Kortum P. (ed.) HCI Beyond the GUI. Design for Haptic, Speech, Olfactory, and Other Nontraditional Interfaces
Подождите немного. Документ загружается.

An immersive interface would be like driving a car, where the driver does not
focus on the interaction of the car but becomes as one with it.
It is challenging to use device-free interaction, as the tactile sensory feedback
is difficult to provide. It is as if the somesthetic sense is lacking, such as in a
disabled patient, as follows:
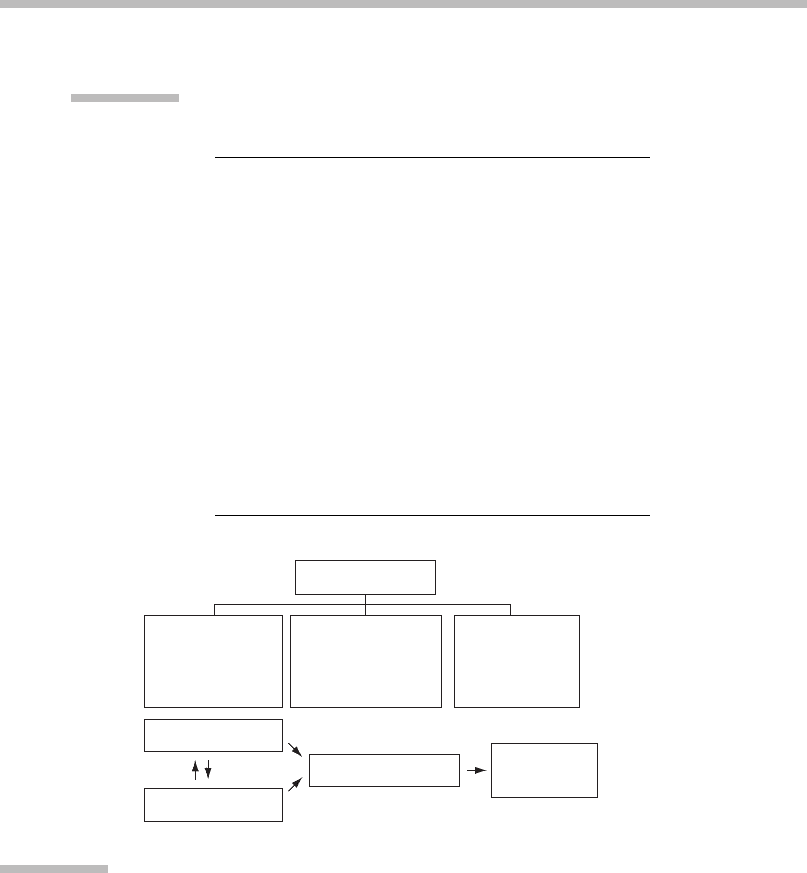
Expectations
Context
World Geometry
Application
activity
Senses
Expectations
Memory
Grammar
Semantics
History
Personal
Attribution
User
configuration
Interpretation
Sensory
feedback
FIGURE
3.6
Understanding sensory data.
Interpretation of integrated senses relies on expectations, which also direct the
focus of attention of the senses. Possible expectations of interpretation system
on a computer.
TABLE 3.1 The Five Senses and Relevant Information about
Surroundings
Sense Relevant Information
Audio Speech
Identity
Intonation
Precision (timing)
Vision Identity
Facial expression
Body language
Gesture
Accuracy (spatial)
Tactile/somesthetic Tabs, pads, devices
Texture
Precision (timing)
Accuracy (spatial)
Scent Atmosphere, likability
Taste Clarification, enjoyment
3 Gesture Interfaces
82
F Loss of the capability to sense limb movement and position.
F Major impairment in skilled performance, even with full vision and
hearing. This is worsened as visual information degrades.
F Abnormal movements and the inability to walk following the loss of
somesthesis.
F Patients must exert immense effort to relearn how to walk.
F Major loss of precision and speed of movement, particularly in the hands.
F Major difficulty performing tasks that combine significant cognitive loads
and fine motor skills such as writing minutes during meetings.
F Major difficulty learning new motor tasks, relearning lost ones, or using
previous experience to guide these processes (Tsagarakis et al. 2006).
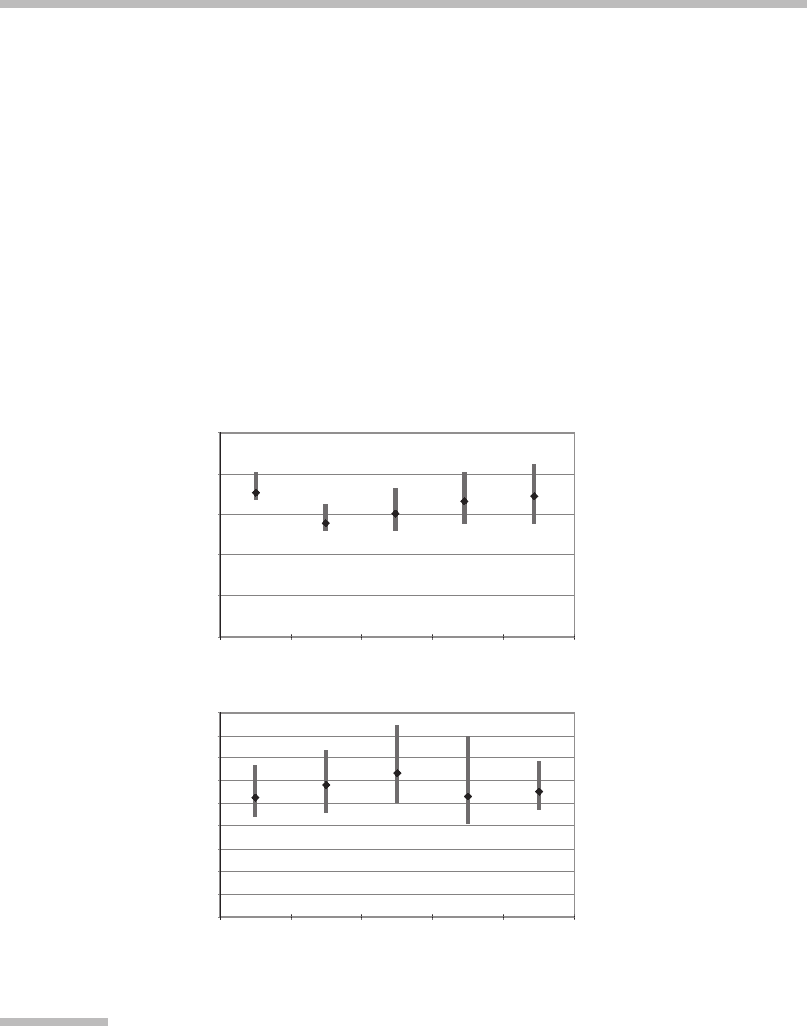
Figure 3.7 shows results from Tsagarakis et al. (2006), who designed a virtual sur-
gical knife through a physical handheld device posing as the knife. They found
0.45
0.40
0.35
0.30
0.25
0.20
0.15
0.10
0.05
0
Distance error (mm)
(b)
User
12345
Distance error (mm)
0.025
0.020
0.015
0.010
0.005
0
User
(a)
12345
FIGURE
3.7
Results of testing a virtual surgical knife.
The accuracy of the surgical knife is measured in millimeters for five test users.
(a) Test performed using haptic and visual feedback. (b) Test using only visual
feedback.
Source:
From Tsagarakis et al. (2006);
#
2006 IEEE.
3.3 Fundamental Nature of the Interface
83

that the gesture accuracy improved 15-fold by adding tactile feedback when the
virtual knife hit the virtual flesh.
Applying such feedback to accessory-free gesture interfaces such as a virtual
reality CAVE (an environment in which the user is surrounded by back-projected
screens on all four sides, ceiling, and floor) with camera-based tracking of body
parts will be challenging. Tactile (or haptic) feedback is often given through phys-
ical contact with accessory devices via vibrations (Caldwell et al., 1999; Langdon
et al., 2000). However, device-free tactile feedback could also be possible through
subsonic sound waves (Mu
¨
ller-Tomfelde & Steiner, 2001). Using this approach
could enable usage in applications where physical and wired devices would be
unnatural.
A common solution is to use visual and audio feedback, but these are not tac-
tile. Another solution could be to research the usage of directed low-frequency
audio waves, as this would feel like tactile feedback.
Spatial versus Temporal Perceptive Relation and Precision
A popular solution in multimodal interface studies is the complementary usage
of speech and gesture. These modalities complement each other well because
vision relates mainly to sp atial perception, while sound r elates mainly to tempo-
ral perception. For example, an experiment was conducted where test subjects
saw a dot blinking once on the monitor while hearing two clicks within a certain
time frame (Vroomen & Gel der, 2004). The result was that the test subjects
perceived two blinks and e ven three blinks when the sound clicked thrice.
This demonstrated a c lear complementary merging of senses with a dominant
audio cue for temporal cogniti on. But humans are muc h better at establishing
distance and direction from visual cues than from auditory cues (Loomis et al.,
1998).
When you design a visual- and an audio-based detection and synthesis system
synchronization problems can arise because their response times may be different.
A physically accurate detection and synthesis model tends to reduce response time
performance. Long response time can cause ambiguity and error between the
modes, while good synchronization solves ambiguity and minimizes errors.
Consider an elaborated example such as a virtual-reality application where
you can pick up items for various tasks. A voice recognition system reacts to the
phrase “Pick up” to trigger this action, and the application uses your hand position
to identify the virtual item. However, you move your hand slightly fast, because
you are going to do a lot of work. The visual recognition system lags behind,
which causes a 0.5-second discrepancy between the hand position and where
the application thinks you are. Furthermore, the speech recognition might have
a 1.5-second lag. If you say “Pick up” when your real hand is on top of the virtual
object, your hand has moved on from the item that you wanted and you may pick
up another item or none at all. If it were a menu item, you might have chosen
Delete everything instead of Save.
3 Gesture Interfaces
84

3.3.2 Gesture Taxonomies
A number of taxonomies on gestures are found in the literature. The best one for
use in a given application depends on the concrete context. Basically, there are
three ways of labeling gestures:
Semantic
labels describe the meaning of the gesture, that is, what it communicates
and its purpose. Commonly used in nonverbal communication studies.
Functional
labels describe what the gesture does in an interface. Commonly
used in technical human–computer (HCI) descriptions.
Descriptive
labels describe how the gesture is performed, such as its movement.
Commonly used in technical HCI descriptions.
Semantic Labels
Semantic labels, as described by Cassell (1998), can be conscious or spontaneous.
Furthermore, they can be interactional or propositional. Conscious gestures have
meaning without speech, while spontaneous gestures only have meaning in the
context of speech. Examples of conscious gestures follow:
Emblems
are conscious communicative symbols that represent words. These are
interactional gestures. An example is a ring formed by the thumb and index fin-
ger. In Western culture this means “Okay,” and in Japan it means “Money.”
Propositional
gestures consciously indicate places in the space around the per-
former and can be used to illustrate size or movement. Examples include “It
was this big” (using a propositional gesture to show the size) or “Put that there.”
Spontaneous
gestures are less controllable and emerge spontaneously as the
sender is engaged in an interaction:
F
Iconic
gestures are illustrations of features in events and actions,
or how they are carried out. Examples are depicting how a handle was
triggered or looking around a corner.
F
Metaphoric
gestures are like iconic gestures, but represent abstract
depictions of nonphysical form. An example is circling the hand to
represent that “The meeting went on and on.”
F
Deictic
gestures refer to the space between the narrator and the listener(s).
For instance, these can point to objects or people being discussed or refer to
movement or directions. They can also be used in a more abstract way,
such as in waving away methods, “We don’t use those,” and picking desired
methodsasin“Thesearewhatweuse.”These gestures are mainly spontaneous,
but can also occur consciously, such as when pointing at an object.
F
Beat
gestures are used to emphasize words. They are highly dynamic,
as they do not depict the spoken messages with postures. An example is
when the speaker makes a mistake and then corrects him- or herself while
punching with the hand.
3.3 Fundamental Nature of the Interface
85

Cassell (1998) states that emblems and metaphoric gestures are culturally
dependent, while other types are mostly universal, although some cultures use
them more than others. Asian cultures use very little gesturing while Southern
European cultures use a great deal.
The gestures that are generally relevant for machine interactions are deictic,
iconic, propositional, and emblems. This is because the applications have had
common themes such as conveying commands and manipulating and pointing
out entities. This observation leads to functional labels.
Functional Labels
Functional labels explain intended usage in an application.
Command
gestures access system functions in an application, such as Quit, Undo,
and Configure. Typically emblems can be used for these because their appear-
ance signals something specific.
Pointing
gestures are commonly deictic or propositional gestures that point out
entities in the space around the user. This is a core gesture type that is used
for selection. For example, if you want to buy something in a market and you
do not speak the local language, you might point to it.
Manipulation
gestures relate to functions that manipulate or edit the data space,
such as scaling or rotating an image or 3D model. Propositional gestures are
closely related to this type of interaction because they resemble the usage of
those gestures in nonverbal communication.
Control
gestures mimic the control over entities in the application such as avatar
or camera movements. Iconic, propositional, and deictic gestures can be used
because all are used when one person imitates another.
Descriptive Labels
Descriptive labels refer to the manner in which the gestures are performed in a
spatiotemporal sense.
Static
gestures are postures, that is, relative hand and finger positions, that do not
take movements into account. Any emblem can be seen as an example of a
static gesture, as in “Thumbs up.”
Dynamic
gestures are movements, that is, hand trajectory and/or posture swit-
ching over time. In nonverbal communication, dynamics in a gesture can alter
its meaning (Hummels & Stapiers, 1998) as it is commonly used in sign lan-
guage. A dynamic gesture can be defined by a trajectory that resembles a
figure (Figure 3.8) or simply a sequence of static gestures.
Spatiotemporal
gestures are the subgroup of dynamic gestures that move through
the workspace over time.
3 Gesture Interfaces
86
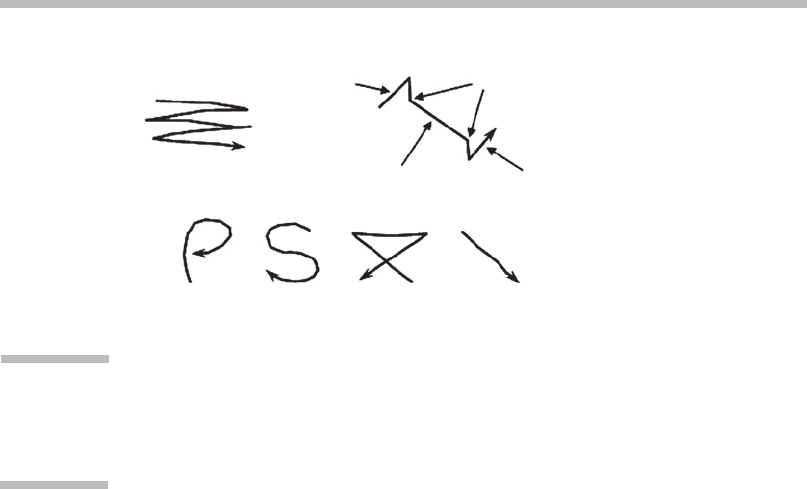
3.4
HUMAN FACTORS INVOLVED IN INTERFACE
DESIGN
One of the most difficult tasks is to find a feasible gesture vocabulary that is easy
for the user to remember and perform (Keates & Robinson, 1998). Sign language is
not convenient because the gestures are rather complicated, and sign languages
differ according to the underlying vocal language.
Limiting the vocabulary is important, and will benefit both users and designers.
Methods that can be used for this purpose follow:
Context dependence:
Available options vary with the context of the current selection.
This is similar to the context menu in Windows applications, where a right click
spawns a menu of items that are relevant only to the selected object. It is important
to make the state of the system visible to the user at all times in such interfaces.
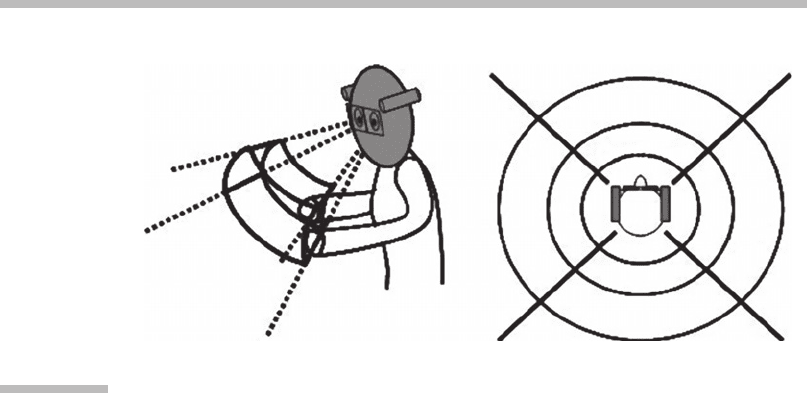
Spatial zones:
This method is known as the surround user interface (Figure 3.9).
The space around the user is divided into spatial zones, each of which has its
own context that defines the functions of the gestures. For example, command
gestures are close to the user and manipulation gestures are farther away.
Special utility functions could be stowed to both sides of the user, much like
stowing things away in pockets.
3.4.1 Technology- versus Human-Based Gestures
A typical approach to defining an application’s gesture vocabulary is to make it
easy for the computer system’s recognition algorithm to recognize the gestures.
The result of this approach for finding gestures can be called a technology-based
Start
Start cut
Pause
End cut
Cut
StopPrint ClearQuit
FIGURE
3.8
Dynamic gestures.
Examples of command gestures that are dynamic and spatiotemporal, as they
track the position of a hand or handheld device.
3.4 Human Factors Involved in Interface Design
87
gesture vocabulary. An example is to define a gesture by how many fingers are
stretched (Figure 3.10) because an algorithm has been developed that can count
extended fingers. These gestures together create a vocabulary that might be used
where there is no particular meaning to the gesture itself; in brief, the association
between gesture and meaning is arbitrary. On the other hand, it is easy to imple-
ment a computer vision–based recognizer for such gestures.
Table 3.2 shows two example applications in which functionalities have been
assigned to gestures. A neutral hand position that is not to be interpreted is called
“residue.”
Applications containing technology-based gestures have been implemented
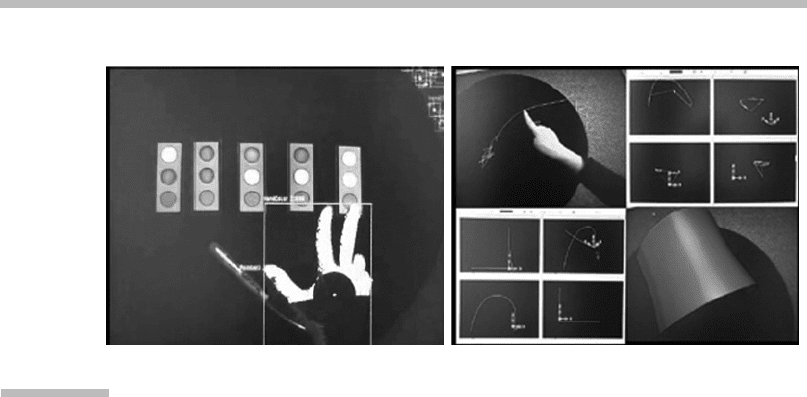
and tested. Figure 3.11 shows the interface of the application. The tests showed
that the gestures were inappropriate for one or more of the following reasons:
F Stressful/fatigue producing for the user
F Nearly impossible for some people to perform
F Illogically imposed functionality
As an alternative, the human-based gesture approach investigates the people who
are going to use the interface, and makes use of human factors derived from HCI
research, user-centered design, ergonomics, and biomechanics.
3.4.2 HCI Heuristics and Metaphors
Numerous guidelines for user-friendly designs are available. Usability can be
described using the following five parameters (Federico, 1999; Bevan & Curson,
Manipulation
Command
Utility Utility
FIGURE
3.9
Example of a surround user interface.
Left:
The command gesture shell is close to the user. Gestures are interpreted as
command gestures when the hands are inside the bent cube.
Right:
Gestures
performed farther away are interpreted as data manipulation gestures. Utility
functions are available at the sides of the user.
3 Gesture Interfaces
88

T0
T1
T2
T3
T4
T5
FIGURE
3.10
Technology-based gestures.
These gestures are easy for a computer to recognize using computer vision,
but they are difficult to relate to functions and some of them are difficult to
perform.
TABLE 3.2 Imposed Functionalities in Two Demo Applications
Application Gesture* Painting Object Handling
T0 Residue/release Residue
T1 Paint/select Select
T2 Copy and paste
T3 Delete
T4–T5 Menu Release
3.4 Human Factors Involved in Interface Design
89
1997; Nielsen, 1992): learnability, efficiency, memorability, errors, and coverage.
All parameters are important for the entire interface in which the gestures are
used, encompassing the structure, sequence, and feedback from the user inter-
face as well as the gestures themselves. Sequencing refers to the steps required
to get from one state to the goal state.
An example is word processing or file management. There are two methods to
move a section or file: Copy-Paste-Delete, or Cut-Paste. This is an example of
minimizing the steps in the sequencing. However, some people may prefer the
three steps because it provides added security by leaving the original in place in
case something goes wrong in the transaction.
The core of the human-based approach comprises the following characteris-
tics for the chosen gestures:
Intuitive:
Users can use the interface with little or no instruction.
Metaphorically or iconically logical toward functionality:
Users can easily see
what the gestures are for.
Easy to remember without hesitation:
Users focus on their tasks rather than on
the interface.
Ergonomic:
Not physically stressful when used often.
Because of the technical limitations of gesture recognition technology, it is even
more necessary to simplify the dialog and sequencing than it is with conventional
input methods. Furthermore, it is wise to keep in mind that the application must
be able to distinguish the different gestures. Hence, the principle from the tech-
nology-based gestures may have to direct the choice in the development of
human-based gestures to some extent.
FIGURE
3.11
Technology-based gesture.
A pointing gesture is used for shape creation in a computer-aided design tool.
Source:
From Moeslund et al. (2004).
3 Gesture Interfaces
90
3.4.3 Ergonomics and Intuitivity
Another way to approach the development of a gesture interface is to look into the
ergonomics and biomechanics of gesturing to ensure that a physically stressing
gesture is avoided. In this section the biomechanics of the hand (Lin et al., 2001;
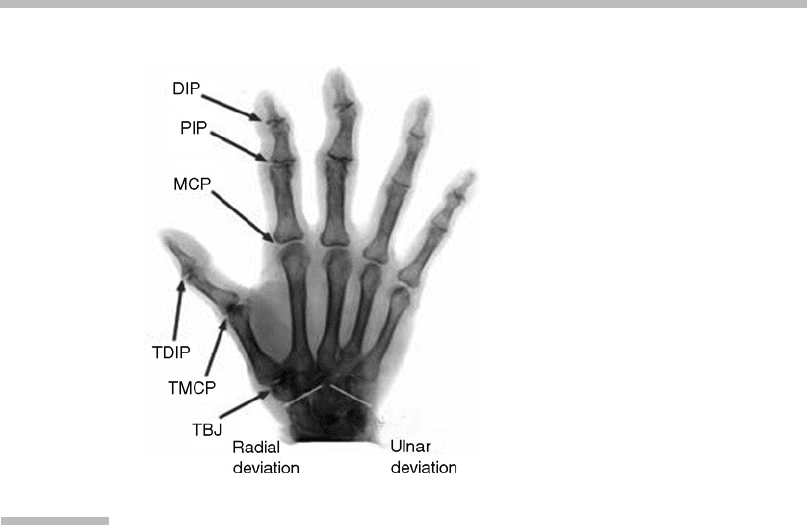
Lee & Kunjii, 1995) is described. Figures 3.12 and 3.13 show the terms used in this
section.
As a handy reference, Table 3.3 lists the ranges of motion for the joints
(Eaton, 1997) for the average hand in degrees, where zero degrees in all joint
angles is a stretched hand. An example of how to read the numbers follows: The
wrist extension/flexion of 70/75 means that the wrist can extend 70 degrees
upward and flex 75 degrees downward.
Hyperextension
means extending the joint farther than naturally by external
force.
Adduction
means moving the body part toward the central axis, which in
the hand is between the middle and ring fingers (i.e., gathering the fingers).
Abduction
means moving the body part away from the central axis (i.e., spreading
the fingers).
Pronation
and
supination
mean rotating the wrist around the fore-
arm. If the neutral position faces the palm sideways,
pronation
faces the palm
downward and
supination
faces it upward.
FIGURE
3.12
X-ray of a right hand showing joint name abbreviations and wrist
movement.
3.4 Human Factors Involved in Interface Design
91