Weston P. Bioinformatics Software Engineering: Delivering Effective Applications
Подождите немного. Документ загружается.

want other information provided back to them – how much data was
processed, how long the processing took, how many resources were
consumed, and other administrative, analytical, or system management
details.
But, for now, let us begin here by looking at our simple program,
and think how we would generate a summary report of the data that
we have read in – giving us the number of contigs in the assembly, for
instance.
Figure 9.2 is an example of a high-level process flow diagram. It con-
tains elements that we have already diagrammed in more detail, and
itself could make up one part of a larger application, like a complete
laboratory information management system.
Known and unknown coding
During the programming stage of the development lifecycle, it is likely
that you will find yourself involved in two different types of coding,
which I refer to as ‘known’ and ‘unknown’.
Known coding is where you are implementing a clear-cut design,
which details what data will be processed, and how.
Unknown coding is when you are finding out whether you can
perform some functionality with a particular piece of code, trying to
get a proof of concept to work, or attempting to come up with a solu-
tion to a problem.
Whatever type of coding you find yourself doing, and you will be
doing both at many stages of a project, it is important that you enjoy
each. Personally, I find sometimes I need to make the switch from one
to another according to how I feel; some days you feel more creative
than others, and those are good days to leap into the unknown.
And some problems are best solved by no coding – by stopping
wrestling with them for a while, and doing something more straight-
forward in order to give yourself a break and a better chance of return-
ing refreshed and more able to see a possible solution.
From designs to pseudocode
Depending on how happy you are with the languages and tools that
you will be using for the project, you may find it useful to write
pseudocode before you begin real coding.
FROM DESIGNS TO PSEUDOCODE 67
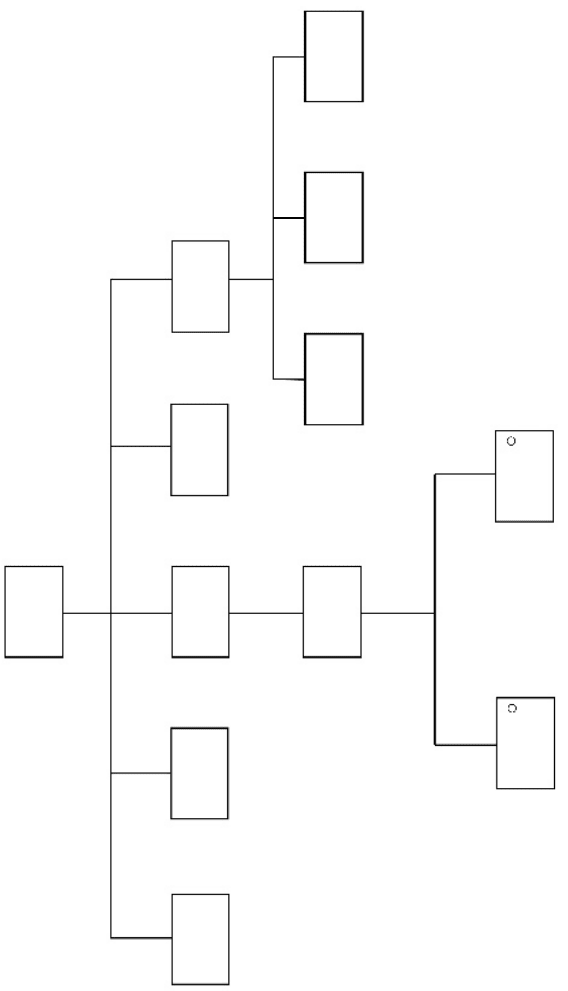
68 WHERE TO START?
Contig
Count = 0
Open
File
Close
File
Open
Report
Print
Contig
Count
Close
Report
Read Line
*
Create
Report
Produce
Report
Read
Lines
Until
End of
File
Contig
Count++
If New Contig
Continue
Otherwise
Figure 9.2 Process flow diagram: report construction
As you become more familiar with your tools, and more experienced
in application development, you may feel comfortable about skipping
this step and going straight into coding. However, writing pseudocode
can still sometimes help you get a clearer picture of how to implement
complex functionality, and comparing pseudocode to code is often a
useful way of clarifying why a program is not performing as it should.
So, what is pseudocode? Well, it is functionality defined with a subset
of everyday language. If you like, it is your program at a midway stage
between a written description of what is to happen and the executable
code that will actually do what is required.
Let’s look at some pseudocode for the program to create a report on
a sequence assembly. We’ll use the sub-process diagrams shown earlier
of handling file-opening errors and checking each line of the data, as
well as the high-level overview we’ve just seen.
/* Create report of assembly */
contig_count = 0
if exit_selected
exit
end if
/* Have we got a valid filename? */
unless valid( filename )
exit_message = “Invalid file name”
exit
end unless
/* If we can we open the file, read it in */
if open( filename )
/ * Read the file to its end */
until EOF
line = readline( filename )
/* Check for the start of a
contig’s details */
if contains( line, “Contig” )
contig_count++
end if
end until
close( filename )
FROM DESIGNS TO PSEUDOCODE 69
else
exit_message = “Can’t read file”
exit
end if
/* Generate the report */
if open( reportfile )
report = “Assembly contains”,
contig_count, “ contigs.”
print reportfile report
close reportfile
else
exit_message = “Couldn’t write report”
exit
end if
/* Validate a filename */
sub valid
filename = parameter[ 0 ]
/* Have we got any name at all? */
unless( filename )
return false
end unless
/* Is there a file called this? */
unless( exists( filename ) )
return false
end unless
/* At this point, we have a name that
points to a file */
return true
end sub
If you have trouble knowing how to start going from your diagrams
to pseudocode, start by writing the comments as descriptions of the
processing that the boxes and their connections represent, the decisions
that have to be made, or the conditions that must be checked. If even
this is problematic, are you sure you’ve done enough analysis to under-
stand what you’re supposed to be doing?
70 WHERE TO START?
From pseudocode to code
Pseudocode like that shown above can be more than halfway to the
real code that you are to implement – or it can be nothing like it at all,
depending on the syntax and grammar of the programming language
that you are going to use.
Whatever language you choose, some changes will have to be made
in the transition from one to the other. Variables will have to be
declared and initialized; brackets, braces and other appropriate punc-
tuation may well be needed; modules and libraries might have to be
called.
There may also be further modifications required which are
language- or platform-dependent. One area that may be affected by
these considerations concerns the syntax and style of implementing
input from, and output to, files and processes. Another involves how
you can access system error messages, extract useful information, and
return a helpful message to the user.
But, as we saw earlier, whatever you’re building, and whether you
write pseudocode or not, you needn’t ever worry again about where to
start. Handle errors. Take in data. Show output. Get going!
FROM PSEUDOCODE TO CODE 71

10
Functional, then
Optimized
This chapter emphasizes the importance of getting your code working,
and only then getting it working as well as it possibly can. It also
explores issues involved in the process of incremental delivery of
functionality.
Get it out of the door, and in front of your customers, as soon
and as often as safely possible
‘Safely’ is the important word here.
Let’s just step back a little.
We have already looked at prototypes and proofs of concept, and
discussed how they can help to keep your customers involved with the
project.
The point that needs emphasizing here is that it can be tricky decid-
ing when to hand over a deliverable to your customers. As a rough rule
of thumb, the time to let the customers see your program in action is
when you feel confident that all the new functionality will pass suc-
cessfully through the bulk of your tests.
It may be that you need to warn your customers that not all tests
have been successfully completed, or that this version of the software
has only been tested under special conditions – with one particular
dataset, for example, or only on a minimal system configuration.
Bioinformatics Software Engineering: Delivering Effective Applications. Paul Weston
Copyright
2004 John Wiley & Sons, Ltd. ISBN: 0-470-85772-2
You will have to balance the need to demonstrate that you are pro-
gressing against the dangers of giving them software that is not ready
for release.
This one is always a tough call. On the one hand, there is the poten-
tial of positive feedback from the delivery. On the other, there are the
possible downside outcomes – such as an unexpected program termi-
nation during the grand finale of your most senior customer’s pitch to
potential investors in their venture.
One way that is sometimes suggested for avoiding such pitfalls in
releasing early versions of software, which you might want to consider
and assess against the resources and requirements of your situation, is
to set up a small internal web site that guides visitors through the
various screens which (if all goes well) your users will encounter in the
real program.
But the trouble with this sort of solution is that you just end up
swapping the risks of users finding bugs in your program for the risk
of users finding bugs in the web site that demonstrates your program.
I would stick to fixing functionality, and, rather than spend time
designing a web site navigable by your customers, plan a show that you
can lead them through.
Planning shows
There are advantages to demonstrating new functionality to users
under controlled conditions – by showing it in a presentation, rather
than giving them the new version to play with. You have more control
over what they see of the software, and you can structure what they
see for maximum impact; you are also on hand to answer any ques-
tions that they may have as you demonstrate to them the new features
of this release.
However, this is not a matter to be approached lightly. You need to
plan what you will show and this planning will itself show – but it
won’t be half as apparent as a lack of planning would be. Make sure
that you have considered the following aspects.
Datasets
Again, only use data that you have tested your program on. The last
thing you want in a demonstration is something bizarre happening
74 FUNCTIONAL, THEN OPTIMIZED
because you are trying to process data you have never encountered
before. Feel confident you can handle it? Remember, errors will happen.
Controls
When something needs clicking on, ensure that the person clicking on
it has practised enough times to know what should then happen. This
is a show, not a test.
So senior people leading a demonstration, or presentation, should
hold their audience spellbound with their oratory, needing merely
a brief nod to their assistant at the side of the stage (who is the
one that knows which button to press when) in order to display the
next scene in the unfolding story of ‘What this software means for
you!’.
Visibility
Think about what you do and don’t want people to see, from what is
on the screen to what is on the walls.
Your customers will take many factors into account when they con-
sider your demonstration, from the clothes that you and your col-
leagues wear, to whether you are interrupted.
If your physical development environment isn’t particularly salubri-
ous – for instance, you work in a windowless concrete-walled room on
an anonymous industrial estate – consider a neutral venue which offers
more comfort and refinement.
If you show functionality to customers, they will want to take it away
and play with it. If you feel brave enough to do this, at least give them
the sample dataset that you used in the most recent demonstration,
explain that you cannot yet guarantee how it will behave on any other
data, and get ready for bug reports.
When not to display work in progress – getting them used to
having it
Once you have made a delivery of functionality, make sure that your
users have enough time to explore it in full and get to grips with what
it does before you give them more. Better still, sort out any problems
WHEN NOT TO DISPLAY WORK IN PROGRESS 75
that they identify and give them the corrected version before making
another offering.
This approach has two advantages – you and they can both be happy
that what they have so far works; and you can put more work into the
next delivery and make sure it is as right as you can get it.
Customer retention and repeat buyers
There is an old adage that it is more difficult to get a new customer
than to keep an old one. Your existing customers know what you can
do, and as long as you can keep them happy they are more likely to
come back to you when they want more work done.
The better you understand your customers, the more you can antic-
ipate their needs and reactions, and the closer a match there will be
between what they want and what you give them. If they always like
to start meetings with coffee and a chat, let them; if they want to get
straight down to business, follow their lead.
However, you should not try to sell them the next version of the soft-
ware before you have proved to their satisfaction that you can suc-
cessfully deliver version 1. Why? Well, one good reason is that when
you start telling them about your ideas for version 2, you can bet that
they will want the best bits straight away – and these will almost cer-
tainly be the most difficult to implement.
Instead, put yourself in their shoes. Think about the places where
you are a customer, and try and analyze why it is you go there rather
than elsewhere. Is there some way you can reproduce these sorts of
benefits for your customers?
For instance, you may always use a particular store because it is the
most convenient for you to get to. Maybe you should think about
taking the next demonstration to your customers, rather than getting
them to come to you?
And don’t underestimate the power of lunch as an offensive weapon.
After a good lunch, customers may well be inclined to focus more on
the positive aspects of a situation. You yourself will probably remem-
ber times when tiredness, hunger, or other preoccupations made you
more picky and irritable than usual. Try and minimize the effects of
any factor that may make it more difficult to bring your customers and
users along with you.
76 FUNCTIONAL, THEN OPTIMIZED
Optimization: benchmarking, assessment,
refinement, hardware
Once you have got basic functionality – such as a piece of proof-of-
concept code – then you can look at optimizing it. However, don’t rush
into this. The time to make things work better is when they aren’t
working properly, not when their performance is acceptable. For
example, you should not waste any of your finite amount of develop-
ment time making something faster until your customers complain
about its slowness.
Demonstrations of software to customers and users, with their
opportunities for instant feedback, can often indicate areas where
enhancements can be usefully implemented. For example, sections of
the program where the processing really does needs to be speeded up
are often indicated by comments such as ‘Why hasn’t anything hap-
pened yet?’
If there is a real requirement that program performance be improved,
then there are a number of techniques that you can call on.
First, find out where the bottlenecks in your code are, by printing
out the current time in between each section of code. This will tell you
which processes take up most time to perform, and allows you to focus
on the areas where your effort will have most impact.
Then look at your code, and at the algorithm behind it.
• Are your loops as efficient as possible, doing the minimum amount
necessary for the minimum number of times?
• Is there some way that you could end a loop early and still achieve
the desired results?
• Could you redesign what the program does so that the time-
consuming steps can be performed as a background task?
• Can you pre-calculate variable values, or cache results, in order to
speed things up?
Once you have refined your algorithms and their implementation so
that you feel no more improvement is possible, you may need to con-
sider hardware enhancements.
BENCHMARKING, ASSESSMENT, REFINEMENT, HARDWARE 77