Marinai S., Fujisawa H. (eds.) Machine Learning in Document Analysis and Recognition
Подождите немного. Документ загружается.

328 S. Tulyakov and V. Govindaraju
usually hard to train class-specific combination types of medium I and high
complexity since the number of training samples for each class can be too
small. As an example justifying medium II combinations in biometrics, [19]
argued for applying T-normalizations in face verification competition. Ranks,
T-normalization and many other investigated score normalization approaches
are usually non-trainable. The concept of identification model implies that
thereissometraininginvolved.
7.3 Identification Model for Weighted Sum
We will use the following idea for our identification model in this section. The
confidence of a matching score is determined by the score itself and by the
other scores in the same identification trial. If for a given score of a classifier
there is another score in the same trial which is higher, then we have less
confidence that the score belongs to the genuine class. Conversely, if all other
scores are lower than a given score, we have more confidence that the score
belongs to the genuine class.
The identification model in this case will consists in considering the follow-
ing function of the identification trial scores: sbs(s
j
i
)-thebestscorebesides
score s
j
i
in set of the current identification trial scores {s
j
i
}
i=1,...,N
of classifier
j:
sbs(s
j
i
)= max
k=1,...,N;k=i
s
j
k
(11)
We use the 1-step identification model combination with weighted sum com-
bination function. It means that instead of using only matching scores s
j
i
,
j =1,...,M for producing combined score S
i
of class i, we will be using
both s
j
i
and sbs(s
j
i
). For two classifiers in our applications we will have the
following combination function:
S
i
= w
1
s
1
i
+ w
2
sbs(s
1
i
)+w
3
s
2
i
+ w
4
sbs(s
2
i
) (12)
The number of considered input parameters for this method is two times
bigger than the number of input parameters to the original weighted sum
rule. We can still use the brute force approach to train the corresponding
weights. Note, that though the number of weights is increased, the increase is
rather small in comparison to the total number of classes (thousands). Thus
we achieved the good trade-off between taking into consideration all scores
produced by classifiers and the simplicity of training combination function.
The results of the experiments are presented in the Table 4 (Weighted
Sum + Ident Model). The method outperforms all other methods for identifi-
cation tasks. Note, that as in all our experiments, we used separate data sets
for training weights and testing the trained method; thus the performance
improvement is due not to more possibilities for training, but due to more
complex combination function.

Learning Matching Score Dependencies for Classifier Combination 329
7.4 Identification Model for Verification Systems
Although most verification systems use only matching scores for one given
class to make combinations and decisions on whether the class is genuine
or impostor, there is an idea that the performance can be improved if the
matching scores for other classes are taken into consideration. In fact, most of
the cohort score normalization methods, which we referenced above, employ
a superfluous set of matching scores for a cohort of a given class in order
to make verification decision. These scores might be available naturally in
identification system, but the verification system has to do additional matches
to create these scores.
If the scores for other classes are available in addition to the score for a
given class, they can provide significant amount of information to the com-
bination algorithm. Indeed, as we discussed before, the matching scores are
usually dependent and the dependence is caused by the quality of the in-
put sample. Scores for other classes can implicitly provide us the information
about the input sample quality. Consequently, we can view the application of
identification model as score normalization with respect to the input sample.
The information supplied by the identification model can be considered
as a predictor about the given score we consider in the verification task. We
imply that this score is genuine, and the goal of the identification model is to
check if this score is reasonable in comparison with scores we get for other,
impostor, scores. Thus we can check the correlations of the genuine score with
different functions of the impostor scores in order to find the statistics, which
best predict the genuine score. Table 3 contains the correlation measurements
for our matchers, and these measurements can be used to determine which
statistics of impostor scores the identification model should include. In our
experiments we considered first and second best impostor statistics. They seem
to be good predictors according to Table 3, and, as an additional advantage,
first few best scores are usually available due to the utilizing indexing methods
in identification systems.
The application of the identification model in verification system is clear
now. Instead of taking a single match score for a given class from a particular
matcher, take few additional match scores for other class, and calculate some
statistics from them. Then use these statistics together with a match score
for a designated class in the combination. Since the likelihood ratio method
is optimal for verification tasks, we use it here. If we employ the statistic of
second best score from the previous section, our combination method will be
written as
f
lr
(s
1
i
,...,s
M
i
; {s
j
k
}
j=1,...,M;k=1,...,N;k=i
)=
p
gen
(s
1
i
,sbs(s
1
i
),...,s
M
i
,sbs(s
M
i
))
p
imp
(s
1
i
,sbs(s
1
i
),...,s
M
i
,sbs(s
M
i
))
(13)
Note that we are dealing with the verification task, so we only produce the
combined score for thresholding, and do not select among classes with arg max.
Also, during our experiments we used a little different statistics than the
330 S. Tulyakov and V. Govindaraju
statistics sbs =max
k=1,...,N;k=i
s
j
k
from the previous section - we selected the
second ranked score from {s
j
k
,k =1,...,N; k = i}.
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
FRR
FAR
Likelihood Ratio
Likelihood Ratio + Identification Model
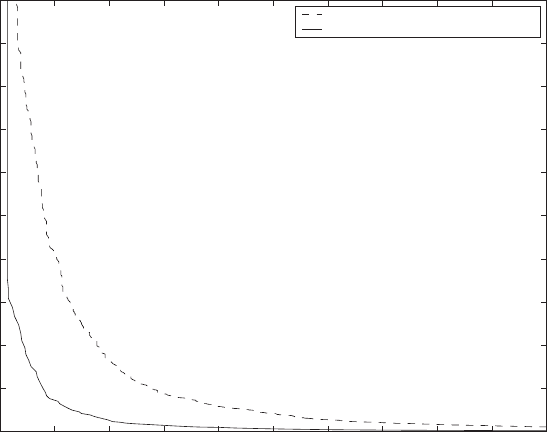
Fig. 9. The effect of utilizing identification model in the likelihood ratio combination
function for handwritten word recognizers
Figure 9 contains the resulting ROC curve from utilizing identification
model by equation 13 in the combination of word recognizers. Note, that
this method performs significantly better than the original likelihood ratio
method. We have also reported similar improvements for the biometric match-
ers before[20].
If we look at the verification task as the two class pattern classification
problem in the M-dimensional score-feature space, then using identification
model corresponds to expanding the feature space by the statistics of iden-
tification trials. The achieved improvements confirm the usefulness of these
additional features.
8 Summary
In this work we considered combinations of handwritten word recognizers
and biometric matchers. There can be different operating scenarios for the
Learning Matching Score Dependencies for Classifier Combination 331
applications involving these matchers, and we considered two of them - ver-
ification and closed set identification. Different operating scenarios require
different performance measures: ROC curves for verification problems, and
correct identification rate for identification problems.
It turns out that for different scenarios we need to construct different
combination algorithms in order to achieve optimal performance. This need is
caused by the frequent dependence among scores produced by each matcher
during a single identification trial. The optimal combination algorithm for
verification systems corresponds to the likelihood ratio combination function.
It can be implemented by the direct reconstruction of this function with gen-
uine and impostor score density approximations. Alternatively, many generic
pattern classification algorithms can be used to separate genuine and impos-
tor scores in the M-dimensional score space, M is the number of combined
matchers.
The optimal combination algorithm for the identification systems is more
difficult to realize. We do not know how to express analytically the optimal
combination function, and can only speculate on the heuristics leading to its
construction. We described two possible approaches for approximating the
optimal combination function in identification systems and compared them
with traditionally used weighted sum combination method. The results are
promising, but it is clear, that further development is needed in this area.
The concept of identification model provides a different point of view on
the combinations in identification systems. The score dependence in iden-
tification trials can be explicitly learned in these models. The combination
algorithm utilizing identification model uses more information about identifi-
cation trial scores than traditional combination methods relying on a single
match score for designated class. As a result it is possible to achieve significant
improvements using these models.
References
1. Favata, J.: Character model word recognition. In: Fifth International Workshop
on Frontiers in Handwriting Recognition, Essex, England (1996) 437–440
2. Kim, G., Govindaraju, V.: A lexicon driven approach to handwritten word recog-
nition for real-time applications. Pattern Analysis and Machine Intelligence,
IEEE Transactions on 19(4) (1997) 366–379
3. Nist biometric scores set. http://www.nist.gov/biometricscores/ (2007)
4. Tulyakov, S., Govindaraju, V.: Classifier combination types for biometric appli-
cations. In: 2006 IEEE Computer Society Conference on Computer Vision and
Pattern Recognition (CVPR 2006), Workshop on Biometrics, New York, USA
(2006)
5. G. Kim, V. Govindaraju: Bank check recognition using cross validation between
legal and courtesy amounts. Int’l J. Pattern Recognition and Artificial Intelli-
gence 11(4) (1997) 657–674
6. Bolle, R.M., Connell, J.H., Pankanti, S., Ratha, N.K., Senior, A.W.: Guide To
Biometrics. Springer, New York (2004)
332 S. Tulyakov and V. Govindaraju
7. Theodoridis, S., K., K.: Pattern Recognition. Academic Press (1999)
8. Silverman, B.W.: Density estimation for statistics and data analysis. Chapman
and Hall, London (1986)
9. Tulyakov, S., V., G.: Using independence assumption to improve multimodal
biometric fusion. In: 6th International Workshop on Multiple Classifiers Systems
(MCS2005), Monterey, USA, Springer (2005)
10. Ho, T.K., Hull, J.J., Srihari, S.N.: Decision combination in multiple classifier sys-
tems. Pattern Analysis and Machine Intelligence, IEEE Transactions on 16(1)
(1994) 66–75
11. Brunelli, R., Falavigna, D.: Person identification using multiple cues. Pattern
Analysis and Machine Intelligence, IEEE Transactions on 17(10) (1995) 955–966
12. Saranli, A., Demirekler, M.: A statistical unified framework for rank-based mul-
tiple classifier decision combination. Pattern Recognition 34(4) (2001) 865–884
13. Jain, A., Nandakumar, K., Ross, A.: Score normalization in multimodal biomet-
ric systems. Pattern Recognition 38(12) (2005) 2270–2285
14. Kittler, J., Hatef, M., Duin, R., Matas, J.: On combining classifiers. Pattern
Analysis and Machine Intelligence, IEEE Transactions on (1998) 226–239
15. Rosenberg, A., Parthasarathy, S.: Speaker background models for connected
digit password speaker verification. In: Acoustics, Speech, and Signal Process-
ing, 1996. ICASSP-96. Conference Proceedings., 1996 IEEE International Con-
ference on. Volume 1. (1996) 81–84 vol. 1
16. Colombi, J., Reider, J., Campbell, J.: Allowing good impostors to test. In: Sig-
nals, Systems & Computers, 1997. Conference Record of the Thirty-First Asilo-
mar Conference on. Volume 1. (1997) 296–300 vol. 1
17. Auckenthaler, R., Carey, M., Lloyd-Thomas, H.: Score normalization for text-
independent speaker verification systems. Digital Signal Processing 10(1-3)
(2000) 42–54
18. Mariethoz, J., Bengio, S.: A unified framework for score normalization tech-
niques applied to text independent speaker verification. IEEE Signal Processing
Letters 12 (2005)
19. Grother, P.: Face recognition vendor test 2002 supplemental report, nistir 7083.
Technical report, NIST (2004)
20. Tulyakov, S., Govindaraju, V.: Identification model for classifier combinations.
In: Biometrics Consortium Conference, Baltimore, MD (2006)

Perturbation Models for Generating Synthetic
Training Data in Handwriting Recognition
Tam´as Varga and Horst Bunke
University of Bern
Institute of Computer Science and Applied Mathematics (IAM)
Neubr¨uckstrasse 10, CH-3012 Bern, Switzerland
{varga,bunke}@iam.unibe.ch
Summary. In this chapter, the use of synthetic training data for handwriting recog-
nition is studied. After an overview of the previous works related to the field, the
authors’ main results regarding this research area are presented and discussed, in-
cluding a perturbation model for the generation of synthetic text lines from existing
cursively handwritten lines of text produced by human writers. The goal of synthetic
text line generation is to improve the performance of an off-line cursive handwriting
recognition system by providing it with additional training data. It can be expected
that by adding synthetic training data the variability of the training set improves,
which leads to a higher recognition rate. On the other hand, synthetic training data
may bias a recognizer towards unnatural handwriting styles, which could lead to a
deterioration of the recognition rate. The proposed perturbation model is evaluated
under several experimental conditions, and it is shown that significant improvement
of the recognition performance is possible even when the original training set is large
and the text lines are provided by a large number of different writers.
1 Introduction
The problem of automatic recognition of scanned handwritten documents is of
great significance in numerous scientific, business, industrial, and personal ap-
plications that require the reading and processing of human written texts. The
ultimate goal is that computers approach, or even surpass, the text recognition
performance of humans. Despite the enormous amount of research activities
that already have been carried out in the past decades to study this problem,
it is considered very difficult and still not satisfactorily solved [1, 2]. Today’s
commercial systems work in areas where strict task specific knowledge and
constraints are available, such as postal address reading [3], and the process-
ing of bank checks [4] and forms [5, 6]. On the other hand, the more challenging
task of recognizing unconstrained handwriting has also many potential appli-
cations, for example, office automation, digital libraries, and personal digital
T. Varga and H. Bunke: Perturbation Models for Generating Synthetic Training Data in Hand-
writing Recognition, Studies in Computational Intelligence (SCI) 90, 333–360 (2008)
www.springerlink.com
c
Springer-Verlag Berlin Heidelberg 2008
334 T. Varga and H. Bunke
assisting devices. In this chapter the problem of unconstrained recognition is
addressed.
Despite the existence of the numerous elaborated and mature handwriting
recognitiontechniques[7,8,9,10,11,12], machines’ reading performance is
still considerably lower than that of humans. This inspired researchers to focus
not only on the development of novel recognition algorithms, but also on the
improvement of other aspects of handwriting recognition systems. These ef-
forts include multiple classifier combination [13, 14, 15], the better utilization
of the available a-priori, e.g. linguistic knowledge [16, 17], as well as the col-
lection of large, publicly available datasets of human written texts [18, 19, 20],
which enables better training of the recognizers and also an objective com-
parison of their performances.
As an alternative, to overcome the difficulties and inherent limitations
of collecting a large number of human written samples, the present chapter
investigates the generation and use of synthetic training data for off-line cur-
sive handwriting recognition. It has been shown in many works before that
the size and quality of the training data has a great impact on the perfor-
mance of handwriting recognition systems. A general observation is that the
more texts are used for training, the better recognition performance can be
achieved [21, 22, 23, 24].
In this work it is examined whether this observation holds if the training
set is augmented by synthetically generated texts. The motivation is that aug-
menting the training set by computer generated text samples is much faster
and cheaper than collecting additional human written samples. To achieve our
goal, a perturbation model is presented to generate synthetic text lines from
existing cursively handwritten lines of text produced by human writers. Our
purpose is to add synthetic data to the natural training data, rendered by hu-
man writers, so as to enlarge the training set. The basic idea of the approach
is to use continuous nonlinear functions that control a class of geometrical
transformations applied on the existing handwritten texts. The functions en-
sure that the distortions performed are not reversed by standard preprocessing
operations of handwriting recognition systems. Besides the geometrical dis-
tortions, thinning and thickening operations are also part of the model.
A closer examination reveals, however, that the use of synthetic training
data does not necessarily lead to an improvement of the recognition rate, be-
cause of two adversarial effects. First, it can be expected that the variability
of the training set improves, which potentially leads to a higher recognition
rate. On the other hand, synthetic training data may bias a recognizer to-
wards unnatural handwriting styles, which can lead to a deterioration of the
recognition rate, particularly if natural handwriting is used for testing.
The aim in this chapter is to find configurations of our recognizer and
the synthetic handwriting generation process, by which the recognition per-
formance can be significantly improved. The parameters examined include
the number of Gaussian mixture components in the recognizer used for dis-
tribution estimation, distortion strength, training set size, and the number
Synthetic Training Data in Handwriting Recognition 335
of writers in the training set. It is shown that significant improvement of the
recognition performance is possible even when the original training set is large
and the text lines are provided by many different writers. But to really achieve
an improvement in this case, one has also to consider the capacity of the recog-
nition system, which needs to be appropriately adjusted when expanding the
training set with synthetic text lines. Parts of this work have been published
in [25, 26]. The current chapter provides a synoptic presentation and overview
of the authors’ previous work on synthetic text line generation for the training
of handwriting recognition systems.
The chapter is organized as follows. In Section 2, an overview of the related
previous works on synthetic text generation is given. Section 3 introduces our
perturbation model, while in Section 4 a concise description of the off-line
handwriting recognition system used for the experiments is given. Experi-
mental results are presented in Section 5. Finally, Section 6 provides some
conclusions and suggestions for future work.
2 Synthetically Generated Text
The concept of synthetic text relates to both machine printed and handwritten
documents. Synthesizing text means that real-world processes that affect the
final appearance of a text are simulated by a computer program. For example,
in the case of machine printed documents the printing and scanning defects,
while in the case of handwriting the different writing instruments or the whole
writing process can be modeled and simulated by computer.
Synthetic texts can be generated in numerous ways, and they have
widespread use in the field of document analysis and recognition. In the fol-
lowing, a brief overview is given. Approaches for both machine printed and
handwritten synthetic text generation are presented, since they often have
similar aims, and thus the findings and developments of one field can also
affect and stimulate the other one and vice versa.
2.1 Improving and Evaluating Recognition Systems
The two main difficulties that contemporary text recognizers have to face are
the degraded quality of document images as well as the great variation of
the possible text styles [27, 28, 29]. The quality of document images usually
degrades to various extent during printing, scanning, photocopying, and fax-
ing. Style variation means that either different fonts might be used (machine
printed text), or many individual writing styles can occur (handwritten text).
One way to alleviate the above mentioned problems is to train the recog-
nizers using sets of text samples that are more representative to the specific
recognition task under consideration. This idea is supported by two facts. First
of all, every recognizer needs to be trained, i.e. it has to learn how the differ-
ent characters and/or words may look like. Furthermore, in the past decade
336 T. Varga and H. Bunke
researchers in the field of image pattern recognition realized that any further
improvement of recognition performance depends as much on the size and
quality of the training data as on the underlying features and classification
algorithms used [30]. As a rule of thumb says, the classifier that is trained on
the most data wins.
A straightforward way to improve the training set is to collect more real-
world text samples [18, 19, 20]. The effectiveness of this approach has been
experimentally justified by numerous works in the literature, yielding higher
recognition performance for increased training set sizes [21, 22, 23, 24]. Un-
fortunately, collecting real-world samples is a rather expensive and time con-
suming procedure, and truthing the collected data is error-prone [31, 32]. A
possible solution to these drawbacks is to create text image databases au-
tomatically by generating synthetic data, which is cheap, fast, and far less
error-prone. Furthermore, it enables the generation of much larger databases
than those acquired by the conventional method. The main weakness of the
synthetic approach is that the generated data may not be as representative
as real-world data.
In machine printed OCR (Optical Character Recognition), especially when
the possible fonts are a-priori known, the concept of representativeness of
the training set can be approached from the side of document degradation.
In [33, 34, 35], defects caused by the use of printing and imaging devices are
explicitly modeled and applied to ideal input images (e.g. Postscript docu-
ment) to generate realistic image populations. Such synthetic data can then
be used to build huge and more representative training sets for document im-
age recognition systems [36, 37, 38]. The ability of controlling the degree of
degradation makes it also possible to carry out systematic design and evalu-
ation of OCR systems [36, 39, 40, 41].
For handwriting recognition, no parameterized model of real-world image
populations is available, due to the lack of mathematical models accounting for
the enormous variations present in human handwriting. Nevertheless, several
attempts to generate synthetic data for handwriting recognition systems are
reported.
In [42], human written character tuples are used to build up synthetic text
pages. Other approaches apply random perturbations on human written char-
acters [21, 43, 44, 45, 46], or words [47, 48]. In [49], realistic off-line characters
are generated from on-line patterns using different painting modes.
Generating synthetic handwriting does not necessarily require to use hu-
man written texts as a basis. In [50] and [51], characters are generated by
perturbation of the structural description of character prototypes.
Those works where the application of synthetic training data yielded im-
proved recognition performance over natural training data are mainly related
to the field of isolated character recognition [21, 43, 45, 46]. The natural train-
ing set was augmented by perturbed versions of human written samples, and
the larger training set enabled better training of the recognizer. However, to
the knowledge of the authors, for the problem of general, cursive handwritten
Synthetic Training Data in Handwriting Recognition 337
word and text line recognition, no similar results besides those of the authors
(see e.g. [25, 26]) involving synthetically generated text images have been
reported.
Finally, perturbation approaches can also be applied in the recognition
phase, making the recognizer insensitive to small transformations or distor-
tions of the image to be recognized [44, 47, 52].
2.2 Handwritten Notes and Communications
The use of handwriting has the ability to make a message or a letter look
more natural and personal. One way to facilitate the input of such messages
for electronic communication is to design methods that are able to generate
handwriting-style texts, particularly in the style of a specific person.
Such methods have several possible applications. For example, using a
word processor, editable handwritten messages could be inputted much faster
directly from the keyboard. For pen-based computers, errors made by the user
could be corrected automatically by substituting the erroneous part of text
by its corrected version, using the same writing style.
In [53], texts showing a person’s handwriting style are synthesized from
a set of tuples of letters, collected previously from that person, by simply
concatenating an appropriate series of static images of tuples together.
Learning-based approaches are presented in [54], [55], and [56], to generate
Hangul characters, handwritten numerals, and cursive text, respectively, of a
specific person’s handwriting style. These methods need temporal (on-line)
information to create a stochastic model of an individual style.
A method that is based on character prototypes instead of human writ-
ten samples is presented in [57]. Korean characters are synthesized using
templates of ideal characters, and a motor model of handwriting generation
(see [58]) adapted to the characteristics of Korean script. The templates con-
sist of strokes of predefined writing order. After the geometrical perturbation
of a template, beta curvilinear velocity and pen-lifting profiles are generated
for the strokes, which are overlapped in time. Finally, the character is drawn
using the generated velocity and pen-lifting profiles.
One possible application of the method is to build handwriting-style fonts
for word processors. On the other hand, the method can provide training data
for handwriting recognizers. Although the generated characters look natural
and represent various styles, they were not used for training purposes.
2.3 Reading-Based CAPTCHAs
At present, there is a clear gap between the reading abilities of humans and
machines. Particularly, humans are remarkably good at reading seriously de-
graded (e.g. deformed, occluded, or noisy) images of text, while modern OCR
systems usually fail when facing such an image [59].