Ahmed S.N. Physics and Engineering of Radiation Detection
Подождите немного. Документ загружается.


546 Chapter 9. Essential Statistics for Data Analysis
With f = kx,weget
∂f
∂k
2
= x
2
⇒
1
f
∂f
∂k
2
=
x
k
⇒
1
0
1
f
∂f
∂k
2
dx =
1
2k
.
Substituting this in the above relation for N gives
N =
1
(k)
2
1
2k
.
But we have k =0.21 and k =0.05k =0.0105, which gives
N =
1
(0.0105)
2
1
(2)(0.21)
=2.1 × 10
4
.
9.4 Confidence Intervals
Suppose we have a rough idea of the activity level in a radiation environment and
we use this information to estimate the dose that we expect a radiation worker to
receive while working there for some specific period of time. The problem with this
scheme is that there are a number of uncertainties involved in the computations,
such as level of actual activity, its space dependence (the radiation sources might
not be isotropic), and its variation with time. In such a situation what can be
done is to define a confidence interval within which the value is expected to lie with
a certain probability. For example, we can say that there is 90% probability that
the person will receive a dose of somewhere between 10-20 mrem.Herewehave
two parameters that we are reporting: the confidence interval and its associated
probability. The choice of a confidence interval is more or less arbitrary, although
generally it is based on some rationale, such as our rough estimation based on
some known parameters (in our example, we might have gotten a value of 15 mrem
and then decided to give ourselves a leverage of ±5 mrem to compensate for any
uncertainty in the calculations.). The probability, on the other hand, depends on
the confidence interval and the probability distribution.
If the probability distribution of a variable x (such as dose) is given by L(x), then
the probability that x lies between x
1
and x
2
is given by
P (x
1
<x<x
2
)=
x
2
x
1
L(x)dx
∞
−∞
L(x)dx
. (9.4.1)
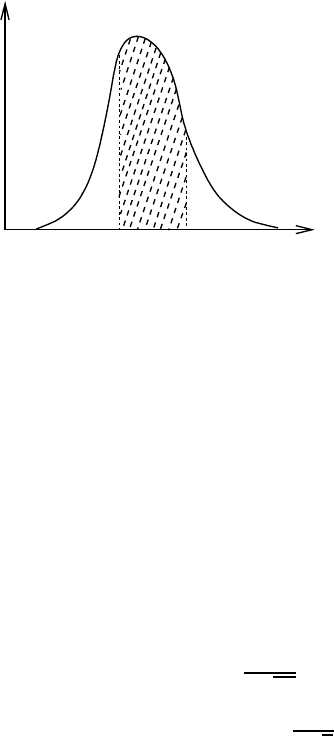
9.4. Confidence Intervals 547
If the function L(x) is normalized, then the denominator becomes 1 and the
probability is simply given by
P =
x
2
x
1
L(x)dx. (9.4.2)
This probability is actually the area under the curve of L(x) versus x between
the points x
1
and x
2
and therefore depends on the choice of the confidence interval
(see Fig.9.4.1).
x
1
x
2
x
L
(x)
Figure 9.4.1: The probability that a
value x lies within a confidence interval of
(x
1
,x
2
) is obtained by dividing the area
under the curve (shaded section) by the
total area. If the distribution is nor-
malized then the denominator will be 1
and the shaded area will simply be the
required probability. This probability,
therefore, depends on the choice of con-
fidence interval. In practice, the proba-
bility is first selected and then the confi-
dence interval is obtained from the cumu-
lative distribution function of the proba-
bility distribution.
We saw above that the choice of confidence interval is arbitrary while the prob-
ability depends on it. Therefore one would assume that the interval is first chosen
and then the probability is calculated. However the general practice is quite the
opposite. If it is known that the process under consideration has a certain probabil-
ity distribution then the probability is first chosen and then the confidence interval
is deduced from some available tables or curves. For example, for Gaussian dis-
tribution, which is the most commonly used distribution, the tables of probability
integrals are used to find the confidence intervals.
Let us now take a look at the example of a normally distributed variable x
having mean µ and variance σ
2
. We are interested in finding the probability that
the measured value lies between µ − δx and µ + δx. This probability, according to
the definition above, can be evaluated from
P =
1
σ
√
2π
µ+δx
µ−δx
e
−(x−µ)
2
/2σ
2
dx
= erf
δx
σ
√
2
. (9.4.3)
Here erf (u)istheerror function of u, whose values are available in tabulated
form in standard texts. To get a feeling of what different values of P would mean
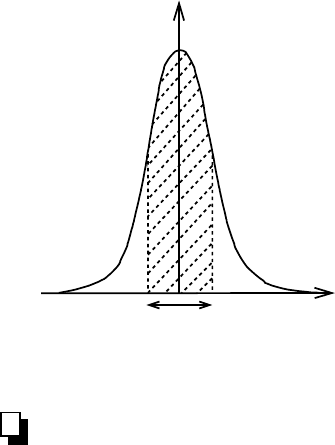
548 Chapter 9. Essential Statistics for Data Analysis
with respect to σ,welookatsometypicalvalues.
P (µ − σ<x<µ+ σ)=0.6827
P (µ − 2σ<x<µ+2σ)=0.9545
P (µ − 3σ<x<µ+3σ)=0.9973
What these values essentially show is that if the data can be represented by
a perfect Gaussian distribution, then we can be only 68.27% sure that the next
measurement will lie within the range µ ±σ. However if we wanted to be more than
99% sure about this we will have to stretch the range to around 3σ on both sides of
the distribution. Fig.9.4.2 explains this concept in graphical form.
f(x)
σ
2
x
Figure 9.4.2: Confidence interval of a stan-
dard Gaussian distribution. The shaded area
represents the probability that the next mea-
surement of x will lie within the interval µ−σ<
x<µ+ σ. For a perfect Gaussian distribution
this turns out to be 0.6827 meaning that one
could be up to 68.27% sure that the value will
not be out of these bounds.
9.5 Measurement Uncertainty
There is always some uncertainty associated with a measurement no matter how
good our measuring device is and how carefully we perform the experiment. There
are different types of uncertainties associated with any measurement but they can
be broadly divided into two categories: systematic and random.
9.5.A Systematic Errors
All measurements, direct or indirect, are done through some type of measuring de-
vice. Since there is no such thing as a perfect device, therefore one should expect
some error associated with the measurement. This type of error falls into the cate-
gory of systematic errors, which refer to the uncertainties in the measurement due
to the measurement procedures and devices. Unfortunately it is not always easy
to characterize systematic errors. Repeating the measurements does not have any
effect on them since they are not random. In other words, systematic errors are not
statistical in nature and therefore can not be determined by statistical methods.
The good thing is that the systematic uncertainties can be minimized by modi-
fying the procedures and using better devices. For example, one can use a detector

9.5. Measurement Uncertainty 549
having better accuracy or, in case of a gas filled detector, improve on its accuracy by
using a more efficient gas mixture. Similarly easy steps can be taken to decrease the
systematic uncertainties associated with readout electronics. An obvious example of
that would be the use of an ADC having better resolution. Another way to decrease
the systematic uncertainty is to properly calibrate the system.
Systematic uncertainties are system specific and therefore there is no general
formula that could be used for their characterization. It is up to the experimenter
to carefully determine these errors and faithfully report them in the final results.
9.5.B Random Errors
Random errors refer to the errors that are statistical in nature. For example, the
radioactive decay is a random process. Even though we know the average rate of
decay of a sample, we can not predict when the next decay will happen. This implies
that there is an inherent time uncertainty associated with the process. Similarly the
production of charge pairs in a radiation detector by passing radiation is also a
random process (see chapter 2). We can say that on the average how many charge
pairs will be produced by a certain amount of deposited energy but we can not
associate an absolute number to it. Such uncertainties that are inherent to the
process and are statistical in nature are categorized as random uncertainties.
Fortunately most physical processes are Poisson in nature. This makes is fairly
easy to estimate the random error associated with a measurement. The random
error associated with a measurement during which N counts were recorded, is given
by
δ
stat
=
√
N. (9.5.1)
For example, let us suppose that we measure the activity of a radioactive sample
by taking three consecutive readings by a single channel analyzer/counter: 2452,
2367, 2398. The absolute random errors associated with these measurements will
be:
δ
stat,1
=
√
2452 = 49.52
δ
stat,2
=
√
2367 = 48.65
δ
stat,3
=
√
2398 = 48.97
9.5.C Error Propagation
Let us suppose we perform an experiment and make N independent measurements
x
i
each having uncertainty δx
i
and standard deviation sigma
x
i
. We then use these
measurements to evaluate some function u = f (x
1
,x
2
, ..., x
N
). The question is: how
can we estimate the standard deviation and error in the quantity we thus determine?
This is where the error propagation formulae come into play, according to which the
combined variance and standard error in the function u can be evaluated from
σ
2
u
=
∂f
∂x
1
2
σ
2
x
1
+
∂f
∂x
2
2
σ
2
x
2
+ .... +
∂f
∂x
N
2
σ
2
x
N
(9.5.2)
and δ
u
=
∂f
∂x
1
2
δx
2
1
+
∂f
∂x
2
2
δx
2
2
+ .... +
∂f
∂x
N
2
δx
2
N
1/2
. (9.5.3)
550 Chapter 9. Essential Statistics for Data Analysis
These general relations can be used to derive formulae for specific functions as
shown below.
C.1 Addition of Parameters
Suppose we have u = x
1
+ x
2
+ .... + x
N
. In this case the derivatives of u = f (x)
will be given by
∂f
∂x
1
=
∂f
∂x
2
= .... =
∂f
∂x
N
=1. (9.5.4)
Equation 9.5.3, then reduces to
δ
u
=
δx
2
1
+ δx
2
2
+ .... + δx
2
N
1/2
, (9.5.5)
which states that the total error in the measurement will simply be equal to the
square root of the sum of individual errors squared.
Note that the above formula also holds if the some or all of the parameters have
negative signs. In other words, the formula remains the same whether the parameters
are added or subtracted in the function.
C.2 Multiplication of Parameters
Let us now see how the errors propagate if the function has the multiplicative form.
For simplicity we will restrict ourselves to two variables, that is, we will assume that
u = x
1
x
2
. In this case the derivatives of u = f (x) will be given by
∂f
∂x
1
= x
2
(9.5.6)
and
∂f
∂x
2
= x
1
. (9.5.7)
Substituting these values into equation 9.5.3 gives
δ
u
u
=
δx
1
x
1
2
+
δx
2
x
2
2
1/2
. (9.5.8)
The generalized form of this equation for N parameters is given by
δ
u
u
=
δx
1
x
1
2
+
δx
2
x
2
2
+ .... +
δx
N
x
N
2
1/2
. (9.5.9)
Note that here δ
u
/u refers to relative error. For absolute error this must be multiplied
by u. What the above formula tells us is that the relative error in the measurement of
N independent measurements is simply the square root of the sum of the individual
relative errors squared.
The reader can verify that the above formula does not change its form in case of
division. For example, the error in u = x
1
x
2
/x
3
can be determined from the above
formula without any modifications.
9.6. Confidence Tests 551
9.5.D Presentation of Results
Now that we know how to calculate errors associated with parameters by using errors
in individual measurements, we should discuss how to present our final results. We
saw earlier that there are basically two classes of errors: systematic and random.
Though it is a common practice to combine both errors together in the final result
but a better approach, as adopted by many careful experimenters, is to explicitly
state them separately. For example, the result of an experiment might be represented
at 1σ confidence as
ξ = 205.43 ±6.13
syst
± 14.36
rand
,
where the superscripts syst and rand stand for systematic and random errors respec-
tively.
A word of caution here. By looking at the above numbers, one might naively
conclude that all the values would lie between 205−6.13−14.36 and 205+6.13+14.36.
This is not really true. Earlier in the chapter we discussed the confidence intervals
and we saw that, for normally distributed data, a 1σ uncertainty guarantees with
only about 68% confidence that the result lies within the given values (that is,
between
¯
ξ −σ and
¯
ξ + σ). For higher confidence, one must increase the σ-level.For
example, for a 99% confidence, the above result will have to be written as
ξ = 205.43 ±6.13
syst
± 43.08
rand
,
where we have multiplied the random error of 1σ by a factor of 3. Note that, since
systematic uncertainty does not depend on statistical fluctuations, there is no need
to multiply it by any factor. Now we can say with 99% confidence that the value of
the parameter lies between 205 − 6.13 − 43.08 and 205 + 6.13 + 43.08.
9.6 Confidence Tests
Computing different quantities from a data set obtained from an experiment is
helpful in understanding the characteristics of the system but if we have a certain
bias about the behavior of the system we might also want to judge the data against
our hypothesis. This judgment can be qualitative, such as just a visual sense of how
the data looks like with respect to the expectation, or quantitative, which is the
subject of the discussion here.
To judge a data sample quantitatively against a hypothesis we perform the so
called confidence or goodness-of-fit test. For this we first define a goodness-of-fit
statistic by taking into account both the data and the hypothesis. The idea is
to have a quantity whose probability of occurrence could tell us about the level of
agreement between the data and the hypothesis. Of course the choice of this statistic
is arbitrary but several standard functions have been generated that can be applied
in most of the cases. Before we look at some of these functions, let us first see how
the general procedure works.
Let us represent the goodness-of-fit statistic by t such that its large values corre-
spond to poor agreement with the hypothesis h. Then the p.d.f g(t|h)canbeused
to determine the probability p of finding t in a region starting from the experimen-
tally obtained value t
0
up to the maximum. This is equivalent to evaluating the

552 Chapter 9. Essential Statistics for Data Analysis
cumulative distribution function
p ≡ 1 − P (t
o
)=1−
t
o
−∞
g(t|h)dt or
p =
∞
t
o
g(t|h)dt (9.6.1)
A single value of p, however, does not tell us much about the agreement between
data and hypothesis because at each data point the level of agreement could be
different. The trick is to see how the value of p is distributed throughout its range,
that is, between 0 and 1. Of course if there is perfect agreement, the distribution
will be uniform.
Let us now take a look at some of the commonly used goodness-of-fit statistics.
9.6.A Chi-Square (χ
2
)Test
This is perhaps one of the most widely used goodness-of-fit statistic. In the following
we outline the steps needed to perform the test.
1. The foremost thing to do is to construct a hypothesis, which has to be tested.
This hypothesis should include a set of values µ
i
that we expect to get if we
perform measurements and obtain the values u
i
. These set of values may have
been derived from a known distribution that the system is supposed to follow.
2. Decide on the number of degrees of freedom. If we take N measurements, the
degrees of freedom are not necessarily equal to N because there may be one
or more relations connecting the measured values u
i
.Ifthenumberofsuch
relations are r, then the degrees of freedom will be given by ν = N −r.
3. Using the measured values u
i
, compute a sample value of χ
2
from the relation
9.3.53
χ
2
=
N
i=1
(u
i
− µ
i
)
2
σ
2
i
.
4. Compute the normalized χ
2
,thatis,χ
2
/ν.
5. Decide on the acceptable significance level p, which represents the probability
that the data is in agreement with the hypothesis or not. A commonly chosen
value of p is 0.05, which gives a confidence of 95%.
6. Determine the value of χ
2
ν,p
at which p is equal to the chosen value. This means
evaluating the integral
p =
∞
χ
2
ν,p
f(x)dx (9.6.2)
for χ
2
ν,p
(see also equation 9.6.1). f(x)isofcoursetheχ
2
probability den-
sity function. The solution to this equation requires numerical manipulations,
which can be done, for example by employing the Monte Carlo integration
technique. However this is not generally done since there are tables and graphs
available that can be used to deduce the values of χ
2
ν,p
with respect to p and ν.

9.6. Confidence Tests 553
7. Compare χ
2
/ν with χ
2
ν,α
/ν.
Let us now see what we can infer from this comparison.
Case-1, χ
2
/ν χ
2
ν,α
/ν: We are up to α ×100% confident that our hypothesis
was correct.
Case-2, χ
2
/ν > χ
2
ν,α
/ν: This may mean one of the following.
1. The model we have chosen to represent the system is not adequate.
2. The model is adequate but there are some bad data points in the sample.
It takes only a few large excursions in the data that are far away from the
mean to yield a large value of chi-square. Care should therefore be taken
to ensure that proper filtration of the data is performed to eliminate such
data points.
3. The data values are not uniformly distributed about their means. The is
the most troubling scenario, since it would mean that this goodness-of-fit
method is not really applicable and we should either resort to some other
method or look closely at the data to find out if just a few values are
causing this deviation from the normal distribution. Generally, discarding
a few data points does the trick.
Case-3, χ
2
/ν < χ
2
ν,α
/ν: This means that the squares of the random normal
deviates are less than expected, a situation that demands as much attention as
the previous one. The following possibilities exist for this case.
1. The expected means were overestimated. This does not mean that the
model was wrong.
2. There are a few data points that have caused the chi-square value to
become too small.
9.6.B Student’s t Test
Student’s t test is the most commonly used method of comparing the means of
two low statistics data samples. To perform the test, first the following quantity is
evaluated.
t =
| ¯x
1
− ¯x
2
|
σ
12
(9.6.3)
Here ¯x
1
and ¯x
2
represent the means of first and second datasets and σ
12
is the
standard deviation of the difference between the two means. It can be computed
from
σ
12
=
σ
2
1
N
1
+
σ
2
2
N
2
1/2
, (9.6.4)
where σ
1
and σ
2
are the standard deviations of the two datasets having N
1
and N
2
number of data points. Note that here what we have done is to simply taken the
square root of the sum of the standard errors associated with each dataset.
The next step is to compare the calculated t-value with the tabulated one. The
tabulated values, derived from the Student’s t distribution we presented earlier, are

554 Chapter 9. Essential Statistics for Data Analysis
generally given for different degrees of freedom and levels of significance. The total
degrees of freedom for the dataset are given by
ν =(N
1
− 1) + (N
2
− 1)
= N
1
+ N
2
− 2. (9.6.5)
The choice of level of significance depends on the level of confidence one intends to
have on the analysis. If one chooses a value of 0.05 and the calculated t value turns
out to be less than the tabulated one, then one could say with 95% confidence that
the means are not significantly different.
Example:
An ionization chamber is used to measure the intensity of x-rays from an
x-ray machine. The experiment is performed at two different times and yield
the following values (arbitrary units).
Measurement-1: 380, 398, 420, 405, 378
Measurement-2: 370, 385, 400, 419, 415, 375
Perform Student’s t test at 95% and 99% confidence levels to see if the means
of the two measurements are significantly different from each other.
Solution:
First we compute the means of the two datasets.
¯x
1
=
N
1
i=1
x
1,i
N
1
= 396.2
¯x
2
=
N
2
i=1
x
2,i
N
2
= 394
Next we determine the standard deviations of the two means.
σ
1
=
1
N
1
− 1
N
1
i=1
(x
1,i
− ¯x
1
)
2
=17.61
σ
2
=
1
N
2
− 1
N
2
i=1
(x
2,i
− ¯x
2
)
2
=20.59

9.7. Regression 555
The standard deviation of the mean is given by
σ
12
=
σ
2
1
N
1
+
σ
2
2
N
2
1/2
=
17.61
2
5
+
20.59
2
6
1/2
=11.52.
Now we are ready to compute the t value.
t =
|396.2 −394|
11.52
=0.191
To compare this t value with the tabulated values we must first determine the
degrees of freedom of the dataset. This is given by
ν = N
1
+ N
2
−2
=5+6− 2=9.
For a 95% confidence level and 9 degrees of freedom the tabulated t value is
2.26. And for a 99% confidence level the tablulated t value is 1.83. Since
both of these values are greater than the calculated t value of 0.19, therefore
we can say with at least 99% confidence that the two dataset means are not
significantly different.
9.7 Regression
Regression analysis is perhaps the most widely used technique to draw inferences
from experimental data. The basic idea behind it is to fit a function that closely
represents the trend in the data. The function can then be used to make predictions
about the variables involved.
Fitting a function to the data through regression analysis is not always a very
pleasant experience, specially if the data shows variations that can not be charac-
terized by standard functions, such as polynomial, exponential, or logarithmic. The
easiest form of regression analysis is the simple linear regression, which we will dis-
cuss in some detail now. Later on we will look at other kinds of regression analysis.
9.7.A Simple Linear Regression
Simple linear regression refers to fitting a straight line to the data. The fitting
is mostly done using a technique called least square fitting. To understand this
technique, let us start with the equation of a straight line
y = mx + c, (9.7.1)
where m is the slope of the line and c is its y-intercept. Since slope and y-intercept
determine the orientation and position of the straight line on the xy-plot, therefore