Sundararaja D. The Discrete Fourier Transform. Theory, Algorithms and Applications
Подождите немного. Документ загружается.


294
Convolution and Correlation
overlapped by Q
— 1
samples to eliminate errors due to circular convolution
and saving N
—
Q + 1 output values, this method is called overlap-save
method of indirect convolution.
Implementation
The implementation consists of reading blocks of data, two at a time, com-
puting the DFT, multiplying it with the DFT of the impulse response,
computing the IDFT of the product, and storing the valid output. These
operations are repeated until the data is exhausted. As we are finding the
output of two blocks of length N at a time, the computational complexity
for one block is half and it is of computing a complex DFT. The computa-
tion of the DFT of the impulse response is carried out once and is ignored
in the analysis. A single DFT algorithm is sufficient as it can be used for
computing both DFT and IDFT. A table of twiddle factors can be used
repeatedly. The multiplication of two DFTs requires 3iV
—
4 operations for
each block. A block produces N
—
Q +1 valid output points. For example,
let N = 64. The 2x2 PM algorithm for complex data requires 1184 real
multiplications and additions. Multiplying the DFTs requires 188 opera-
tions.
For an impulse response of length 12, 64
—
11 = 53 valid output
points are produced. Therefore, the number of operations per output point
is
U84+188 _ 25.9 (approximately 41og
2
TV).
As for the choice for block length N, the following considerations must
be taken into account. If the block length is long there are two disadvan-
tages:
(i) more memory is required and (ii) the number of DFT operations
per point increases. On the other hand, if the block length is short then
the overlap is more and the number of valid outputs decreases. In general,
for efficient implementation, the following condition is required.
Input length >> Block length, N » Impulse response, Q
Table 14.1 shows the number of operations for various block and impulse
response lengths. The minimum operation count is shown in boldface. The
other major factor is the data transfers which is about
2
log
2
N per output
point. With the complexity order N log
2
N for both arithmetic operations
and data transfers, the indirect convolution using fast DFT algorithms is
efficient for most cases than direct convolution. As the block sizes are much
smaller for any data size, the storage requirements are moderate.

Two-Dimensional Convolution
295
Table 14.1 The number of real arithmetic operations per point for various impulse
response and transform block lengths using 2x2 PM DFT algorithm for 1-D convolution
by the over-lap save method
N\IR
32
64
128
256
512
1024
12
26.5
25.9
28.1
31.2
34.9
38.8
16
32.7
28.0
29.1
31.7
35.2
38.9
24
61.8
33.5
31.4
32.8
35.8
39.2
32
41.6
33.9
34.0
36.4
39.5
40
54.9
37.0
35.2
37.0
39.9
48
80.7
40.6
36.6
37.6
40.2
56
45.1
38.0
38.3
40.5
64
50.7
39.6
39.0
40.9
72
57.8
41.3
39.7
41.2
80
67.2
43.2
40.4
41.6
88
80.3
45.2
41.2
41.9
14.4 Two-Dimensional Convolution
The 2-D linear convolution of sequences x{n\, n
2
), ni,n
2
= 0,1,...,P
—
1
and /i(rai,n
2
), ni,n
2
= 0,1,. ..,Q
—
1 is given by
Min(ni,P-l) Min(n
2
,P-l)
y(ni,n
2
) = ^ J^ a;(ii,t
2
)/j(ni - ii,n
2
- »
2
),
ii=Moi(0,ni-CJ+l) i?=Max(0
<
m— Q+1)
n
1
,n
2
=0,l,...,P + Q-2
Consider the 5x5 sequence ar(«i,i
2
) and the 3x3 sequence ft^'i, i
2
) shown
in Fig. 14.5. There are the same four steps of the 1-D convolution extended
to two dimensions.
2
1
3
2
1
X
1
0
1
0
0
r
«i,
4
2
0
1
4
*?)
3
2
1
3
2
3
2
0
5
5
h(
1
3
8
H,i2)
3
5
1
2
6
3
h(ii,-
2
6
3
3
5
1
•12)
1
3
8
s(ii,
J2W0 - ii,0 - i-a) x{ii,i
2
)h{2-i
u
l-i
2
)
3
6
2
1
5
3
8
3
1
5
1
3
2
1
1
C
1
c
c
4
2
0
1
4
3
2
1
3
2
3
2
0
5
5
1 28 1
5 1 3
C
3
311
U
2
C 1
0
1 0
3 5
22
19
31
19
1 C 4 2 5 8 1 35 20 54 11 15
M-
3
6
2
*i,-
1
5
3
-i
2
)
8
3
1
16
25
25
24
•u(n\,ni)
11
33
60
47
31
32
17
43
50
33
39
51
20
60
70
45
56
95
15
43
36
35
65
51
22
21
16
40
45
Fig. 14.5 The linear convolution of a 5 x 5 and a 3 x 3 2-D sequences. Origin at upper
left-hand corner.

296
Convolution and Correlation
(1) The sequence ft(i'i,Z2) is rotated in the
(11,12)
plane by 180 degrees
about the origin. This operation can be achieved in two steps as
shown in Fig. 14.5. Fold the sequence about i\ axis to get h(i\, -i
2
).
Then, we get h(-ii,—i
2
) by folding the resulting sequence about
12
axis.
(2) Shift the rotated sequence by an amount (711,712) to get the se-
quence h(n\
—
»i,ri2
—
12)-
(3) Find the products x(ii,i2)h(ni
—
n,n
2
- 12) of all the overlapping
samples.
(4) Sum the products to get the convolution output y(ni,n
2
).
For example, with a shift of 0
—
i\, 0
—12,
there is only one overlapping pair
(1,2).
The product of these numbers yields the output y(0,0) = 2. The
overlapping samples with a shift of 2
—
ti,
1 —
i
2
is also shown in Fig. 14.5.
The process is repeated to get the complete convolution output y (711,712)
shown in Fig. 14.5.
Two-dimensional circular convolution
The 2-D circular convolution of periodic sequences z(ni,n
2
), ni,n
2
=
0,1,...,N
—
1 and /i(ni,7i2), ni,7i2 =
0,1,...,N
—
1 is given by
JV-l JV-1
y(7ii,n
2
) = X] 5Z
x
(
i
2,i2)h(ni -ii,n
2
- i
2
), 7ii,n
2
=
0,1,...
,N - 1
i
1=
o i
2
=o
Fig. 14.6 shows the 5x5 sequence x(ii,i
2
) and the 3x3 sequence h(ii,
12)
of Fig. 14.5 padded with sufficient zeros so that, by using a power of two
DFT algorithm, the linear convolution is correctly simulated.
Overlap-save method
The 5x5 sequence x(i\,i2) and the 3x3 sequence h(ii,i2) of Fig. 14.5 are
zero padded as shown in Fig. 14.7. The outputs of two blocks each of size
4x4 are produced at a time. Fig. 14.8(a) shows the combined DFT of the

Two-Dimensional Convolution
297
2
1
3
2
1
0
0
0
1
0
1
0
0
0
0
0
4
2
0
1
4
0
0
0
x'
3
2
1
3
2
0
0
0
[k,
3
2
0
5
5
0
0
0
ii)
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
h!{ii,i
2
)
1
3
8
0
0
0
0
0
3
5
1
0
0
0
0
0
2
6
3
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Fig. 14.6 The sequences 1(11,12) and h(h,i2) of Fig. 14.5 padded with zeros in order to
use the circular convolution to simulate the linear convolution. Origin at upper left-hand
corner.
first two blocks,
0+jQ 0 + jO 0 + jO 0 + jO
0+jO 0 + jO 0 + jO 0 + jO
0+j2 0 + j'l 2 + j4 l + j3
0+jl 0 + jO 1+J2 0 + j2
the real parts in the upper half and the imaginary parts in the lower
half.
The DFT of the sequence h'{ii,i
2
) divided by 16 is shown in Fig. 14.8(b).
The division by 16 eliminates the necessity of the division operation each
time an ID FT is computed. Figure 14.8(c) shows the product of the two
DFTs.
The convolution output of the first two blocks is obtained by com-
puting the IDFT (remember the division by 16 required by the IDFT op-
eration has already been done) of the product. The first block output is
the real part and the second block output is the imaginary part shown in
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
2
1
3
2
1
0
0
0
x'(i
0
0
1
JL
T
1
0
0
0
0
0
0
0
4
2
0
1
4
0
0
0
L,»2
0
0
3
2
1
3
2
0
0
0
)
0
0
3
2
0
5
5
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
h'(ii,i
2
)
1
3
8
0
3
5
1
0
2
6
3
0
0
0
0
0
Fig. 14.7 The sequences x(ii,i
2
) and/i(n,i
2
) of Fig. 14.5 padded with zeros to convolve
using the overlap-save method.
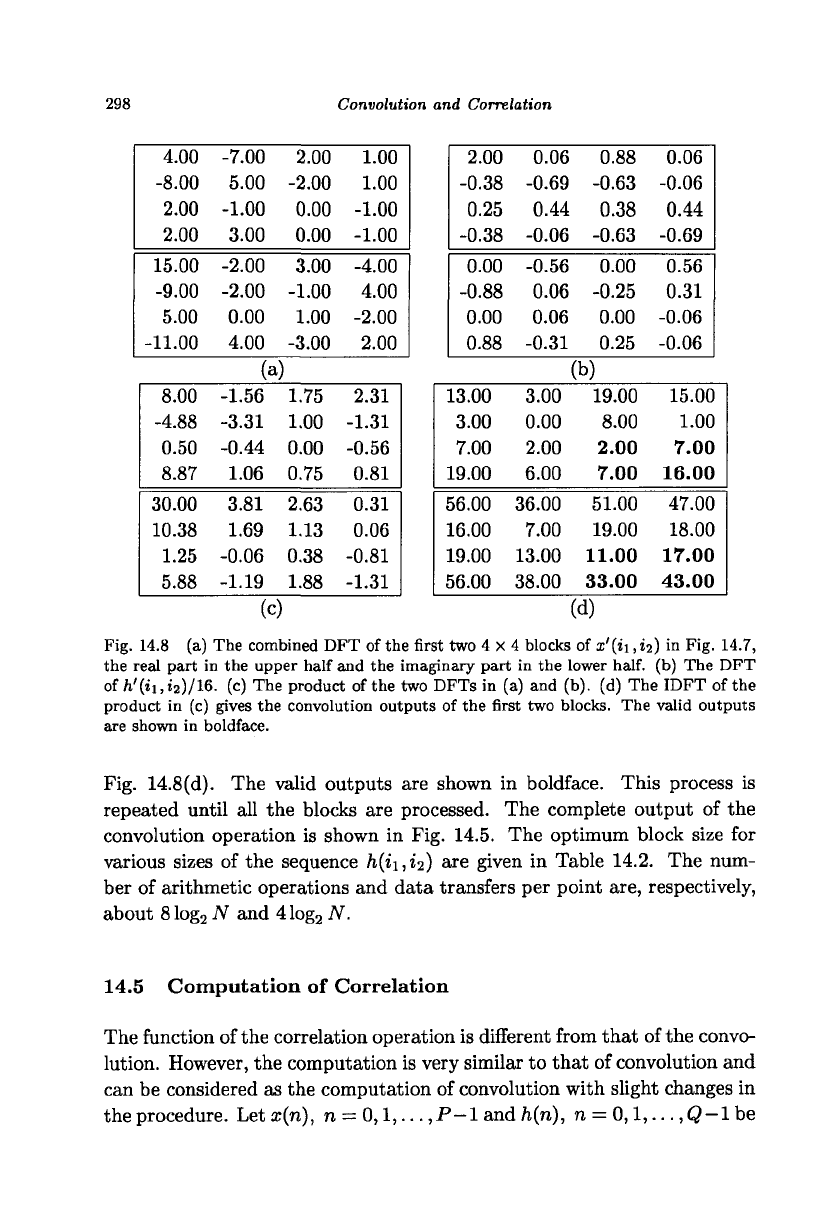
298 Convolution and Correlation
4.00
-8.00
2.00
2.00
15.00
-9.00
5.00
-11.00
-7.00
5.00
-1.00
3.00
-2.00
-2.00
0.00
4.00
2.00
-2.00
0.00
0.00
3.00
-1.00
1.00
-3.00
1.00
1.00
-1.00
-1.00
-4.00
4.00
-2.00
2.00
2.00
-0.38
0.25
-0.38
0.00
-0.88
0.00
0.88
0.06
-0.69
0.44
-0.06
-0.56
0.06
0.06
-0.31
0.88
-0.63
0.38
-0.63
0.00
-0.25
0.00
0.25
0.06
-0.06
0.44
-0.69
0.56
0.31
-0.06
-0.06
(a) (b)
8.00
-4.88
0.50
8.87
30.00
10.38
1.25
5.88
-1.56
-3.31
-0.44
1.06
3.81
1.69
-0.06
-1.19
1.75
1.00
0.00
0.75
2.63
1.13
0.38
1.88
2.31
-1.31
-0.56
0.81
0.31
0.06
-0.81
-1.31
13.00
3.00
7.00
19.00
56.00
16.00
19.00
56.00
3.00
0.00
2.00
6.00
36.00
7.00
13.00
38.00
19.00
8.00
2.00
7.00
51.00
19.00
11.00
33.00
15.00
1.00
7.00
16.00
47.00
18.00
17.00
43.00
(c) (d)
Fig. 14.8 (a) The combined DFT of the first two 4 x 4 blocks of x'(ii, i
2
) in Fig. 14.7,
the real part in the upper half and the imaginary part in the lower
half,
(b) The DFT
of/i'(ii,i
2
)/16. (c) The product of the two DFTs in (a) and (b). (d) The IDFT of the
product in (c) gives the convolution outputs of the first two blocks. The valid outputs
are shown in boldface.
Fig. 14.8(d). The valid outputs are shown in boldface. This process is
repeated until all the blocks are processed. The complete output of the
convolution operation is shown in Fig. 14.5. The optimum block size for
various sizes of the sequence h^i,^) are given in Table 14.2. The num-
ber of arithmetic operations and data transfers per point are, respectively,
about 8 log
2
N and 4 log
2
N.
14.5 Computation of Correlation
The function of the correlation operation is different from that of the convo-
lution. However, the computation is very similar to that of convolution and
can be considered as the computation of convolution with slight changes in
the procedure. Letar(n), n =
0,1,...,
P-l and/i(n), n =
0,1,...
,Q-1 be

Computation of Correlation
299
Table 14.2 The number of real arithmetic operations per point for various impulse
response and transform block lengths using 2x2 PM DFT algorithm for 2-D convolution
by the over-lap save method
NxNMR 3x3 5x5 7x7 9x9 11 x 11 13 x 13 15 x 15
8x8
16x16
32x32
64x64
128 x 128
30.0
31.3
36.4
42.6
50.1
42.6
41.8
45.5
51.7
61.4
48.5
48.7
53.4
56.9
52.2
55.2
56.2
57.1
60.6
59.1
65.5
61.1
i
m
h(3 + i) 1 21 3
h(2 + i) | 2
h(l + i)
h(0 + i)
-1
3
2
M-i +
C
2
1
1
-1
3
2
»)
h(-2 +
h
n
Vxhin)
1
a
4
1
-1
3
2
0
(-3 +
3
1
2
3
2
-1
2
3
1
-1
1
-1
3
2
i)
1
1
1
-1
3
2
C
11
1
-1
3
-1
15
1
-1
-2
1
1
-3
-2
Fig. 14.9 The linear correlation operation.
two arbitrary sequences. Assume that x(n) = 0, for n < 0 and n > P-1
and h(n) = 0, for n < 0 and n > Q
—
1. Then the linear correlation of
the two sequences is given by
Min(Q-n-l,P-l)
Vxhin) = J2 x*(i)h(n + i), n = Q-1,Q-2,... ,-P + 1
i=Max(0,—n)
One difference between this operation and the convolution is that there
is no folding operation in computing the correlation operation. Another
difference is that the correlation operation, in general, is not commutative.
A yet another difference is that the first function is conjugated. Otherwise,
the correlation operation is similar to convolution as can be seen from
Fig. 14.9, which shows the computation of the linear correlation of two
sequences {1,4,2,-1} and
{2,3,-1,1}.

300
Convolution and Correlation
5|—4|—3—2|—H q 1] 2| 31 4! 51 6
h?(i) = h'(7-i)
hrs (i) = hr'(i
—
3)
x'U)
hrs'(0 - i) Q_C_C _2 _3^1
firs'(1 -t)
C C
c
C 2 3-1
0 0
c
hrs'(2-t)
hrs' (3
-1J
/irs'(4-l)
hrs'(b —TJ
hrs'(6 —1)
L(»)
C 0 2 3-1
2 3-11
2 0 C 0
C
-13 2
C C 0
1
0 2 3-1
0 C 2 3
C C 2
C
1 3
2-1
C 0
1
C
-1
1 11
CCO
15
-1 3
C 0
0 0
3-1
3-1
1-2
2 3-1
C 2 3-1
C C 2 3-1
COO
C C 2 3-1
B
Fig. 14.10 The linear correlation operation simulated by the circular convolution oper-
ation with zero padding.
The circular correlation
Letz(n), n =
0,1,..
.,N—1 and h(n), n =
0,1,..
.,iV
—1
be the samples of
one period of periodic signals with period N. Then, the circular or periodic
correlation of the two sequences is given by
JV-l
Vxh{n) = Y^ x*(i)h{n + i), n =
0,1,...,
N - 1
t=0
y
x
h{n),
n =
0,1,...,
N - 1 gives samples of one period of the periodic
output sequence 2/i/i(n) with period N. To compute the linear correlation
using the circular correlation, we zero pad the signals exactly the same
way as for computing the convolution. In this case, the sequence hr'(i) —
h'(N
—
i) is formed and is circularly right shifted by Q
—
1 positions to get
hrs'(i) = hr'(i
—
(Q
—
1)). Now, the circular convolution of the sequences
x'(i)
and hrs'(i) yields the linear correlation output. This computation,
shown in Fig. 14.10, corresponds to
y'
xh
{n)
= WFT(X'(k)H'*{k)W$~
1)k
)
in the transform domain. The overlap-save method of correlation is similar
to that of convolution shown in Fig. 14.4 with the difference mentioned
above. That is the formation of
H'*(k)W]f~
' initially instead of
H'(k).
The linear correlation output of the sequences x(n) and h(n) shown in
Fig. 14.4 is
{21,40,26,31,36,52,50,23,25,22,24,25,46,57,38,22,12}

Summary
301
Table 14.3 The linear correlation output,
y
x
h(ni,ri2),
of the sequences 1(11,12) and
Mil)*z) shown in Fig. 14.5. Origin at upper left-hand corner.
6
15
19
26
21
10
2
5
17
19
26
22
11
3
29
49
53
38
38
31
9
21
49
52
29
36
41
16
44
69
48
43
100
72
20
27
42
36
40
56
49
17
24
25
9
42
55
20
5
The 2-D linear correlation of sequences x(n\, n^), ni,ri2 = 0,1,...,P—1
and /i(ni,n
2
), ni,ri2 = 0,1,. ..,Q
—
1 is given by
Min(Q-m-l,P-l) Min(Q-m-l,P-l)
Vxh(ni,n
2
)= ^2 Y^, x*(ii,i
2
)h(ni+ii,n
2
+ i2),
ii = Max(0,—m) Z2 = Max(0,—n?)
ni,
n
2
= Q - 1, Q -
2,...,
-P + 1.
The computation of the 2-D correlation is similar to that of the 2-D convo-
lution with the difference mentioned for the computation of 1-D correlation
extended to two dimensions. Table 14.3 shows the linear correlation output
of the sequences x{ii,i2) and h{ii,ii) shown in Fig. 14.5.
14.6 Summary
• The convolution operation implemented using the DFT is called the
circular convolution and the linear convolution operation is of prime
interest in the analysis of LTI systems. In this chapter, the simula-
tion of the linear convolution operation by the circular convolution
operation was described. The overlap-save method of convolution
was also presented. Use of DFT is more efficient than the direct
method for almost all cases except when the impulse response is
very short. The implementation of correlation operation is very
similar to that of the convolution.
302
Convolution
and
Correlation
References
(1) Brigham,
E. O.
(1988)
The
Fast Fourier Transform
and Its
Appli-
cations, Prentice-Hall,
New
Jersey.
Exercises
14.1 Find
the
linear convolution
of the
sequences
x(n) =
{1,2,3}
and
h(n)
= {-2,3}
using
the DFT.
14.2 Find
the
circular convolution
of the
sequences
x(n) =
{1,2,3,4}
and
h(n)
=
{1,
-2,1,3} using
the DFT.
*
14.3
Using
the DFT,
find
the
linear convolution
of the
sequences
x(n
x
,n
2
)
=
2
1
3
4
-2
1
h(n
1
,n
2
)
=
2
3
1
4
14.4 Using
the DFT,
find
the
circular convolution
of the
sequences
x(n
1
,n
2
)
=
3
15-4
2
13-1
1-2 3 4
2
3 13
h{ni,n
2
)
1
4
2
1
4
5
3
0
2
-2
1
1
3
-3
4
5
14.5 Find
the
linear correlation
of
the sequences
x(n) =
{1,2,3}
and h(n) =
{-2,3}
using
the DFT.
14.6 Find
the
circular correlation
of the
sequences
x(n) =
{1,2,3,4}
and
h{n)
=
{1, -2,1,3} using
the DFT.
*
14.7
Using
the DFT,
find
the
linear correlation
of the
sequences
x(ni,n
2
)
=
2
15
3
4 2
-2
1 -3
h(ni,n
2
)
=
2
3
1
4
14.8 Using
the DFT,
find
the
circular correlation
of the
sequences
x(ni,n
2
)
=
3
15-4
2
13-1
1-2 3 4
2
3 13
h(ni,n
2
)
=
1
4
2
1
4
5
3
0
2
-2
1
1
3
-3
4
5

Chapter 15
Discrete Cosine Transform
For any processing, we prefer a signal to be represented by minimum num-
ber of values. This is particularly important for storage and transmission
of signals. The more compact the signal is coded, the more is the reduc-
tion of storage and bandwidth requirements. Although N values represent
a signal in both the time- and frequency-domains, the representation, in
general, is more compact in the frequency-domain. The reason is that most
of the energy of commonly occurring signals is contained in the lower part
of the spectrum. As periodicity is implied in the DFT, there could be large
discontinuity between the beginning and end of a period of a signal. This
discontinuity represents energy at high frequencies. The discontinuity can
be avoided by extending the signal so that it is even-symmetric. A signal
so constructed has its energy heavily concentrated in the lower part of the
spectrum. Although this procedure is a special case of the DFT, it is called
the discrete cosine transform (DCT) and is very widely used in signal and
image coding applications.
In Sec. 15.1, we examine the orthogonality property of the sinusoids
again to find out how we can define another transform, albeit closely related
to the DFT. We present the algorithms for the computation of 1-D and 2-D
DCT, respectively, in Sees. 15.2 and 15.3. These algorithms are essentially
DFT algorithms with few additional operations.
15.1 Orthogonality Property Revisited
It was stated in Chapter 2 that when the sum of the pointwise products
of two discrete signals is zero over a specified interval, the signals are said
303