Sha W., Malinov S. Titanium Alloys: Modelling of Microstructure, Properties and Applications
Подождите немного. Документ загружается.

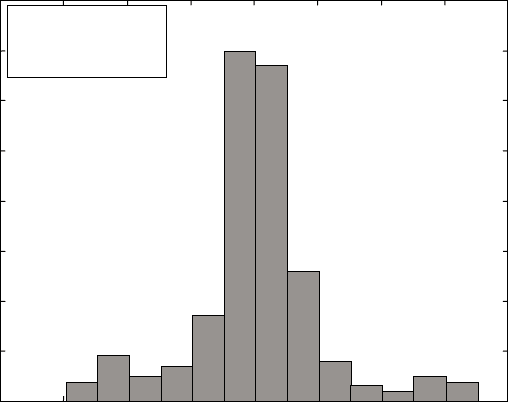
Neural network models and applications in property studies 391
15.2.3 Calculations and comparison with
experimental data
Using the trained neural network, a model for simulation of the fatigue stress
life of Ti-6Al-4V was created. This model can be used to predict fatigue
curve diagrams.
Firstly, some fatigue stress diagrams for Ti-6Al-4V are calculated, to
examine how effective the prediction can be (Fig. 15.15). Both the predicted
NN and experimental curves are plotted within a maximum and minimum
stress amplitude range of ±50 MPa, in order to visualise how exact the
fatigue stress curve predictions are. The figure of ±50 MPa is chosen as the
average deviation from the fatigue curve based on the experimental results.
Generally, for the predicted curves, a good agreement is seen when compared
with the experimental data. The accuracy of the neural network predictions
is higher for certain cases compared with others, because more experimental
data are available for some conditions. However, the accuracy of the neural
network predictions is within an acceptable error range in all cases.
To further show the effectiveness of the neural network at predicting
fatigue stress curves for Ti-6Al-4V, different input values are used, modelled
and thereafter analysed.
The influence of microstructure as an input on the fatigue stress curves of
Ti-6Al-4V is modelled (Fig. 15.16a). Fatigue stress diagrams are computed
–40 –30 –20 –10 0 10 20 30 40
Error (%)
Mean = 1.6
StDev = 13.2
Number
80
70
60
50
40
30
20
10
0
15.14
Statistical analysis of the error of the neural network
predictions for fatigue stress life.
Titanium alloys: modelling of microstructure392
Stress amplitude (MPa)
1000
900
800
700
600
500
400
NN
NN (max)
NN (min)
Exp
Exp (max)
Exp (min)
10
4
10
6
10
8
Cycles to failure
(a)
Stress amplitude (MPa)
1000
900
800
700
600
500
400
10
4
10
6
10
8
Cycles to failure
(b)
Stress amplitude (MPa)
1000
900
800
700
600
500
400
10
4
10
6
10
8
Cycles to failure
(c)
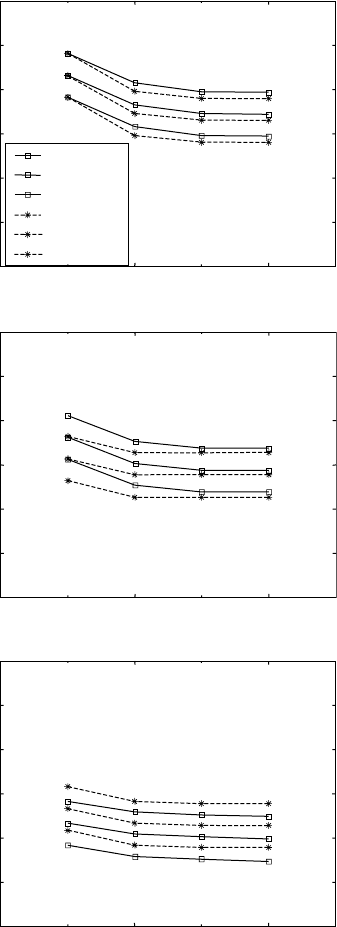
15.15
Comparison of experimental S-N diagrams with neural network
predictions for different conditions: (a) fine equiaxed, air, B, 20 °C,
SP,
R
= –1; (b) bimodal, air, B, 200 °C, EP,
R
= –1; (c) fine lamellar,
3.5% NaCl, T-RD, 20 °C, EP,
R
= –1; (d) coarse equiaxed, vacuum, B,
20 °C, EP,
R
= –1.
Neural network models and applications in property studies 393
for fine lamellar and coarse lamellar structures, while the other inputs remain
constant. The diagram shows that fine lamellar has the greater fatigue stress
level. From a metallurgical perspective, it is of no surprise that good fatigue
strength involves structures which have finer grain sizes, e.g. fine lamellar.
Incidentally, the result for fine lamellar should be more accurate compared
with the results for coarse lamellar, as more data are available for this
microstructure.
For Ti-6Al-4V alloy, the influence of the environment is also modelled
(Fig. 15.16b). All other inputs remain constant throughout. Comparing the
three environments (vacuum, air, and 3.5%NaCl), it is evident that the fatigue
strength is the greatest for the vacuum input. Laboratory air and NaCl solution
are aggressive environments, which can harbour impurities. From the
metallurgical viewpoint, the vacuum environment is the purest of the three
environments, and therefore should give higher fatigue strength as shown by
the neural network results.
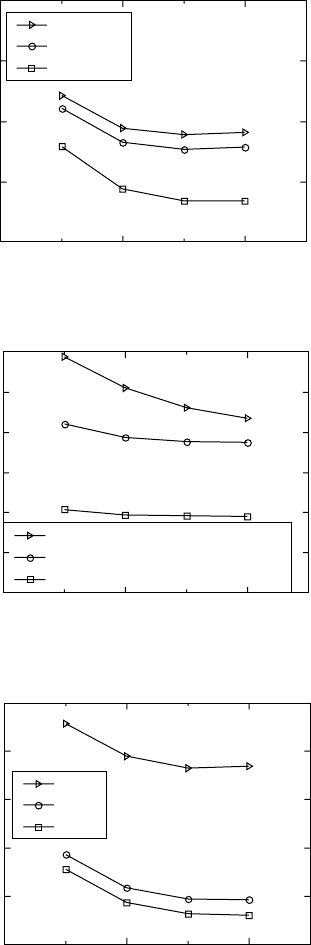
The influence of texture is shown in Fig. 15.16c for two cases, basal
texture and basal transverse texture tested in a rolling direction. Texture is an
important parameter for fatigue stress curves.
Temperature influence is very important. The diagram in Fig. 15.16d
shows that, at 20 °C (room temperature), the alloy has the greatest fatigue
stress life. The other two temperatures of 150 and 400 °C are not included in
the training data set, but the neural network is capable of estimating the
fatigue curves for these inputs.
The influence of surface treatment appears to be the most significant on
the fatigue curves (Fig. 15.16e), and it seems to be more complicated than
other factors. However, the neural network is able to predict the curves using
the known data set.
Stress amplitude (MPa)
1000
900
800
700
600
500
400
10
4
10
6
10
8
Cycles to failure
(d)
15.15
Continued
Titanium alloys: modelling of microstructure394
Stress amplitude (MPa)
900
800
700
600
500
10
4
10
6
10
8
Cycles to failure
(a)
Fine lamellar
Coarse lamellar
Stress amplitude (MPa)
900
800
700
600
500
10
4
10
6
10
8
Cycles to failure
(b)
Vacuum
Air
3.5%NaCl
Stress amplitude (MPa)
900
800
700
600
500
10
4
10
6
10
8
Cycles to failure
(c)
B
B/T-RD
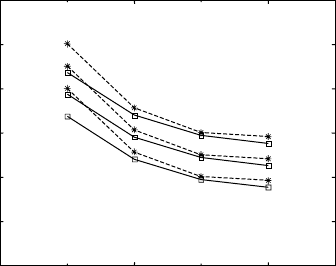
15.16
Simulation of S-N diagrams modelling the effect of input
parameters: (a) microstructure (vacuum, B/T-RD, 20 °C, EP,
R
= –1);
(b) environment (fine equiaxed, B/T-RD, 20 °C, EP,
R
= –1); (c) texture
(fine lamellar, air, 20 °C, EP,
R
= –1); (d) temperature (fine equiaxed,
air, no texture, EP,
R
= –1); (e) surface treatment (fine equiaxed, air, B,
20 °C,
R
= –1); (f) stress ratio (fine equiaxed, air, T-RD, 20 °C, SP).
Neural network models and applications in property studies 395
Stress amplitude (MPa)
900
800
700
600
500
10
4
10
6
10
8
Cycles to failure
(d)
20 °C
150 °C
400 °C
Stress amplitude (MPa)
1200
1000
800
600
400
200
0
10
4
10
6
10
8
Cycles to failure
(e)
Mechanical polishing (7 µm)
SP+EP
SP+SR
Stress amplitude (MPa)
1200
1100
1000
900
800
700
10
4
10
6
10
8
Cycles to failure
(f)
–1
–0.2
0.4
15.16
Continued
Titanium alloys: modelling of microstructure396
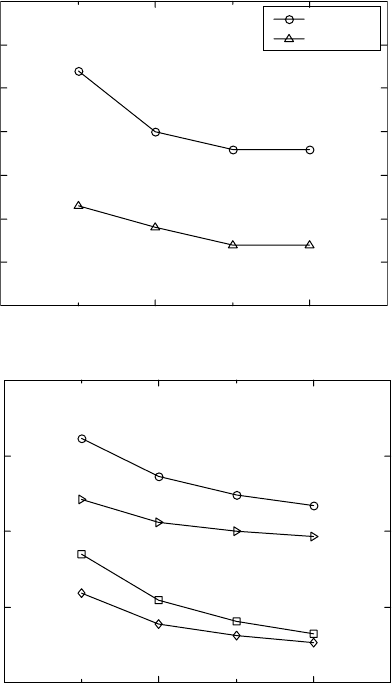
The stress ratio (R) influence is modelled for increasing stress ratios
within the data set range of –1 to 0.54 (Fig. 15.16f). The model confirms
that, with increasing stress ratio, the fatigue S-N curve moves downwards. It
shows that, under a stress ratio of –1, the alloy has the greatest fatigue stress
life. It may be noted that most data in the data set have this stress ratio. The
other two curves for stress ratios of –0.2 and 0.4 are not used in the data set.
These two curves are close to each other, much below the curve for R = –1.
A clear tendency of decreasing S-N curve with increasing stress ratio is
shown.
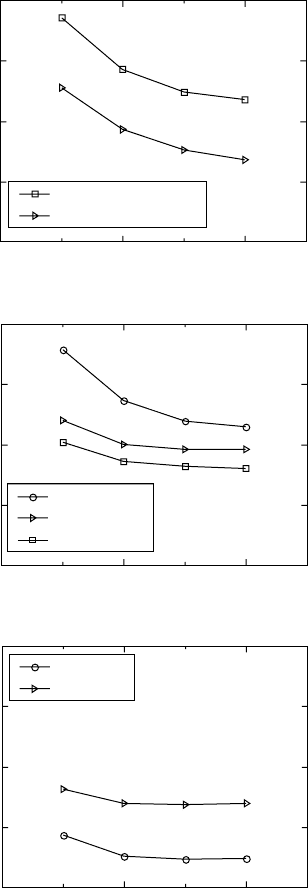
The model can also be used to simulate fatigue stress life diagrams for
new conditions for which S-N diagrams are not available in the literature.
Here, we use the model to simulate S-N diagrams for Ti 6-4 alloy at different
microstructure conditions and temperatures (Fig. 15.17). The neural network
model predicts that the coarser microstructure and the higher temperature
lead to lower fatigue strength. In a similar way, the model can be used to
quantitatively simulate the S-N diagrams at various combinations of
microstructure, surface, temperature and environment conditions.
15.2.4 Graphical user interface
Based on the designed model of the artificial neural network, a graphical
user interface (GUI) is created for easy use of the model (Fig. 13.2c). On
input of the six parameters, the S-N diagram is simulated and plotted. In this
way, the user can easily obtain a fatigue stress life diagram for Ti-6Al-4V.
The GUI also allows comparison of two or more diagrams by plotting them
together.
15.2.5 Summary
An artificial neural network has been created to predict the fatigue stress S-
N diagrams for the Ti-6Al-4V alloy. The model has been used to study six
conditions which influence the S-N curves, viz. microstructure, environment,
texture, test/work temperature, surface treatment, and stress ratio. A graphical
user interface has been created for use with the model. The program and the
model can be used for:
• simulating S-N curves for the Ti-6Al-4V alloy as a function of the input
conditions;
• investigating the influence of different factors affecting the fatigue of
Ti-6Al-4V;
• reducing the amount of experimental work for measuring Ti-6Al-4V S-
N fatigue strength.
Neural network models and applications in property studies 397
15.3 Mechanical properties of gamma-based
titanium aluminides
The objective of this section is to demonstrate a computer program to accurately
predict the tensile properties of gamma-based titanium aluminides at various
working temperatures as functions of alloy composition and strain rate. Since
Stress amplitude (MPa)
800
750
700
650
600
550
500
450
10
4
10
6
10
8
Cycles to failure
(a)
20 °C
400 °C
Stress amplitude (MPa)
800
700
600
500
400
10
4
10
6
10
8
Cycles to failure
(b)
Fine lamellar
Coarse lamellar
Fine lamellar
Coarse lamellar
20 °C
380 °C
15.17
Neural network simulations of fatigue stress life S-N diagrams
for Ti-6Al-4V alloy. (a) Different temperatures. Microstructure:
bimodal without texture; surface treatment: electrolytically polished;
environment: 3.5% NaCl; stress ratio: -1. (b) Different temperatures
and microstructures. Environment: 3.5% NaCl; surface treatment:
mechanically polished (7 µm); stress ratio: -1; texture: basal-
transverse texture; transverse test direction.
Titanium alloys: modelling of microstructure398
experimental data has shown there to be no simple relationship between the
tensile properties, alloy composition and microstructure, an artificial neural
network (ANN) model is used to accurately predict these properties.
A successful and user-friendly system should reduce the need for room-
and elevated temperature testing, thus reducing the cost of employing these
materials. This could lead to an increased use of the materials within industry,
although the challenge brought by the alloy ductility will remain the governing
factor in their future application. This will have to be addressed by metallurgists
if the alloy is to achieve the widespread use currently monopolised by
conventional superalloys.
15.3.1 Model generation and description
Model overview
The input parameters of the model are alloy composition, microstructure and
work (test) temperature. The composition includes the most commonly used
alloying elements in γ titanium aluminide alloys: Al, Cr, Nb, V, Mn and C,
and is presented by the amounts of the alloying elements. The microstructure
of the alloy is taken into account, and is related to its thermomechanical
processing (TMP) conditions. The test temperature is included since gamma-
based titanium alloys will be used in elevated temperature environments.
The outputs of the neural network model are the most important tensile
mechanical properties: ultimate strength, elongation, reduction of area, and
elastic modulus. A further input of strain rate (in s
–1
) is required for the
outputs of reduction of area. A most general schematic diagram of the network
model is shown in Fig. 13.1d.
Principles of the model
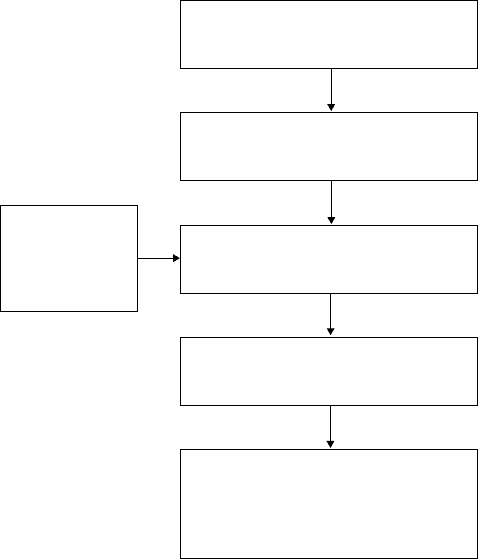
The process of neural network modelling starts with the collection of data
from external sources. These data are stored on a database, and used to
decide the number and type of the input and output parameters. The data
may need to be pre-processed in order to obtain a usable form for the network
to read. A program to set up the neural network is then created, which then
is trained using the stored database. The training process has many sub-
processes. These are based on the availability of data and the reliability of
output. This process is summarised in Fig. 15.18.
Input parameters
In order to train the network sufficiently, large arrays of input and output
data pairs are used for each output parameter. These input and output arrays
Neural network models and applications in property studies 399
were taken from a master database, which was developed using available
literature on the alloy types (Winstone, 2001). Table 15.5 gives the number
of input/output data pairs for different gamma titanium aluminides collated
from various sources. The selection of the input parameters is based on the
planned model structure, with all relevant parameters represented as input
data of the network. In order to reduce the training times, it is good practice
to remove any input parameters from the training input layer that are constant
throughout the data set. The following input parameters are used.
Alloy composition
Analysis of initial data led to the selection of six alloying elements: Al, Cr,
V, Mn, Nb and C. The Rolls Royce XD type alloys were not used due to their
specialist application. The use of carbon is widely documented in sources,
and so was included in the model. The oxygen level in the alloys was mostly
unknown and so was not included.
Master database containing all the
data for each input and output
Sub-spreadsheets for each
individual output
MatLab files
created for the
training of each
individual neural
network
Matrices in sub-spreadsheets copied-
and-pasted into a notepad file for
each output
Individual neural networks trained to
best possible accuracy, resulting data
files saved for each output
Master model file created using
MatLab to read in the output mat
files from the training, and predict
the outputs. Model runs from a
central graphical user interface
(GUI) for user control
15.18
Steps in creating the gamma-based titanium aluminides’
mechanical properties model.

Titanium alloys: modelling of microstructure400
Table 15.5
Analysis of input and output data for the titanium aluminides model
Output Number Minimum Maximum Mean Standard Alloying Microstructure Temperature Strain rate
of data value value deviation elements (for codes refer range (°C) range (s
–1
)
to Table 15.6)
Elastic modulus 73 91 177 151 17 Al, V, C All 0 (unknown) 25–1000 N/A
(GPa)
Ultimate 185 37 1287 335 192 All No 5 18–1200 N/A
strength (MPa)
Elongation (%) 142 0 99 17 25 All All 15–1012 N/A
Reduction in 81 0 73 34 22 Al, Cr, Nb Only 9 and 10 977–1200 0.0005–0.01
area (%)