Meszaros G. xUnit Test Patterns Refactoring Test Code
Подождите немного. Документ загружается.


238
Chapter 16 Behavior Smells
Root Cause
Nondeterministic Tests are caused by using different values each time a test is
run. Sometimes, of course, it is a good idea to use different values each time the
same test is run. For example, Distinct Generated Values may legitimately be
used as unique keys for objects stored in a database. Use of generated values as
input to an algorithm where the behavior of the SUT is expected to differ for
different values can cause Nondeterministic Tests, however, as in the following
examples:
• Integer values where negative (or even zero) values are treated differ-
ently by the system, or where there is a maximum allowable value. If
we generate a value at random, the test could fail in some test runs and
pass on others.
• String values where the length of a string has minimum or maximum
allowed values. This problem often occurs accidentally when we gener-
ate a random or unique numeric value and then convert it to a string
representation without using an explicit format that guarantees the
length is constant.
It might seem like a good idea to use random values because they would improve
our test coverage. Unfortunately, this tactic decreases our understanding of the
test coverage and the repeatability of our tests (which violates the Repeatable Test
principle; see page 26).
Another potential cause of Nondeterministic Tests is the use of Conditional
Test Logic (page 200) in our tests. Its inclusion can result in different code
paths being executed on different test runs, which in turn makes our tests non-
deterministic. A common “reason” cited for doing so is the Flexible Test (see
Conditional Test Logic). Anything that makes the tests less than completely
deterministic is a bad idea!
Possible Solution
The fi rst step is to make our tests repeatable by ensuring that they execute in a
completely linear fashion by removing any Conditional Test Logic. Then we can
go about replacing any random values with deterministic values. If this results in
poor test coverage, we can add more tests for the interesting cases we aren’t cov-
ering. A good way to determine the best set of input values is to use the bound-
ary values of the equivalence classes. If their use results in a lot of Test Code
Duplication, we can extract a Parameterized Test (page 607) or put the input val-
ues and the expected results into a fi le read by a Data-Driven Test (page 288).
Erratic Test

239
Fragile Test
A test fails to compile or run when the SUT is changed in ways that
do not affect the part the test is exercising.
Symptoms
We have one or more tests that used to run and pass but now either fail
to compile and run or fail when they are run. When we have changed the
behavior of the SUT in question, such a change in test results is expected.
When we don’t think the change should have affected the tests that are fail-
ing or we haven’t changed any production code or tests, we have a case of
Fragile Tests.
Past efforts at automated testing have often run afoul of the “four sensitivities”
of automated tests. These sensitivities are what cause Fully Automated Tests (see
page 26) that previously passed to suddenly start failing. The root cause for tests
failing can be loosely classifi ed into one of these four sensitivities. Although each
sensitivity may be caused by a variety of specifi c test coding behaviors, it is useful
to understand the sensitivities in their own right.
Impact
Fragile Tests increase the cost of test maintenance by forcing us to visit many
more tests each time we modify the functionality of the system or the fi xture.
They are particularly deadly when projects rely on highly incremental delivery,
as in agile development (such as eXtreme Programming).
Troubleshooting Advice
We need to look for patterns in how the tests fail. We ask ourselves, “What do
all of the broken tests have in common?” The answer to this question should
help us understand how the tests are coupled to the SUT. Then we look for ways
to minimize this coupling.
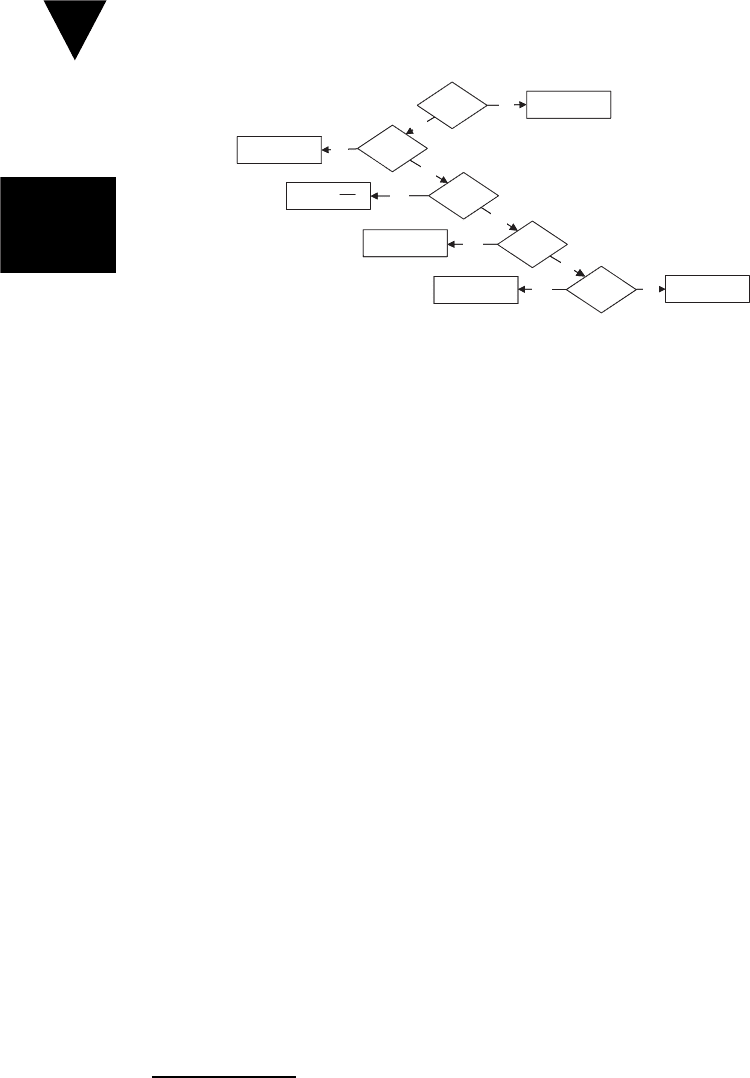
Figure 16.2 summarizes the process for determining which sensitivity we are
dealing with.
Fragile Test
Fragile Test
240
Chapter 16 Behavior Smells
Figure 16.2 Troubleshooting a Fragile Test.
The general sequence is to fi rst ask ourselves whether the tests are failing to
compile; if so, Interface Sensitivity is likely to blame. With dynamic languages
we may see type incompatibility test errors at runtime—another sign of Interface
Sensitivity.
If the tests are running but the SUT is providing incorrect results, we must
ask ourselves whether we have changed the code. If so, we can try backing out
of the latest code changes to see if that fi xes the problem. If that tactic stops the
failing tests,
1
then we had Behavior Sensitivity.
If the tests still fail with the latest code changes backed out, then something
else must have changed and we must be dealing with either Data Sensitiv-
ity or Context Sensitivity. The former occurs only when we use a Shared Fix-
ture (page 317) or we have modifi ed fi xture setup code; otherwise, we must
have a case of Context Sensitivity.
While this sequence of asking questions isn’t foolproof, it will give the right
answer probably nine times out of ten. Caveat emptor!
Causes
Fragile Tests may be the result of several different root causes. They may be
a sign of Indirect Testing (see Obscure Test on page 186)—that is, using the
objects we modifi ed to access other objects—or they may be a sign that we have
Eager Tests (see Assertion Roulette on page 224) that are verifying too much
functionality. Fragile Tests may also be symptoms of overcoupled software that
is hard to test in small pieces (Hard-to-Test Code; see page 209) or our lack of
experience with unit testing using Test Doubles (page 522) to test pieces in isola-
tion (Overspecifi ed Software).
1
Other tests may fail because we have removed the code that made them pass—but
at least we have established which part of the code they depend on.
Has Some
Code Changed?
Are the Tests
Compiling?
No
Probably Interface
Sensitivity
Yes
Have the Failing
Tests Changed?
No
Probably Context
Sensitivity
Has the Test
Data Changed?
No
No
Probably Data
Sensitivity
Yes
Yes
Probably Behavior
Sensitivity
Yes
Possibly Not
Fragile Test
Are the Tests
Erroring?
No
Possibly Interface
Sensitivity
Yes
Has Some
Code Changed?
Are the Tests
Compiling?
No
Probably Interface
Sensitivity
Yes
Have the Failing
Tests Changed?
No
Probably Context
Sensitivity
Has the Test
Data Changed?
No
No
Probably Data
Sensitivity
Yes
Yes
Probably Behavior
Sensitivity
Yes
Possibly Not
Fragile Test
Are the Tests
Erroring?
No
Possibly Interface
Sensitivity
Yes
Fragile Test

241
Regardless of their root cause, Fragile Tests usually show up as one of the
four sensitivities. Let’s start by looking at them in a bit more detail; we’ll
then examine some more detailed examples of how specifi c causes change test
output.
Cause: Interface Sensitivity
Interface Sensitivity occurs when a test fails to compile or run because some part
of the interface of the SUT that the test uses has changed.
Symptoms
In statically typed languages, Interface Sensitivity usually shows up as a failure
to compile. In dynamically typed languages, it shows up only when we run the
tests. A test written in a dynamically typed language may experience a test error
when it invokes an application programming interface (API) that has been modi-
fi ed (via a method name change or method signature change). Alternatively, the
test may fail to fi nd a user interface element it needs to interact with the SUT via
a user interface. Recorded Tests (page 278) that interact with the SUT through
a user interface
2
are particularly prone to this problem.
Possible Solution
The cause of the failures is usually reasonably apparent. The point at which the
test fails (to compile or execute) will usually point out the location of the prob-
lem. It is rare for the test to continue to run beyond the point of change—after
all, it is the change itself that causes the test error.
When the interface is used only internally (within the organization or applica-
tion) and by automated tests, SUT API Encapsulation (see Test Utility Method
on page 599) is the best solution for Interface Sensitivity. It reduces the cost
and impact of changes to the API and, therefore, does not discourage necessary
changes from being made. A common way to implement SUT API Encapsula-
tion is through the defi nition of a Higher-Level Language (see page 41) that is
used to express the tests. The verbs in the test language are translated into the
appropriate method calls by the encapsulation layer, which is then the only soft-
ware that needs to be modifi ed when the interface is altered in somewhat back-
ward-compatible ways. The “test language” can be implemented in the form
of Test Utility Methods such as Creation Methods (page 415) and Verifi cation
Methods (see Custom Assertion on page 474) that hide the API of the SUT
from the test.
2
Often called “screen scraping.”
Fragile Test
Fragile Test

242
Chapter 16 Behavior Smells
The only other way to avoid Interface Sensitivity is to put the interface
under strict change control. When the clients of the interface are external
and anonymous (such as the clients of Windows DLLs), this tactic may be
the only viable alternative. In these cases, a protocol usually applies to mak-
ing changes to interfaces. That is, all changes must be backward compatible;
before older versions of methods can be removed, they must be deprecated,
and deprecated methods must exist for a minimum number of releases or
elapsed time.
Cause: Behavior Sensitivity
Behavior Sensitivity occurs when changes to the SUT cause other tests to fail.
Symptoms
A test that once passed suddenly starts failing when a new feature is added to
the SUT or a bug is fi xed.
Root Cause
Tests may fail because the functionality they are verifying has been modifi ed.
This outcome does not necessarily signal a case of Behavior Sensitivity because it
is the whole reason for having regression tests. It is a case of Behavior Sensitivity
in any of the following circumstances:
• The functionality the regression tests use to set up the pre-test state of
the SUT has been modifi ed.
• The functionality the regression tests use to verify the post-test state of
the SUT has been modifi ed.
• The code the regression tests use to tear down the fi xture has been
changed.
If the code that changed is not part of the SUT we are verifying, then we are
dealing with Context Sensitivity. That is, we may be testing too large a SUT. In
such a case, what we really need to do is to separate the SUT into the part we
are verifying and the components on which that part depends.
Possible Solution
Any newly incorrect assumptions about the behavior of the SUT used during
fi xture setup may be encapsulated behind Creation Methods. Similarly, assump-
tions about the details of post-test state of the SUT can be encapsulated in Cus-
tom Assertions or Verifi cation Methods. While these measures won’t eliminate
Fragile Test

243
the need to update test code when the assumptions change, they certainly do
reduce the amount of test code that needs to be changed.
Cause: Data Sensitivity
Data Sensitivity occurs when a test fails because the data being used to test the
SUT has been modifi ed. This sensitivity most commonly arises when the con-
tents of the test database change.
Symptoms
A test that once passed suddenly starts failing in any of the following circum-
stances:
• Data is added to the database that holds the pre-test state of the SUT.
• Records in the database are modifi ed or deleted.
• The code that sets up a Standard Fixture (page 305) is modifi ed.
• A Shared Fixture is modifi ed before the fi rst test that uses it.
In all of these cases, we must be using a Standard Fixture, which may be either
a Fresh Fixture (page 311) or a Shared Fixture such as a Prebuilt Fixture (see
Shared Fixture).
Root Cause
Tests may fail because the result verifi cation logic in the test looks for data that
no longer exists in the database or uses search criteria that accidentally include
newly added records. Another potential cause of failure is that the SUT is being
exercised with inputs that reference missing or modifi ed data and, therefore, the
SUT behaves differently.
In all cases, the tests make assumptions about which data exist in the data-
base—and those assumptions are violated.
Possible Solution
In those cases where the failures occur during the exercise SUT phase of the test,
we need to look at the pre-conditions of the logic we are exercising and make
sure they have not been affected by recent changes to the database.
In most cases, the failures occur during result verifi cation. We need to
examine the result verifi cation logic to ensure that it does not make any un-
reasonable assumptions about which data exists. If it does, we can modify the
verifi cation logic.
Fragile Test
Fragile Test

244
Chapter 16 Behavior Smells
Why Do We Need 100 Customers?
A software development coworker of mine was working on a project
as an analyst. One day, the manager she was working for came into her
offi ce and asked, “Why have you requested 100 unique customers be cre-
ated in the test database instance?”
As a systems analyst, my coworker was responsible for helping the busi-
ness analysts defi ne the requirements and the acceptance tests for a large,
complex project. She wanted to automate the tests but had to overcome
several hurdles. One of the biggest hurdles was the fact that the SUT got
much of its data from an upstream system—it was too complex to try to
generate this data manually.
The systems analyst came up with a way to generate XML from tests
captured in spreadsheets. For the fi xture setup part of the tests, she trans-
formed the XML into QaRun (a Record and Playback Test tool—see
Recorded Test on page 278) scripts that would load the data into the
upstream system via the user interface. Because it took a while to run
these scripts and for the data to make its way downstream to the SUT, the
systems analyst had to run these scripts ahead of time. This meant that
a Fresh Fixture (page 311) strategy was unachievable; a Prebuilt Fix-
ture (page 429) was the best she could do. In an attempt to avoid the
Interacting Tests (see Erratic Test on page 228) that were sure to result
from a Shared Fixture (page 317), the systems analyst decided to imple-
ment a virtual Database Sandbox (page 650) using a Database Partition-
ing Scheme based on a unique customer number for each test. This way,
any side effects of one test couldn’t affect any other tests.
Given that she had about 100 tests to automate, the systems analyst
needed about 100 test customers defi ned in the database. And that’s
what she told her manager.
The failure can show up in the result verifi cation logic even if the problem is that
the inputs of the SUT refer to nonexistent or modifi ed data. This may require ex-
amining the “after” state of the SUT (which differs from the expected post-test
state) and tracing it back to discover why it does not match our expectations.
This should expose the mismatch between SUT inputs and the data that existed
before the test started executing.
The best solution to
Data Sensitivity is to make the tests independent of
the existing contents of the database—that is, to use a Fresh Fixture. If this
is not possible, we can try using some sort of Database Partitioning Scheme
Fragile Test

245
(see Database Sandbox on page 650) to ensure that the data modifi ed for one
test does not overlap with the data used by other tests. (See the sidebar “Why
Do We Need 100 Customers?” on page 244 for an example.)
Another solution is to verify that the right changes have been made to the
data. Delta Assertions (page 485) compare before and after “snapshots” of the
data, thereby ignoring data that hasn’t changed. They eliminate the need to
hard-code knowledge about the entire fi xture into the result verifi cation phase
of the test.
Cause: Context Sensitivity
Context Sensitivity occurs when a test fails because the state or behavior of the
context in which the SUT executes has changed in some way.
Symptoms
A test that once passed suddenly starts failing for mysterious reasons. Unlike
with an Erratic Test (page 228), the test produces consistent results when run
repeatedly over a short period of time. What is different is that it consistently
fails regardless of how it is run.
Root Cause
Tests may fail for two reasons:
• The functionality they are verifying depends in some way on the time
or date.
• The behavior of some other code or system(s) on which the SUT
depends has changed.
A major source of Context Sensitivity is confusion about which SUT we are
intending to verify. Recall that the SUT is whatever piece of software we are intend-
ing to verify. When unit testing, it should be a very small part of the overall system
or application. Failure to isolate the specifi c unit (e.g., class or method) is bound
to lead to Context Sensitivity because we end up testing too much software all at
once. Indirect inputs that should be controlled by the test are then left to chance. If
someone then modifi es a depended-on component (DOC), our tests fail.
To eliminate Context Sensitivity, we must track down which indirect input to
the SUT has changed and why. If the system contains any date- or time-related
logic, we should examine this logic to see whether the length of the month or
other similar factors could be the cause of the problem.
If the SUT depends on input from any other systems, we should examine these
inputs to see if anything has changed recently. Logs of previous interactions
Fragile Test
Fragile Test

246
Chapter 16 Behavior Smells
with these other systems are very useful for comparison with logs of the failure
scenarios.
If the problem comes and goes, we should look for patterns related to when
it passes and when it fails. See Erratic Test for a more detailed discussion of
possible causes of Context Sensitivity.
Possible Solution
We need to control all the inputs of the SUT if our tests are to be deterministic.
If we depend on inputs from other systems, we may need to control these inputs
by using a Test Stub (page 529) that is confi gured and installed by the test. If the
system contains any time- or date-specifi c logic, we need to be able to control the
system clock as part of our testing. This may necessitate stubbing out the system
clock with a Virtual Clock [VCTP] that gives the test a way to set the starting
time or date and possibly to simulate the passage of time.
Cause: Overspecifi ed Software
A test says too much about how the software should be structured or behave.
This form of Behavior Sensitivity (see Fragile Test on page 239) is associated with
the style of testing called Behavior Verifi cation (page 468). It is characterized by
extensive use of Mock Objects (page 544) to build layer-crossing tests. The main
issue is that the tests describe how the software should do something, not what it
should achieve. That is, the tests will pass only if the software is implemented in
a particular way. This problem can be avoided by applying the principle Use the
Front Door First (see page 40) whenever possible to avoid encoding too much
knowledge about the implementation of the SUT into the tests.
Cause: Sensitive Equality
Objects to be verifi ed are converted to strings and compared with an expected
string. This is an example of Behavior Sensitivity in that the test is sensitive
to behavior that it is not in the business of verifying. We could also think of
it as a case of Interface Sensitivity where the semantics of the interface have
changed. Either way, the problem arises from the way the test was coded;
using the string representations of objects for verifying them against expected
values is just asking for trouble.
Cause: Fragile Fixture
When a Standard Fixture is modifi ed to accommodate a new test, several other
tests fail. This is an alias for either Data Sensitivity or Context Sensitivity
depending on the nature of the fi xture in question.
Also known as:
Overcoupled
Test
Fragile Test

247
Further Reading
Sensitive Equality and Fragile Fixture were fi rst described in [RTC], which was
the fi rst paper published on test smells and refactoring test code. The four sen-
sitivities were fi rst described in [ARTRP], which also described several ways to
avoid Fragile Tests in Recorded Tests.
Fragile Test
Fragile Test