
Name Server
compsci.googleplex.edu
Nam e Se r ve r
Client
Local Name Server
Cache
Cache Resolver
Server
User & Brow ser
5. Iterative Query to root
6. Name Server for .edu
8. Name Server for
googleplex.edu
7. Iterative
Query to .edu
4. Check
Cache
9. Iterative Query
to googleplex.edu
10. Nam e Server for
compsci.googleplex.edu
11. Iterative Query to
compsci.googleplex.edu
12. IP Address for
www.net.compsci .googleplex.edu
3. Recursive
Que r y
1. Resolution
Request
13. Update
Cache
14. Requested
IP Address
2. Check
Cache
15. Update
Cache
16. Requested
IP Address
17. HTTP Request
to Resolved Address
hw sw net
www
...
... ...

The TCP/IP Guide - Version 3.0 (Contents) ` 1049 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
We can set up a CNAME record to point “www.xyzindustries.com” to “bigserver.xyzindus-
tries.com”. Resolution of “www” will result in a CNAME pointing to “bigserver”, which is then
itself resolved. If in the future our business grows and we decide to upgrade our Web
service to run on “biggerserver.xyzindustries.com”, we just change the CNAME record and
users are unaffected.
DNS Reverse Name Resolution Using the IN-ADDR.ARPA Domain
If most people had to boil down the core job of the Domain Name System to one function,
they would probably say it was converting the names of objects into the numeric IP
addresses associated with them. Well, they would if they knew much about DNS. For this
reason, DNS is sometimes compared to a telephone book, or to telephone “411” service.
There are certain problems with this analogy, but at the highest level it is valid. In both
cases we take a name, consult a database (of one type or another), and produce from it a
number that matches that name.
The Need for Reverse Name Resolution
In the real world, there are sometimes situations where you don't want to find the phone
number that goes with a name, but rather, you have a phone number and want to know
what person it belongs to. For example, this might happen if your telephone records the
number of incoming calls but you don't have Caller ID to display the name associated with a
number. You might also find a phone number on a piece of paper and not remember whose
number it is.
Similarly, in the networking world, there are many situations where we have an IP address
and want to know what name goes with it. For example, a World Wide Web server records
the IP address of each device that connects to it in its server logs, but these numbers are
generally meaningless to humans, who prefer to see the names that go with them.
A more serious example might be a hacker trying to break into your computer; by
converting the IP address into a name you might be able to find out what part of the world
he is from, what ISP he is using, and so forth. There are also many reasons why a network
administrator might want to find out the name that goes with an address, for setup or
troubleshooting purposes.
The Original Method: Inverse Querying
DNS originally included a feature called inverse querying that would allow this type of
“opposite” resolution. A resolver could send a query which, instead of having a name filled
in and a space for the server to fill in the IP address, had the IP address and a space for the
name. The server would check its resource records and return the name to the resolver.
This works fine in theory, and even in practice if the internetwork is very small. However,
remember that due to the distributed nature of DNS information, the biggest part of the job
of resolution is in fact finding the right server. Now, in the case of regular resolution, we can
easily find the right server by traversing the hierarchy of servers. This is possible because
the servers are connected together following a hierarchy of names.

The TCP/IP Guide - Version 3.0 (Contents) ` 1050 _ © 2001-2005 Charles M. Kozierok. All Rights Reserved.
DNS servers are not, however, arranged based on IP address. This means that to use
inverse queries, we have to use the right name server for the IP address we want to resolve
into a name, with no easy way to find out what it is. Sure, we could try sending the inverse
query to the authoritative DNS server for every zone in the hierarchy. If you tried, it would
probably take you longer than it took to write this Guide. So let's not go there. The end
result of all of this is that inverse queries were never popular except for local server trouble-
shooting. They were formally removed from DNS in November 2002 through the publishing
of RFC 3425.
The IN-ADDR.ARPA Name Structure for Reverse Resolution
The problem here is that the servers are arranged by name and not be IP address. The
solution, therefore, is as simple as it sounds: arrange the servers by IP address. This
doesn't mean we remove the name hierarchy, or duplicate all the servers, or anything silly
like that. Instead, we create an additional, numerical hierarchy that coexists with the name
hierarchy. We then use this to find names from numbers, using a process commonly called
reverse name resolution.
The name hierarchy for the Internet is implemented using a special domain called “IN-
ADDR.ARPA”, located within the reserved “.ARPA” top-level domain (“IN-ADDR” stands for
“INternet ADDRess”. Recall that “.ARPA” was originally used to transition old Internet hosts
to DNS, and is now used by the folks that run the Internet for various purposes.
A special numerical hierarchy is created within “IN-ADDR.ARPA” that covers the entire IP
address space:
☯ At the first level within “IN-ADDR.ARPA” there are 256 subdomains called “0”, “1”, “2”
and so on, up to “255”. For example, “191.IN-ADDR.ARPA”. (Actually there may not be
all 256 of these since some IP addresses are reserved, but let's ignore that for now).
☯ Within each of the subdomains above, there are 256 further subdomains at the second
level, numbered the same way. So for example, one of these would be “27.191.IN-
ADDR.ARPA”.
☯ Again, there are 256 subdomains at the third level within each of the above, such as
“203.27.191.IN-ADDR.ARPA”
☯ Finally, there are 256 subdomains at the fourth level within each of the third-level
subdomains, such as “8.203.27.191.IN-ADDR.ARPA”.
This structure is illustrated in Figure 246. As you can see, within “IN-ADDR.ARPA” we have
created a name space that parallels the address space of the Internet Protocol. (Yes, this
means there are several billion nodes and branches in this part of the Internet DNS name
space!)