Таненбаум Э. Распределенные системы. Принципы и парадигмы
Подождите немного. Документ загружается.


6.3. Модели непротиворечивости, ориентированные на клиента 361
рая операция записи, имеет то же самое или более позднее значение, чем полу-
ченное во время завершения операции W(x\) в 11
Отметим, что по определению непротиворечивости монотонной записи опе-
рации записи одного процесса выполняются в том же порядке, в котором они
были инициированы. В ослабленной форме непротиворечивости монотонного
чтения эффект операций чтения наблюдается только в том случае, если все пред-
шествующие операции чтения уже завершились, но не обязательно в том поряд-
ке,
в котором они начинались. Такая непротиворечивость применяется в тех слу-
чаях, когда операции записи коммутативны, то есть их упорядоченность на
самом деле не является необходимой. Детали можно найти в
[453].
6.3.4.
Чтение собственных записей
Существует и еще одна модель непротиворечивости, ориентированная на клиен-
та, весьма схожая с непротиворечивостью монотонной записи. Хранилище дан-
ных обладает свойством непротиворечивости чтения собственных записей
(read-
your-writes
consistency),
если оно удовлетворяет следующему
условию:
результат
операций
записи
процесса
в
элемент данных
х
всегда виден последующим
операци-
ям чтения х
этого же
процесса.
Другими словами, операция записи всегда завершается раньше следующей
операции чтения того же процесса, где бы ни происходила эта операция чтения.
Отсутствие непротиворечивости чтения собственных записей часто обнару-
живается при обновлении web-страниц с последующим просмотром результатов.
Операции обновления часто производятся при помощи стандартного или друго-
го текстового редактора, который записывает новую версию в совместно исполь-
зуемую файловую систему web-сервера. Web-браузер пользователя работает с
тем же самым файлом, возможно, запрашивая его с локального web-сервера. Од-
нако после первой же загрузки этого файла сервер или браузер кэшируют для
последующего доступа его локальную копию. Соответственно, если браузер или
сервер возвращает кэшированную копию, а не оригинальный файл, то при об-
новлении web-страницы пользователь не в состоянии увидеть его результат. Не-
противоречивость чтения собственных записей может гарантировать, что если
редактор и браузер интегрированы в единую программу, то при обновлении
страницы кэш объявляется неактуальным, и в результате загружается и отобра-
жается новая версия файла.
Тот же эффект проявляется и при изменении паролей. Так, например, для
входа в цифровую библиотеку в Web часто необходимо иметь там учетную за-
пись с соответствующим паролем. Однако при смене пароля для вступления но-
вого пароля в силу может потребоваться несколько минут. В результате эти не-
сколько минут библиотека будет недоступна для пользователей. Задержка
может возникнуть из-за того, что для работы с паролями используется отдель-
ный сервер и последующая рассылка пароля (зашифрованного) серверам, на ко-
торых находится библиотека, может потребовать времени. Эта проблема уже
встречалась в Grapevine, одной из первых распределенных систем, поддерживав-
ших причинно-следственную связь. Помогла решить эту. проблему реализация
непротиворечивости чтения собственных записей [61].

362 Глава 6. Непротиворечивость и репликация
На рис. 6.16,
а
показано хранилище данных
с
непротиворечивостью чтения
собственных записей. Отметим, что этот рисунок очень похож
на
рис. 6.14, а,
за
исключением того,
что
непротиворечивость теперь определяется
по
последней
операции записи процесса Р,
а не по
последней операции чтения.
L1:
W(x^) L1: W(Xi)
L2:
WS(Xi;x2) RCXj)
L2:
WS(X2)
R(X2)
Рис. 6.16. Хранилище данных
с
непротиворечивостью чтения собственных записей
(а).
Хранилище данных без непротиворечивости чтения собственных записей
(б)
На рис. 6.16,
а
процесс
Р
выполняет операцию записи W{x\),
а
затем опера-
цию чтения другой локальной копии. Непротиворечивость чтения собственных
записей гарантирует,
что
эффект, произведенный операцией записи, будет
на-
блюдаться
при
последующей операции чтения.
На это
указывает операция
WS{x\\X2),
означающая, что W{x\) является частью операции W5(x2).
В
противо-
положность этому,
на
рис. 6.16,
б
операция
W{X])
остается вне операции WS{x2),
указывая
на
то, что эффект предыдущей операции записи процесса
Р
не распро-
страняется
на
копию 12.
6.3.5. Запись
за
чтением
Последняя модель непротиворечивости, ориентированная
на
клиента,
—
это мо-
дель,
в
которой изменения распространяются как результаты предыдущей опера-
ции чтения.
В
этом случае говорят, что хранилище данных обеспечивает непро-
тиворечивость записи
за
чтением (writes-follow-reads
consistency),
если соблюдает-
ся следующее условие: операция записи в
элемент данных
х
процесса,
следующая
за операцией чтения
х
того же
процесса,
гарантирует,
что будет выполняться
гшд тем же самым
или
более свежим значением
х,
которое было прочитано
преды-
дущей операцией.
Иными словами, любая последующая операция записи
в
элемент данных
х,
производимая процессом, будет осуществляться
с
копией
х,
которая имеет
по-
следнее считанное тем
же
процессом значение
х.
Непротиворечивость записи
за
чтением позволяет гарантировать, что пользо-
ватели сетевой группы новостей увидят письма
с
ответами
на
некое письмо
только позже оригинального письма
[453].
Поясним проблему. Представьте себе,
что пользователь сначала читает письмо А. Затем
он
реагирует
на
него, посылая
письмо
В.
Согласно требованию непротиворечивости записи
за
чтением, пись-
мо В будет разослано
во
все копии группы новостей только после того,
как
туда
будет послано письмо А. Отметим, что пользователи, которые только читают пись-
ма,
не
нуждаются
в
какой-либо особой модели непротиворечивости, ориентиро-
ванной
на
клиента. Непротиворечивость записи после чтения обеспечит сохра-
нение
в
локальной копии ответа
на
письмо только
в том
случае, если
там уже
наличествует оригинал.

6.3. Модели непротиворечивости, ориентированные на клиента 363
Эту модель непротиворечивости иллюстрирует рис. 6.17. На рис. 6.17, а про-
цесс читает элемент х из локальной копии L1, Операции записи, заменяющие
прочитанное значение, присутствуют в наборе операций записи в L2, которые
позже осуществляет этот процесс (отметим, что другие процессы в L2 также на-
блюдают эти операции записи). В противоположность этому, как показано на
рис.
6.17, б
у
отсутствуют всякие гарантии того, что операция записи в L2 выпол-
няется над копией, которая не противоречит копии, только что считанной из L1.
L1:
WS(x^) R(x^) L1: WSCx,) R{x^)
L2:
WS(Xi;x2) W(X2) L2: WS(X2) W(X2)
Рис.
6.17. Хранилище данных с непротиворечивостью записи после чтения
(а).
Хранилище данных без непротиворечивости записи после чтения (б)
6.3.6. Реализация
Реализация непротиворечивости, ориентированной на клиента, относительно про-
ста, если не принимать во внимание вопросы производительности. Далее мы сна-
чала опишем именно такую реализацию, после чего поговорим о более «жизнен-
ных» вариантах реализации.
Примитивная реализация
в примитивной реализации непротиворечивости, ориентированной на клиента,
каждой операции записи приписывается глобально уникальный идентификатор.
Это делается тем сервером, который первым выполняет операцию. Мы говорим
также, что операция инициируется этим сервером. Отметим, что генерация гло-
бально уникальных идентифргкаторов может быть реализована в виде локальной
операции (см. задания в конце главы 4). Итак, для каждого клиента мы отслежи-
ваем два набора идентификаторов записи. Набор чтения для клиента состоит из
идентификаторов записи, соответствующих операциям чтения, выполненным
клиентом. Аналогично, набор записи состоит из идентификаторов операций за-
писи, выполненных клиентом.
Непротиворечивость монотонного чтения реализуется следующим образом.
Когда клиент осуществляет операцию чтения с сервера, этот сервер проверяет
набор чтения клиента на локальное присутствие результатов всех его операций
записи (размер этого набора может породить проблемы производительности, ре-
шение которых обсуждается ниже). Если это не так, он связывается с другими
серверами, чтобы актуализировать данные до проведения операции чтения.
С
дру-
гой стороны, операции чтения могут быть переданы серверу, на котором произ-
водились операции записи. После выполнения операции чтения последующие
операции записи, производимые на выбранном сервере и связанные с операция-
ми чтения, добавляются к набору чтения клиента.
Отметим, что точно можно определить лишь место, где происходят операции
записи, указанные в наборе чтения. Так, например, идентификатор записи может

364 Глава 6. Непротиворечивость и репликация
включать в себя идентификатор сервера, инициировавшего операцию. Этот сер-
вер требуется, например, для того, чтобы запротоколировать операцию записи в
журнале, чтобы ее можно было повторить на другом сервере. Кроме того, опера-
ции записи должны осуществляться в том же порядке, в котором они были ини-
циированы. Упорядоченность введена для того, чтобы клиент мог генерировать
глобально уникальный последовательный номер, включаемый в идентификатор
записи, такой, например, как отметка времени Лампорта. Если каждый элемент
данных модифицируется только его владельцем, последний и сможет поддержи-
вать последовательную нумерацию.
Непротиворечивость монотонной записи реализуется аналогично монотонно-
му чтению. Всякий раз при инициировании клиентом новой операции записи на
сервере этот сервер просматривает набор записи клиента. (И снова, размер этого
набора может быть слишком велик для существующих требований по произво-
дительности. Альтернативные решения будут изложены ниже.) Сервер удосто-
веряется, что указанные операции записи выполнялись первыми и в правильном
порядке. После выполнения новой операции идентификатор записи этой опера-
ции добавляется к набору записи. Отметим, что актуализация набора записи те-
кущего сервера при помощи набора записи клиента может существенно увели-
чить время отклика сервера.
Непротиворечивость чтения собственных записей также требует, чтобы сер-
вер,
на котором выполняются операции чтения, имел доступ ко всем операциям
записи из набора записи клиента. Операции записи можно просто извлекать с
других серверов перед выполнением операции чтения, даже если это грозит
обернуться проблемами с временем отклика. С другой стороны, клиентское про-
граммное обеспечение может само найти сервер, на котором операции записи,
указанные в наборе записи клиента, уже выполнены.
И, наконец, непротиворечивость записи за чтением может быть реализована
следующим образом. Сначала выбранный сервер актуализируется с помощью
операций записи, входящих в набор чтения клиента, а затем в набор записи до-
бавляются идентификатор операции записи и идентификаторы из набора чтения
(таким образом, учитывается только что выполненная операция записи).
Повышение производительности
Легко заметить, что наборы чтения и записи, ассоциированные с каждым клиен-
том, могут стать чересчур большими. Чтобы сохранить управляемость этих набо-
ров,
операции чтения и записи клиента могут группироваться в сеансы. Сеансы
обычно ассоциируются с приложениями: они открываются при запуске приложе-
ния и закрываются по окончании работы с ним. Однако сеансы также могут ассо-
циироваться и с временно запускаемыми приложениями, такими как пользова-
тельский агент для электронной почты. В любом случае, когда клиент закрывает
сеанс, наборы очищаются. Разумеется, если клиент откроет сеанс и никогда его
не закроет, ассоциированные с ним наборы чтения и записи могут стать очень
большими.
Основная проблема примитивной реализации вытекает из способа представ-
ления наборов чтения и записи. Каждый из наборов включает в себя множество

6.4. Протоколы распределения 365
идентификаторов операций записи. Когда клиент передает серверу запрос на за-
пись или чтение, серверу передается и набор идентификаторов
—
для проверки
того факта, что все операции записи соответствуют обрабатываемому на сервере
запросу.
Эту информацию удобнее представлять в виде векторных отметок времени
следующим образом. Сначала когда сервер принимает требование на проведение
новой операции записи W, он описанным выше способом присваивает этой опе-
рации глобально уникальный идентификатор WID вместе с отметкой времени
ts(WID),
Следующая операция записи на этом сервере получает отметку времени
с большим значением. Каждый сервер 5, поддерживает векторную отметку вре-
мени RCVD(i), где RCVD(i)[j] соответствует отметке времени последней опера-
ции записи, инициированной на сервере 5,, которая была получена (и обработа-
на) сервером Sj.
Когда клиент посылает запрос на выполнение операции записи или чтения на
определенный сервер, сервер возвращает свою текущую отметку времени вместе
с результатом этой операции. Наборы чтения и записи представляются последо-
вательными векторными отметками времени. Для любого такого набора Л мы
создаем векторную отметку времени VT(A) с набором УГ(Л)[2], равным отметке
времени, максимальной среди всех операций Л, инициированных на сервере 5„
что приводит к эффективному представлению этих наборов.
Объединение двух наборов идентификаторов,
Л
и Б, обозначается в виде вектор-
ной отметки времени VT(A +Л), где VT[A
-^ B)[i]
равно max(VT(A)[i], VT(B)[i]).
К тому же, чтобы выяснить, содержится ли набор идентификаторов А в другом
наборе В, нам нужно проверить только, выполняется ли для каждого индекса i
условие VT(A)[i]..,VT(B)[i].
Когда сервер возвращает клиенту свою текущую отметку времени, клиент
приводит в соответствие с ней векторную отметку времени своего собственного
набора чтения или записи (в зависимости от выполняемой операции). Рассмот-
рим вариант с непротиворечивостью монотонного чтения, при которой клиенту
с сервера 5 возвращается векторная отметка времени. Если векторная отметка
набора чтения клиента
—
VT(Rset), то для каждого индекса j значение VT(Rset)[j]
равно max{VT(Rset)[j], RCVD(i)[j]}. Набор чтения клиента отражает последнюю
известную ему операцию записи. Соответствующая векторная отметка времени
будет послана (возможно, на другой сервер) в ходе следующей операции чтения
клиента.
6.4. Протоколы распределения
До сих пор мы рассуждали лишь о тех или иных моделях непротиворечивости,
стараясь поменьше обращать внимания на их реализацию. В этом разделе мы об-
судим различные способы распространения, точнее способы распределения ад-
ресованных репликам обновлений независимо от поддерживаемой ими модели
непротиворечивости. Протоколы для конкретных моделей непротиворечивости
мы рассмотрим в следующем разделе.

366 Глава
6.
Непротиворечивость и репликация
6.4.1.
Размещение реплик
Основную проблему проектирования распределенных хранилищ данных, кото-
рую мы должны решить,
—
это когда, где и кому размещать копии хранилища (см.
также [233]). Различают три различных типа КОПРШ, логически организованных
так, как показано на рис. 6.18.
—•
Репликация,
инициируемая сервером
---•
Репликация,
инициируемая клиентом
Рис.
6.18. Логическая организация различных типов копий
хранилищ
данных
в
виде трех концентрических колец
Постоянные реплики
Постоянные реплики можно рассматривать как исходный набор реплик, обра-
зующих распределенное хранилище данных. Во многих случаях число постоян-
ных реплик невелико. Рассмотрим, например, web-сайт. Распределение web-сайтов
обычно происходит в одном из двух вариантов. В первом варианте распределения
файлы, которые составляют сайт, реплицируются на ограниченном числе серве-
ров одной локальной сети. Когда приходит запрос, он передается одному из сер-
веров, например, с использованием стратегии обхода кольца [96].
Второй тип распределения web-сайтов
—
это создание зеркал (mirroring).
В этом случае web-сайт копируется на ограниченное количество разбросанных
по всему Интернету серверов, называемых зеркальными сайтами
(mirror
sites),
или просто зеркалами. В большинстве случаев клиенты просто выбирают одно
из зеркал из предложенного им списка. Зеркальные web-сайты обычно основаны
на технологии кластерных web-сайтов, поддерживающих одну или несколько
реплик с возможностью в той или иной степени их статического конфигуриро-
вания.
Подобная же статическая организация применяется и для создания распреде-
ленных баз данных
[337].
Базы данных могут быть реплицированы и распределе-
ны по нескольким серверам, образующим вместе кластер рабочих
станций
(Clus-
ter Of
Workstations,
COW). О таких кластерах часто говорят как об архитектуре
без
разделения
(shared-nothing
architecture),
подчеркивая, что ни диски, ни опера-
тивная память не используются процессорами совместно. С другой стороны, ба-

6.4. Протоколы распределения 367
зы данных могут распределяться и возможно реплицироваться по множеству
географически разбросанных мест. Такая архитектура нередко применяется при
построении федеральных баз данных
[416].
Реплики,
инициируемые сервером
в противоположность постоянным репликам, реплики, инициируемые сервером,
являются копиями хранилища данных, которые создаются для повышения про-
изводительности и создание которых инициируется хранилищем данных (его
владельцем). Рассмотрим, например, web-сервер, находящийся в Нью-Йорке.
Обычно этот сервер в состоянии достаточно быстро обрабатывать входящие за-
просы, но может случиться так, что внезапно в течение нескольких дней из неизвест-
ного удаленного от сервера места портдет поток запросов. (Такой поток, как пока-
зывает короткая история Web, может быть вызван множеством причин.)
В
этом
случае может оказаться разумным создать в регионах несколько временных реп-
лик, призванных работать с приходящими запросами. Эти реплики известны так-
же [190] под названием выдвинутых
кэшей
{push caches).
Совсем недавно проблема динамического размещения реплик была подхваче-
на службами web-хостинга. Эти службы, которые, в сущности, предлагают набор
серверов (более менее статический), разбросанных по всему Интернету, поддер-
живают и предоставляют доступ к web-файлам, принадлежащим третьим лицам.
Для улучшения качества услуг эти службы хостинга могут динамически репли-
цировать файлы на те серверы, для которых такая репликация вызовет увеличе-
ние производительности, то есть поближе к клиентам или группам клиентов.
Одна из проблем реплик, создание которых инициировано сервером, состоит
в необходимости принятия решения о том, где и когда будут создаваться и унич-
тожаться эти реплики. Подход к динамической репликации файлов в случае
служб web-хостинга описан в
[365].
Алгоритм разработан для поддержки web-
страниц и поэтому предусматривает относительно редкие, по сравнению с запро-
сами на чтение, обновления. В качестве модулей данных используются файлы.
Основу функционирования алгоритма динамической репликации составляют
два положения. Во-первых, репликация должна производиться для уменьшения
нагрузки на сервер. Во-вторых, конкретные файлы с сервера должны переме-
щаться или реплицироваться на серверы, расположенные как можно ближе к
клиентам, от которых исходит множество запросов на эти файлы. Далее мы со-
средоточимся только на втором положении. Мы также опустим множество дета-
лей, которые можно найти в
[365].
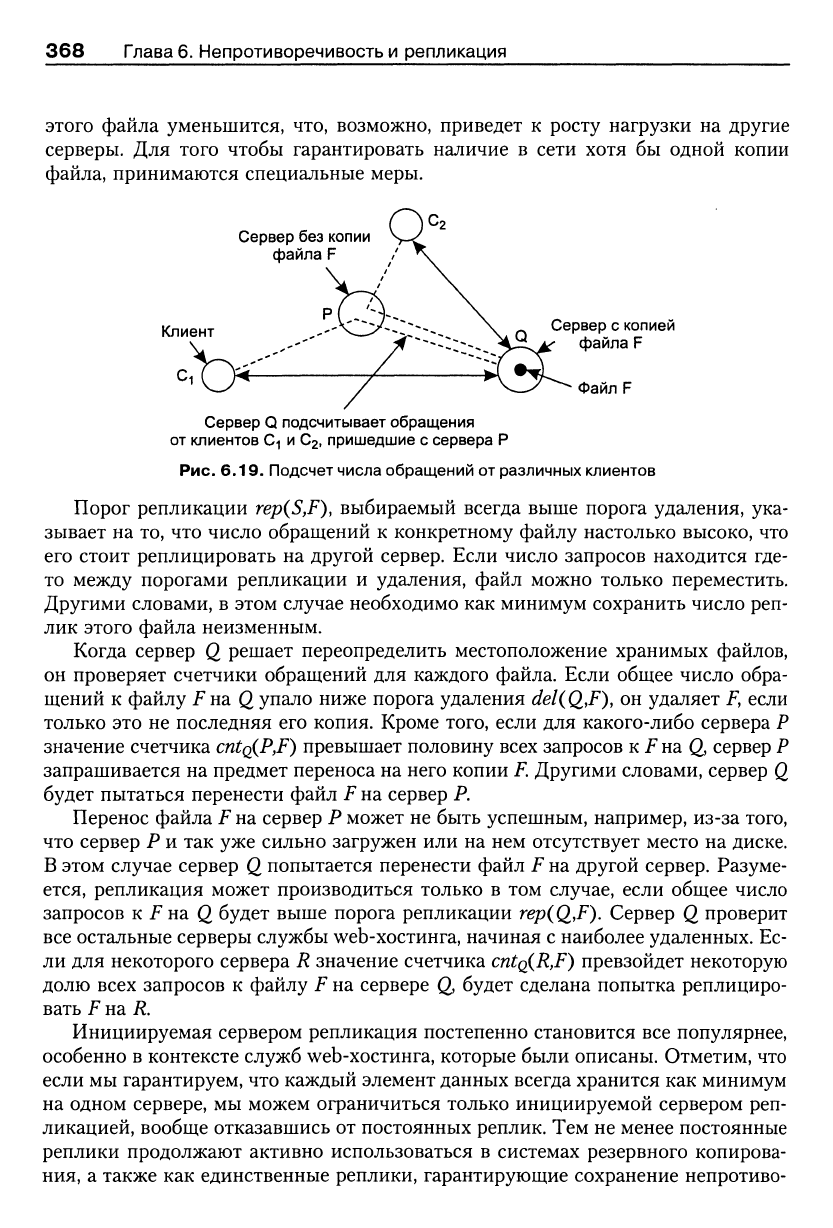
Каждый сервер подсчитывает число обращений к файлам и отслеживает, от-
куда приходят эти обращения. В частности, это означает, для данного клиента С
каждый сервер может определить, какой из серверов службы web-хостинга к не-
му ближе всего (эта информация может быть получена, например, из баз данных
маршрутизации). Если клиент С\ и клиент Сг совместно используют один и тот
же «ближайший» сервер Р, все запросы на доступ к файлу
JF
на сервере Q от Ci и
Сг будут зарегистрированы на Q в едином счетчике обращений
cntQ(P,F).
Эта
картина показана на рис. 6.19.
Когда число запросов на конкретный файл
F
на сервере S упадет ниже порога
удаления del(S,F), файл будет удален с сервера S. Соответственно, число реплик
368 Глава 6. Непротиворечивость и репликация
этого файла уменьшится, что, возможно, приведет к росту нагрузки на другие
серверы. Для того чтобы гарантировать наличие в сети хотя бы одной копии
файла, принимаются специальные меры.
Сервер без копии
файла F
Сервер с копией
файла F
Файл F
Сервер Q подсчитывает обращения
от клиентов C-i и Сг, пришедшие с сервера Р
Рис. 6.19. Подсчет числа обращений от различных клиентов
Порог репликации rep(S,F), выбираемый всегда выше порога удаления, ука-
зывает на то, что число обращений к конкретному файлу настолько высоко, что
его стоит реплицировать на другой сервер. Если число запросов находится где-
то между порогами репликации и удаления, файл можно только переместить.
Другими словами, в этом случае необходимо как минимум сохранить число реп-
лик этого файла неизменным.
Когда сервер Q решает переопределить местоположение хранимых файлов,
он проверяет счетчики обращений для каждого файла. Если общее число обра-
щений к файлу Fm Q упало ниже порога удаления del(Q,F), он удаляет
Fy
если
только это не последняя его копия. Кроме того, если для какого-либо сервера Р
значение счетчика
cntQ(P,F)
превышает половину всех запросов к f на Q, сервер Р
запрашивается на предмет переноса на него копии
F.
Другими словами, сервер Q
будет пытаться перенести файл F на сервер Р.
Перенос файла F на сервер Р может не быть успешным, например, из-за того,
что сервер Р и так уже сильно загружен или на нем отсутствует место на диске.
В этом случае сервер Q попытается перенести файл F на другой сервер. Разуме-
ется, репликация может производиться только в том случае, если общее число
запросов к jFna (2 будет выше порога репликации
rep(QyF).
Сервер Q проверит
все остальные серверы службы web-хостинга, начиная с наиболее удаленных. Ес-
ли для некоторого сервера R значение счетчика
cntQ(R,F)
превзойдет некоторую
долю всех запросов к файлу F на сервере Q, будет сделана попытка реплициро-
вать F на R.
Инициируемая сервером репликация постепенно становится все популярнее,
особенно в контексте служб web-хостинга, которые были описаны. Отметим, что
если мы гарантируем, что каждый элемент данных всегда хранится как минимум
на одном сервере, мы можем ограничиться только инициируемой сервером реп-
ликацией, вообще отказавшись от постоянных реплик. Тем не менее постоянные
реплики продолжают активно использоваться в системах резервного копирова-
ния, а также как единственные реплики, гарантирующие сохранение непротиво-

6.4. Протоколы распределения 369
речивости данных при внесении изменений. При наличии таких постоянных ре-
плик инициируемые сервером реплики затем используются для максимального
приближения к клиентам копий, предназначенных только для чтения.
Реплики,
инициируемые клиентом
Еще один важный тип реплик
—
реплики, создаваемые по инициативе клиентов.
Инициируемые клиентом реплики часто называют клиентскими кэшами {client
caches),
или просто
кэшами
{caches).
В
сущности, кэш
—
это локальное устройство
хранения данных, используемое клиентом для временного хранения копии за-
прошенных данных. В принципе управление кэшем полностью возлагается на
клиента. Хранилище, из которого извлекаются данные, не делает ничего для под-
держания непротиворечивости кэшированных данных. Однако, как мы увидим,
существует множество случаев, в которых клиент полагается на то, что хранили-
ще данных известит его об устаревании кэшированных данных.
Клиентский кэш используется только для сокращения времени доступа к
данным. Обычно, когда клиент хочет получить доступ к некоторым данным, он
связывается с ближайшим хранилищем с их копией и считывает оттуда данные,
которые хочет считать, или сохраняет туда данные, которые он только что изме-
нил. Производительность большинства операций, включающих только чтение
данных, можно повысить, указав клиенту на необходимость сохранять запро-
шенные данные в близко расположенном кэше. Такой кэш может располагаться
на машине клиента или на отдельной машине в той же локальной сети, что и ма-
шина клиента. Когда клиенту в следующий раз потребуется считать те же самые
данные, он просто получит их из локального кэша. Эта схема отлично работает,
если в промежутке между запросами данные не менялись.
Время хранения данных в кэше обычно ограничивается, например, чтобы
предотвратить фатальное устаревание информации или просто освободить место
для новых данных. Если запрашиваемые данные могут быть извлечены из ло-
кального кэша, говорят, что произошло
кэш-попадание {cache
hit). Чтобы повы-
сить число кэш-попаданий, кэш может совместно использоваться несколькими
клиентами. Основой для этого служит предположение о том, что данные, запро-
шенные клиентом Си могут потребоваться также и другому расположенному ря-
дом с ним клиенту Сг.
Насколько это предположение верно, в значительной степени зависит от типа
хранилища данных. Так, например, в традиционных файловых системах файлы
вообще редко используются совместно [68, 308], и создание общего кэша беспо-
лезно. С другой стороны, общий кэш web-страниц оказывается очень полезным,
хотя вносимый им рост производительности постепенно сходит на нет по причи-
не того, что сайтов, совместно используемых различными клиентами, становится
все меньше по сравнению с общим количеством web-страниц [38].
Размещение клиентского кэша
—
дело относительно несложное. Обычно кэш
располагается на той же машине, что и клиент, или на совместно используемой
клиентами машине в одной с ними локальной сети. Однако в некоторых случаях
системные администраторы применяют дополнительные уровни кэширования.

370 Глава 6. Непротиворечивость и репликация
вводя кэш, совместно используемый множеством отделов или фирм, или даже
создавая общий кэш для целых регионов
—
провинций или стран.
Еще один подход к кэшированию
—
поместить серверы (кэши) в определен-
ных точках глобальной сети и позволить клиенту найти ближайший. Когда сер-
вер найден, ему посылается запрос на сохранение данных, которые клиент откуда-
то получил, как описывается в
[318].
Позже в этой главе мы вернемся к кэширо-
ванию при описании протоколов непротиворечивости.
6.4.2. Распространение обновлений
Операции обновления в распределенных и реплицируемых хранилищах данных
обычно инициируются клиентом, после чего пересылаются на одну из копий. От-
туда обновление распространяется на остальные копии, гарантируя тем самым
сохранение непротиворечивости. Как мы увидим далее, существуют различные
аспекты проектирования, связанные с распространением обновлений.
Состояние против операций
Один из важных вопросов проектирования заключается в том, что же именно мы
собираемся распространять. Существует три основных возможности:
4^
распространять только извещение об обновлении;
4-
передавать данные из одной копии в другую;
4-
распространять операцию обновления по всем копиям.
Распространение извещения производится в соответствии с
протоколами
о
несостоятельности {invalidation
protocols).
Согласно протоколу о несостоятель-
ности другие копии информируются об имевшем место обновлении, а также
о том, что хранящиеся у них данные стали неправильными. Эта информация мо-
жет определять, какая именно часть хранилища данных была изменена, то есть
какая часть данных перестала соответствовать действительности. Важно отме-
тить,
что при этом не передается ничего кроме извещения. Независимо от тре-
буемой для неправильной копии операции, обычно сначала нужно обновить эту
копию. Конкретные действия по обновлению зависят от поддерживаемой моде-
ли непротиворечивости.
Основное преимущество протоколов о несостоятельности в том, что они ис-
пользуют минимум пропускной способности сети. Единственная информация,
которую необходимо передавать,
—
это указание на то, какие данные стали не-
правильными. Протоколы о несостоятельности обычно прекрасно работают при
большем, по сравнению с операциями чтения, количестве операций записи, то
есть в условиях, когда отношение операций чтения к операциям записи относи-
тельно невелико.
Рассмотрим, например, хранилище данных, в котором обновления распро-
страняются путем рассылки обновленных данных всем репликам. Если размер
обновленных данных велик, а обновления, по сравнению с операциями чтения,
происходят часто, мы можем столкнуться с ситуацией, когда два обновления
происходят одно за другим так, что в промежутке между ними операции чтения