Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


the testing set. Sometimes, gallery is also called target
set, while probe set is also called query set, e.g., in
FRGC [3].
When collecting biometric samples in the above-
mentioned four datasets, some points should be
considered carefully. First, the samples in the gallery
should never be included in the probe set also, since
this will definitely result in correct match. Secondly,
whether the samples in the testing set should be
contained in the training set is task-dependent.
Thirdly, whether the subjects in the training and
testing set are overlapped partially or completely is
application-dependent. For instance, in face recogni-
tion technology (FERET) evaluation [4] , part of the
face images (and subject) in the gallery and probe sets
are also in the training set for algorithm development.
However, in FRVT [1], all the images (and subjects) in
the testing set are confidential to all the participants,
which means the developers have to consider carefully
how their algorithms can generalize to unseen subjects .
In contrast, the Lausanne Protocol based on XM2VTS
database [5] does not distinguish the training set from
the gallery, i.e., the gallery is the same as the training
set. Evidently, different protocol will result in evalua-
tion of different difficulty.
Difficulty Control
The goals of performance evaluation are multifold,
such as to compare several algorithms and choose
the best one , or determine whether one technology
can meet the requirements of specific applications.
So, it is very import ant to control the difficulty of the
evaluation. The evaluation itself should not be too
hard or too easy. If the evaluation is too easy, all the
technologies might have similarly perfect perfor-
mances and thus no statistically salient difference
can be observed among the results. Simil arly, if the
evaluation is too challenging, all the systems may not
work and have bad performance. Therefore, it is
indeed very important to control the difficulty of the
evaluation in order to make the participants perform
discrepantly.
The difficulty of an evaluation protocol is mainly
determined by the variations of the samples in the
probe set from the registered ones. The more the vari-
ation, the more difficult the evaluation is. The sources
of the variations are multifold. Coarsely, they can be
categorized in to two classes: int rinsic variations and
extrinsic variations. The former means the changes of
the biometric feature itself, while the latter comes from
the external factors especially during the sensing pro-
cedure. For instance, in face recognition, variations in
the facial appearance due to the expression and aging
are intrinsic, while those due to lighting, viewpoint,
camera difference, and partial occlusion are extrinsic.
For instance, more recently, multiple biometric grand
challenge (MBGC) [6] is being organized to investi-
gate, test, and improve performance of face and iris
recognition technolog y on both still and video imag-
ery through a series of challenge problems, such as
low resolution, off-angle images, unconstrained f ace
imaging conditions etc. Especially, fo r all biometrics,
the time inter val between the acquisition of the
registered sample and unseen sample s presented to
a system is an important factor, because different
acquisition time implies both intri nsic and extrin-
sic variations. For an evaluation of academic algo-
rithms, a reasonable distribution of all the possible
variations in the testing set is desirable, while for
application-specific system evaluation it is better to
include variations most po ssibly appeari ng in the
practical applications.
The abovementioned datab ase structure also affects
the difficulty of the evaluation. If the samples or the
subjects in the testing set have been included in the
training set, the evaluation becomes relatively easy. If
all the testing samples and subjects are novel to the
learned model or system, the overfitting problem
might make the task more challenging. In extreme
case, if the training set and the testing set are heteroge-
neous, the task will be much more difficult. For in-
stance, if the training set contains only biometric
samples of Mongolian, while the testing samples are
from the western. Therefore, the structure of the data-
base for evaluation should be carefully designed to
tune the difficulty of the evaluation.
Another factor influencing the evaluation diffi-
culty is the database size, i.e., the number of registered
subjects in the database. This is especially impor-
tant for identification and watch list applications,
since evidently the more subjects to recognize,
the more challenging the problem becomes. Some
observations and conclusions have been drawn in
FRVT2002 [1].
1060
P
Performance Evaluation, Overview

Finally, the number of registered biometric samples
for each subject should also be considered to control
the difficulty of the evaluation. Generally speaking,
the task will become easier with the increase of the
sample num ber per person. Note that, an algorithm
that works very well with many samples per person
does not necessarily work similarly well when the
number of samples for each subject is very few. For
instance, in many face recognition applications, there
might be only one registered face image per person in
the database.
Evaluation Protocols
An evaluation protocol determines how to test a sys-
tem, design the datasets, and measure the perfor-
mance. Successful evaluations should be administered
by third parties. The details of the evaluation proce-
dure must be published along with the evaluation
protocol, testing procedures, performance results, and
the dataset (at least some representative examples).
Also, the information on the evaluation and data
should be sufficiently detailed so that users, developers,
and vendors can repeat the evaluation [7]. Generally,
there are three types of evaluation as described in the
following.
Algorithm Evaluation
This kind of evaluation assesses biometric techno-
logy itself. Laboratory or prototype algorithms are
evaluated to measure the state of the art, to define
the technological progress, and to identify the most
promising approaches. Typical technology evaluation
protocols incl ude the FERET series of face recognition
evaluations [4], the National Institute of Standards
and Technology (NIST) speaker recognition evalua-
tions [8], the Lausan ne Protocol based on XM2VTS
database [5], FRGC [3], and the evaluation protocol
based on CAS-PEAL-R1 face database [9 ]. In this kind
of evaluation, all the systems are generally tested with
completely the same dataset for the purpose of fair-
ness. As mentioned above, some of the protocols pro-
vide training set for algorithm development, and in
terms of intrinsic and extrinsic variations the training
samples are homogeneous with those in the testing set.
For this kind of evaluation, accuracy measures are the
main performance criteria.
Scenario Evaluation
This ty pe of evaluation type aims at checking whether
a biometric technology is sufficiently mature to meet
the requirements for a class of applications. In this
case, because the system s might have their own data
acquisition sensors, the systems are tested with slightly
different data [7 ]. To compensate for this difference,
the evaluation must be designed carefully to evaluate
systems under as close condition as possible. In addi-
tion, since the evaluations are conducted under
real-world field conditions, they cannot be repeated
exactly. As a kind of system evaluation, performance
criteria measuring both accuracy and usability of the
system are required to consider, such as failure to
acquire rate, enrollment time, response time, through-
put, and scalability.
Operational Evaluation
Instead of evaluating for a class of applications, an
application-specific evaluation measures the perfor-
mance of a specific system for a specific application.
For example, an application-specific evaluation might
need to measure the performance of system X on
verifying the identity of people as they enter secure
building Y. The primary goal of this kind of evaluation
is to determi ne if a biometric system meets the require-
ments of a specific application [6]. The performance
measures are generally the same as those of scenario
evaluation.
Summary
Performance evaluation should tell unbiased facts.
To this goal, the independent evaluators must deeply
investigate the requirements of the applications
concerned, determine the planned difficulty of the
evaluation and collect appropriate datasets, then assess
the systems w ith suitable performance measures, and
finally report the results along with the evaluation
procedure in detail.
Performance Evaluation, Overview
P
1061
P

Related Entries
▶ Evaluation of Gait Recognition
▶ Face Databases and Evaluation
▶ False Match Rate
▶ False Non-Match Rate
▶ Fingerprint Databases and Evaluation
▶ Hand Databases and Evaluation; Iris Databases
▶ Identification
▶ Influential Factors to Performance
▶ Iris Challenge Evaluation
▶ Iris Recognition Performance under Extreme Image
Compression
▶ Large Scale Evaluation
▶ Performance
▶ Performance Measures
▶ Performance Testing Methodology Standardization
▶ Reference Set
▶ Speaker Databases and Evaluation
▶ Verification
References
1. NIST: Face recognition vendor test (FRVT). http://www.frvt.org ,
2000, 2002, 2004
2. The fourth international fingerprint verification competition.
http://bias.csr.unibo.it/fvc2006/
3. Phillips, P.J., Flynn, P.J., Scruggs, T., Bowyer, K.W., et al.: Over-
view of the face recognition grand challenge. In: Proceedings of
the IEEE International Conference on Computer Vision and
Pattern Recognition (CVPR’05), pp. 947–954. IEEE Computer
Society, Washington, DC (2005)
4. Phillips, P.J., Moon, H., Rauss, P., Rizvi, S.A.: The FERET
evaluation methodology for face-recognition algorithms. In:
Proceedings of the IEEE International conference on Computer
Vision and Pattern Recognition (CVPR’97), pp.137–143. IEEE
Computer Society, Washington, DC (1997)
5. Messer, K., Matas, J., Kittler, J., et al.: XM2VTSDB: the exten-
dedM2VTS database. In: Second International Conference
on Audio and Video based Biometric Person Authentication,
March 1999, Washington, DC (1999)
6. NIST: Multiple biometrics grand challenge. http://face.nist.gov/
mbgc/. Accessed Aug 2008
7. Phillips, P.J., Martin, A., Wilson, C.L., et al.: An introduction to
evaluating biometric systems. IEEE magazine on computer,
pp. 56–63 (2000)
8. NIST: Spoken language technology evaluations. http://www.nist.
gov/speech/tests/sre/index.html. Accessed Aug 2008
9. Gao, W., Cao, B., Shan, S., Chen, X., et al.: The CAS-PEAL large-
scale chinese face database and baseline evaluations. IEEE Trans.
Syst. Man Cybern. (Part A) 38(1), 149–161 (2008)
Performance Measures
JIHYEON JANG,HALE KIM
Inha University, Incheon, Korea
Synonyms
Performance evaluation measures; Perform ance metrics
Definition
Performance measures in biometrics define quantifiable
assessments of the processing speed, recognition accu-
racy, and other functional characteristics of a biometric
algorithm or system. The processing speed is evaluated
by Throughput rate which represents the number of
users that can be processed per unit time, and the
typical metrics for recognition accuracy are the rates
of Failure-to-enroll, Failure-to-acquire, False non-
match, False match, False reject, and False accept.In
addition to these fundamental performance measures,
there are other measures which are specifically depen-
dent on applications (verification, open-set identifica-
tion, or closed-set identification), such as False-negative
and False-positive identification error rates. Also,
graphic measures such as DET cur ve, ROC curve, and
CMC curve are very efficient tools to present overall
matching performance of biometric algorithms or sys-
tems. Biometric performance testing focuses on the
evaluation of technical performance and various error
rates of biometric algorithms or systems.
Introduction
The purpose of biometric performance evaluation
is to determine the range of errors and throughput
rates, with the goal of understanding and predicting
real-world recognition and throughput performance of
biometric systems. The error rates include both false-
positive- and false-negative decisions as well as failure-
to-enroll and failure-to-acquire rates across the test
population. Throughput rates refer to the number of
users processed per unit time, based on both compu -
tational speed and human–machine interaction. These
measures are defined to be applicable to all biometric
systems and devices.
1062
P
Performance Measures
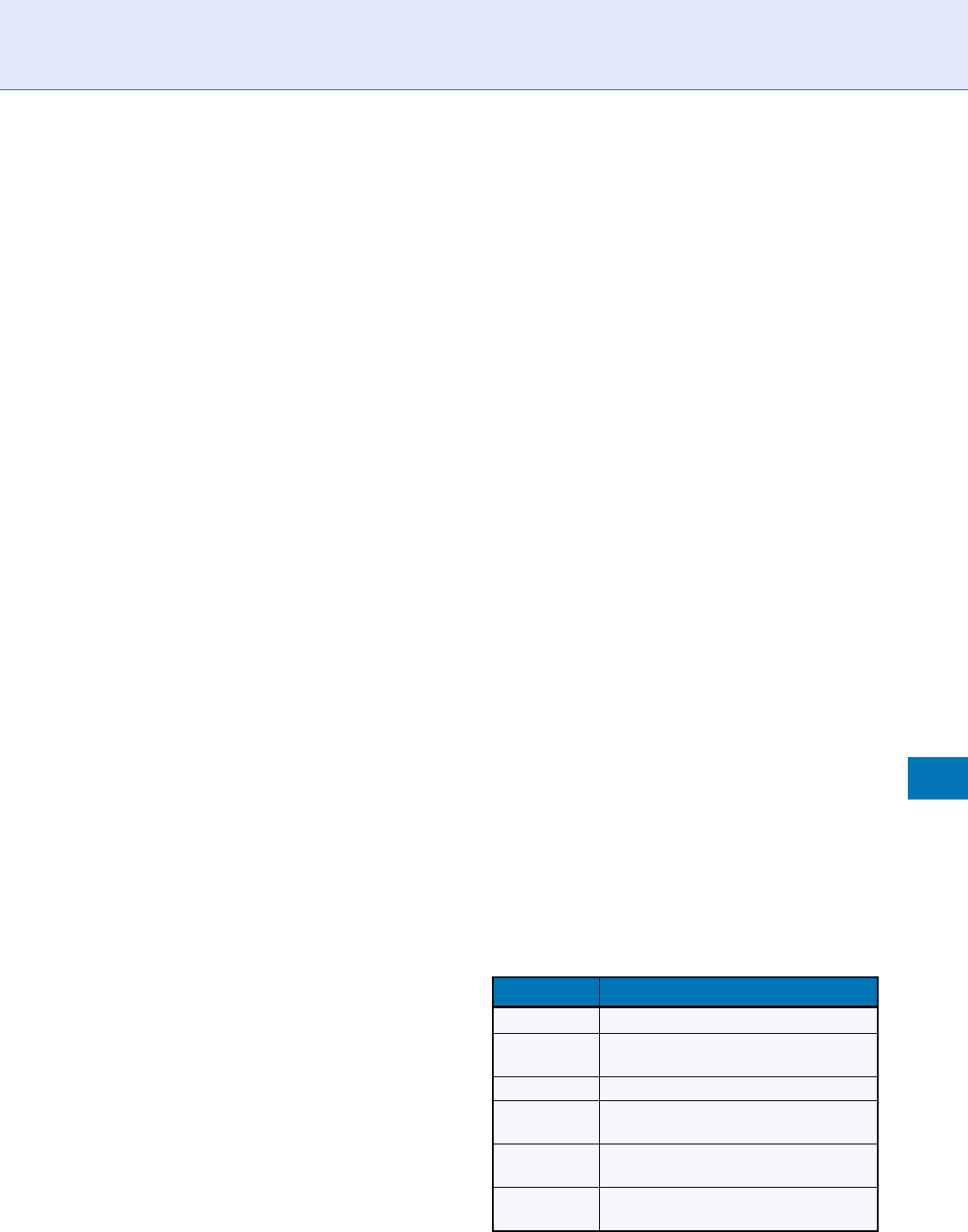
In general, biometric performance testing is divi-
ded into three categories: technology, scenario, and
operational [1–3]. The following summarizes the char-
acteristics and differences of evaluation types, espe-
cially focusing on the resulted metrics.
Technology Evaluation
Technology evaluation is an offline process for testing
biometric components using a precollected corpus of
samples. Its goal is to compare the performance of bio-
metric algorithms for the same biometric modality. Only
algorithms compliant with a given input/output proto-
col are tested. Although sample data may be distributed
for developmental or tuning purposes prior to the test,
the actual testing must be done on data that have not
been previously seen by algorithm developers. The test
results are repeatable because the test corpus is fixed, and
provide most of the performance metrics.
Scenario Evaluation
Scenario evaluation is an online proc ess for determining
the overall system performance in a prototype or
simulated application. Testing is performed on a com-
pletesysteminanenvironmentthatmodelsareal-world
target application. Each tested system has its own acqui-
sition devices, while data collection has to be carried out
across all tested systems with the same population in the
same environment. Test results are repeatable only to
the extent to which the test scenario and population
can be carefully controlled, and pr ovide only predicted
end-to-end throughput rates and error rates.
Operational Evaluation
Operational evaluation is also an online process whose
goal is to determine the performance of a complete
biometric system in a specific application environment
with a specific tar get population. In general, its test
results are not repeatable because of uncontrolled op-
erational environments and population. This evalua-
tion provides only end-to-end throughput rates, false
accept, and false reject rates.
This article restricts discussion to the performance
measures of technology evaluation because they are
mathematically well defined and used more often in
real-world biometric performance evaluation.
In a technology evaluation, biometric systems or
algorithm components are evaluated with afixed corpus
of samples collected under controlled conditions. This
allows direct comparison among evaluated systems,
assessments of individual systems’ strengths and weak-
nesses, or insight into the overall performance of the
evaluated systems. Examples of benchmark test evalua-
tions are Facial Recognition Technology (FERET) [4, 5],
Face Recognition Vendor Test (FRVT) 2000, 2002 [6, 7],
2006, Fingerprint Verification Competition (FVC)
2000, 2002, 2004 [8–10], 2006, and National Institute
of standards Technolgy (NIST) Speaker Recognition
Competitions [11, 12]. Not only the performance
metrics but also the test protocols introduced by
these technology evaluations have become the basis of
the ISO/IEC standards on biometric performance test-
ing and reporting.
The internation al standards f or testing a nd
reporting the performance of bio metri c sy stems
have been studied and developed by the Working
Group 5 of ISO/IEC JTC 1’s Subcommittee 37 on
Biometrics, one of which is I SO/IEC IS 19795 consist-
ing of the following multiparts described in Table 1,
under the general title Information technology –
Biometric per formance testing and reporting. ISO/IEC
19795 is concerned solely with the scientific ‘‘technical
performance testing’’ of biometric systems and devices.
Especially, ISO/IEC 19795-1 presents the requirements
and best scientific practices for conducting technical
performance testing. Furthermore, it specifies per-
formance metrics for biometric systems. Most of the
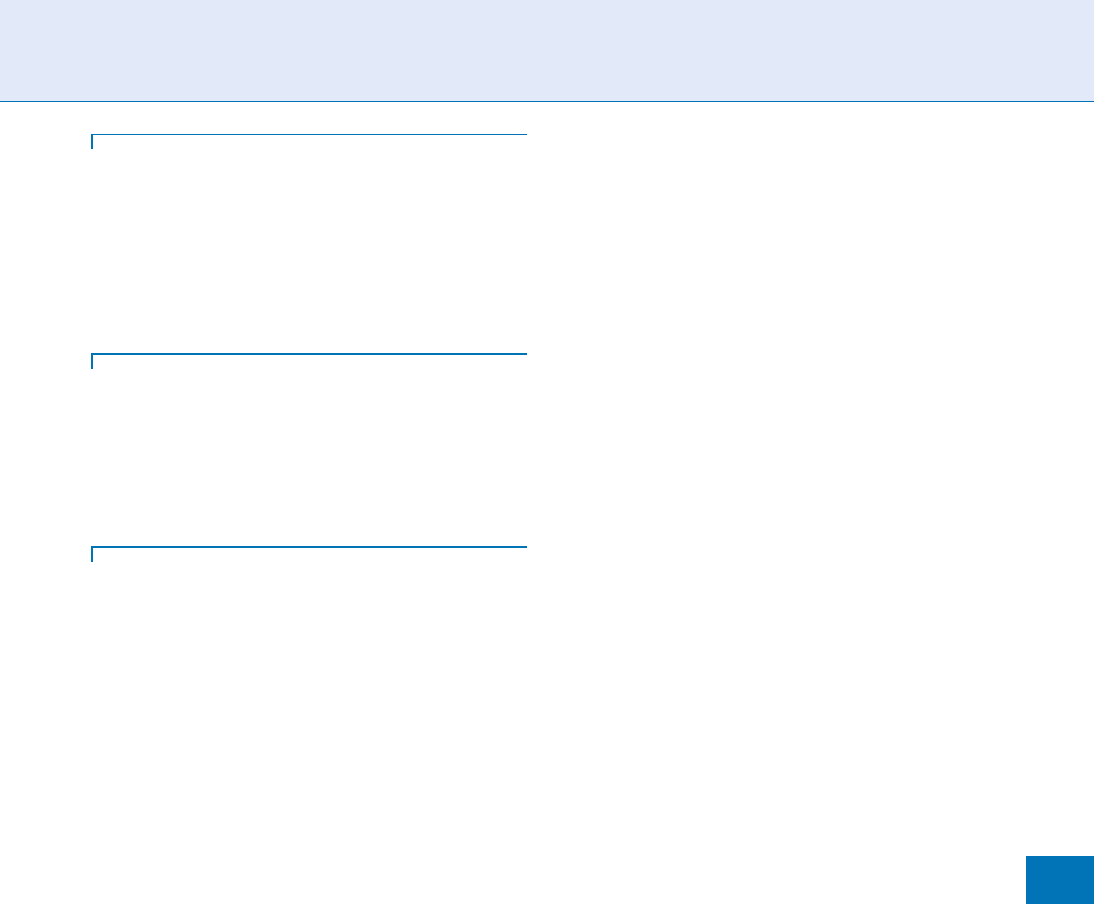
Performance Measures. Table 1 Biometric performance
testing and reporting standards by ISO/IEC JTC 1/SC 37
Standard No. Subtitle
19795-1 Principles and framework
19795-2 Testing methodologies for technology
and scenario evaluation
19795-3 Modality-specific testing
19795-4 Performance and interoperability
testing of data interchange formats
19795-5 Performance of biometric access control
systems
19795-6 Testing methodologies for operational
evaluation
Performance Measures
P
1063
P

performance metrics introduced in this ar ticle are
quoted from those defined in ISO/IEC 19795-1.
This ar ticle describes not only fundamental but
also auxiliary performance measures of biometric
systems in terms of error rates and throughput
rates. These measures a re mainly defined for tech-
nology evaluation, and can be easily employed for
other evaluation t ypes. Most of the measures intro-
duced in this article are cited from ISO/IEC IS
19795-1 [1] and 19795-2 [2]. For more detailed infor-
mation, readers are recommended to refer to these
standards. Meanwhile, the performance measures for
interoperability testing of data interchange formats
and for sensor characteristics are not considered in
this article.
Performance Measures
Decision errors in biometric verification or identifica-
tion are due to various types of errors occurred in
each process of a biometric system, sample acquisi-
tion, feature extraction, and comparison. How these
fundamental errors combine to form decision errors
depends upon various factors such as the number
of comparisons required, either positive or negative
claim of identity, and the decision policy, for example,
whether the system allows multiple attempts.
Fundamental Performance Measures
The following measures are considered to be funda-
mental because they can be employed regardless of the
types of applications of biometric systems. The failure-
to-enroll and failure-to-acquire rates measure the per-
formance of the feature extracting component, while
the false match and false nonmatch rates measure that
of the matching component.
FTE (failure-to-enroll rate) is the proportion of the
population for whom the system fails to complete
the enrolment process. The failure-to-enroll occurs
when the user cannot present the required biomet-
ric characteristic, or when the submitted biometric
sample is of unacceptably bad quality. In the latter
case, stricter requirements on sample quality at
enrollment will increase the failure-to-enroll rate,
but improve matching performance because the
failure-to-enroll cases do not contribute to the
failure-to-acquire rate, or matching error rates.
FTA (failure-to-acquire rate) is the proportion of
verification or identification attempts for which
the system fails to capture or locate biometric sam-
ples of sufficient quality. The failure-to-acquire
case occurs when the required biometric character-
istic cannot be presented due to temporary illness
or injury, or when either the acquired sample or
the extracted features do not satisfy the quality
requirements. In the latter case, stricter require-
ments on sample quality at acquisition will increase
the failure-to-acquire rate but improve matching
performance, because the failure-to-acquire cases
are not included in calculating the false match and
nonmatch rates.
FNMR (false nonmatch rate) is the proportion of
genuine attempt samples falsely declared not to
match the template of the same characteristic
from the same user subm itting the sample.
FMR (false match rate) is the proportion of zero-
effort impostor attempt samples falsely declared to
match the compared nonself template.
The false match and false nonmatch rates are deter-
mined by the same decision threshold value on simi-
larity scores. By adjusting the decision threshold, there
will be a trade-off between false match and false non-
match errors. They are calculated with the number of
comparisons (or attempts) and useful for evaluating
the performance of a component algorithm.
Performance Measures for Verification
System
Verification is one of the two major applications of
biometrics, where the user makes a positive claim to
an identity, features extracted from the submitted bio-
metric sample are compared with the enrolled templates
for the claimed identity, and an accept- or reject deci-
sion regarding the identity claim is returned. In evaluat-
ing the performance of biometric systems, the unit
operation is a transaction, which can be a single attempt
but mostly consists of multiple attempts. In this aspect,
the fundamental measures, FMR and FNMR, cannot
be directly applied to the overall performance evalua-
tion of a biometric system, and the following metrics
are designed for more general measures.
1064
P
Performance Measures

FRR ( false reject rate) is the proportion of verifica-
tion transactions with truthful claims of identity
that are incorrectly denied. When a transaction
consists of a sing le attempt, a false rejection includes
a failure-to-acquire or a false nonmatch, and the
false reject rate is given by:
FRR ¼ FTA þ FN MR ð1 FTAÞ
FAR (false accept rate) is the propor tion of veri-
fication transactions with zero-effort wrongful
claims of identity that are incorrectly confirmed.
When a transaction consists of a single attempt,
a false acceptance requires a false match with
no failure-to-acquire, and the false accept rate is
given by:
FAR ¼ FMR ð1 FTAÞ
A first order estimation of FRR and FAR for transac-
tions of multiple attempts can be derived from the
detection error trade-off curve. However, such esti-
mates cannot take into account correlations in sequen-
tial attempts and in the comparisons involving the
same user, and consequently can be quite inaccurate.
Therefore, ISO/IEC 19795 recommends that these per-
formance metrics shall be derived directly, using test
transactions with multiple attempts as specified by
the decision policy.
FRR and FAR do not include the failures occurred
in enrollment. As mentioned earlier, increasing the
FTE rate generally improves matching performance.
For comparing the performance of biometric systems
having different failure-to-enroll rates, both FRR and
FAR need to be generalized so that they can take
enrollment errors into account. In the following
generalized FRR and FAR, a failure-to-enroll is treated
as if the enrollment is completed, but all subsequent
transactions by or against that enrollee fail. For a
technolog y evaluation, the generalized FRR and FAR
are defined as follows [1]:
GFRR (generalized false reject rate) is the propor-
tion of genuine users who cannot be enrolled,
whose sample is submitted but cannot be acquired,
or who are enrolled, samples acquired, but are
falsely rejected.
GFRR ¼ FTE þð1 FTEÞFRR
¼ FTE þð1 FTEÞFTA þð1 FTEÞ
ð1 FTAÞFMR
GFAR (generalized false accept rate) is the propor-
tion of impostors who are enrolled, samples ac-
quired, and falsely matched.
GFAR ¼ð1 FTEÞFAR
¼ð1 FTEÞð1 FTAÞFMR
Performance Measures for Identification
System
In identification, compared with verification, the
user presents a biometric sample without any claim of
identity, and a candidate list of identifiers are returned as
a result of matching the user’s biometric features with all
the enrolled templates in a database. Identification has
two cases: while the closed-set identification always
returns a nonempty candidate list, assuming that all
the users are enrolled in the database, the open-set iden-
tification may return an empty candidate list because
some potential users are not enrolled.
CIR (correct identification rate) is the proportion
of identification transactions by users enrolled
in the system in which the user ’s correct identifier
is among those returned. The identification rate
at rank r is the probability that a transaction by
a user enrolled in the system includes that user’s
true identifier within the top r matches returned.
When a single point identification rank is reported,
it should be referenced directly to the database size.
FNIR (false-negative identification-error rate) is the
proportion of identification transactions by users
enrolled in the system in which the user’s correct
identifier is not among those returned.
FNIR ¼ FTA þð1 FTAÞFNMR
FPIR (false-positive identification-error rate) is the
proportion of identification transactions by users
not enrolled in the system, where a nonempty list
of identifiers is returned. For a template database of
the size N, FPIR is given as:
FPIR ¼ð1 FTAÞf1 ð1 FMRÞ
N
g
Other Performance Measures
Besides the above performance measures from ISO/IEC
19795-1, the followin g measures have been defined
Performance Measures
P
1065
P
for more accurate evaluation of performance of bio-
metric systems and employed in many biometric algo-
rithm contests such as FVC’s [8–10].
Genuine score distribution and Impostor score dis-
tribution are computed and graphica lly repor ted
to show how the algorithm ‘‘separates’’ the two
classes.
EER (equal error rate) is computed as the point
where FNMR=FMR. In practice, the matching
score distributions are not continuous and a cross-
over point might not exist.
EER* is the value that EER would take if the match-
ing failures were excluded from the computation of
FMR and FNMR.
FMR100 is the lowest FNMR for FMR 1%.
FMR1,000 is the lowest FNMR for FMR 0.1%.
ZeroFMR is the lowest FNMR at which no False
Matches occur.
ZeroFNMR is the lowest FMR at which no False
NonMatches occur.
Average enroll time is the average CPU time for a
single enrollment operation.
Average match time is the average CPU time for a
single match operation between a templa te and
a test sample.
Graphic Performance Measures
When presenting test results, the matching or
decision-making performance of biometric systems
are graphically represented using Detection Error
Trade-off (DET), Receiver Operating Characteristics
(ROC), or Cumulative Match Characteristic (CMC)
curves.
DET Curve
DET curves are used to plot matching error rates
(FNMR against FMR), decision error rates (FRR
against FAR), and open-set identification error rates
(FNIR against FPIR). The DET curve is a modified
ROC curve which plots error rates on both axes (false
positives on the x-axis and false negatives on the
y-axis). For example, in Fig. 1, each DET curve is
generated by varying the value of the decision thresh-
old. If the threshold is set to a higher value in order to
decrease the false acceptances, the false rejections will
increase. On the contrary, if the threshold is set to a
lower value, the false rejections will decrease with the
increase in false acceptance.
Performance Measures. Figure 1 Example set of DET curves [1].
1066
P
Performance Measures
ROC Curve
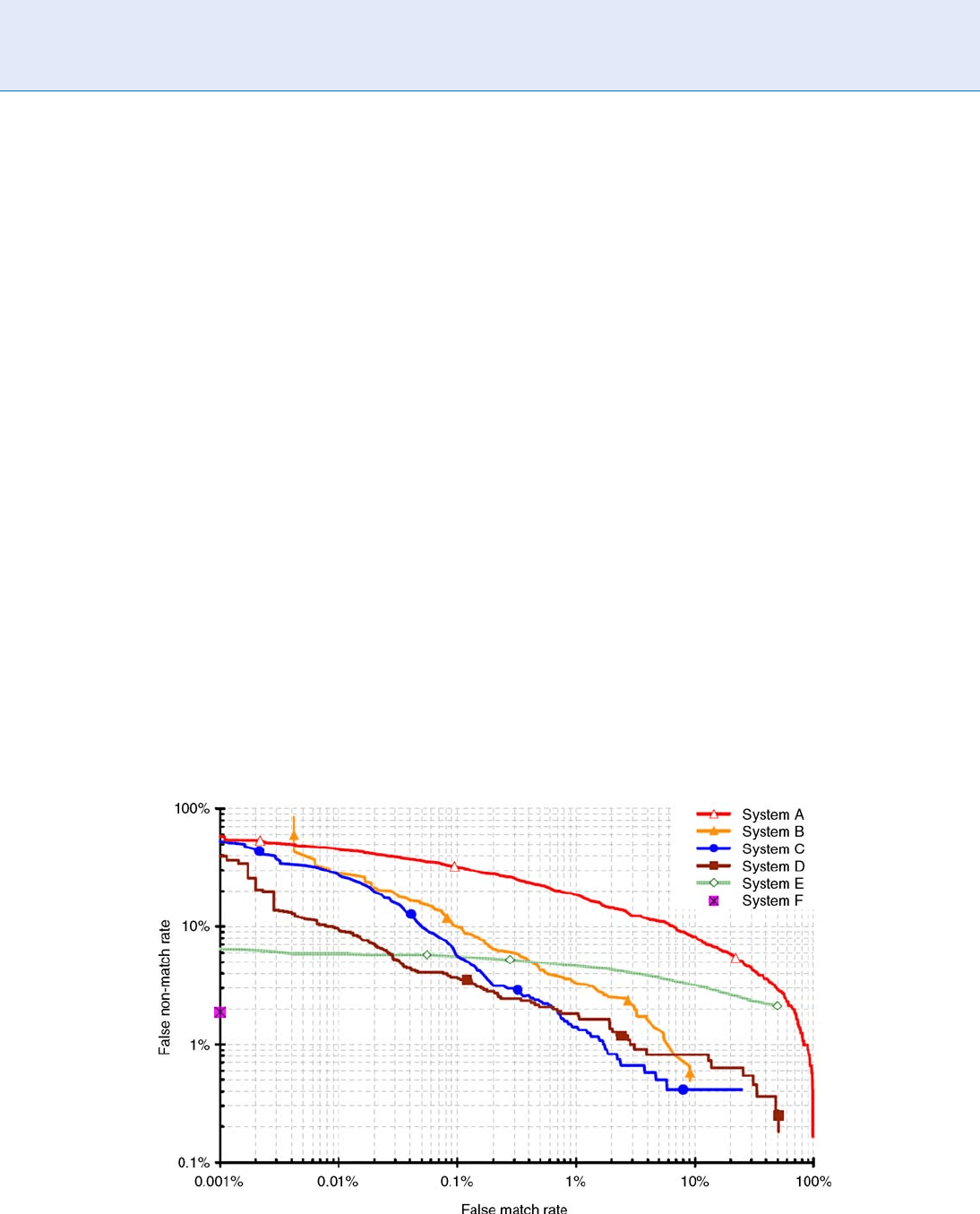
ROC curves are a traditional method for summarizing
the performance of imperfect diagnostic, detection, and
pattern-matching systems. ROC curves are threshold-
independent, allowing performance comparison of dif-
ferent systems under similar conditions, or of a single
system under differing conditions. ROC curves may
be used to plot matching algorithm performance
(1FNMR against FMR), end-to-end verification system
performance (1FRRagainstFAR),aswellasopen-set
identification system performance (CIR against FPIR).
Figure 2 shows an example of ROC curves for compar-
ing the performance of a set of fingerprint matching
Performance Measures. Figure 2 Example set of ROC curves [1].
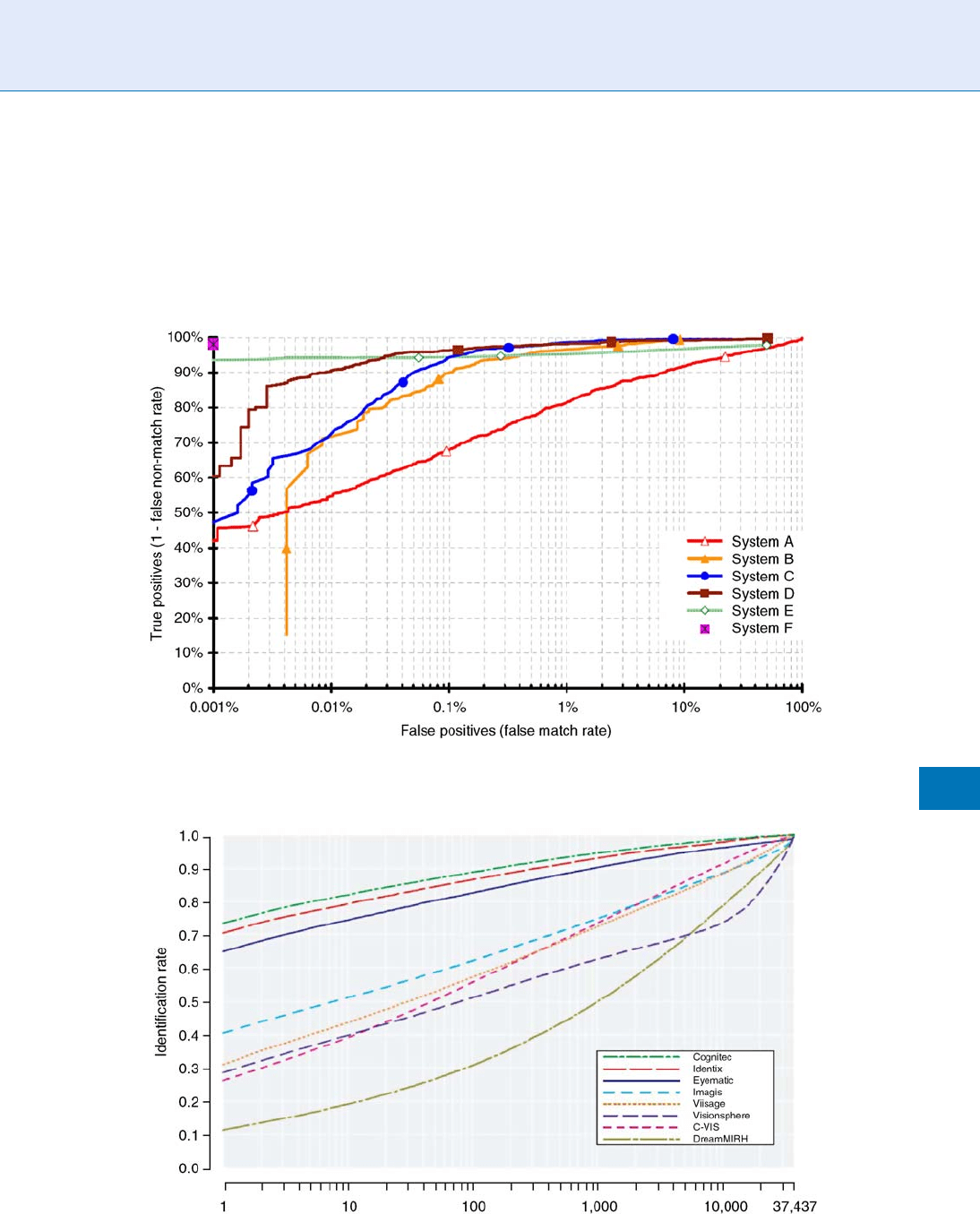
Performance Measures. Figure 3 Example set of CMC curves [7].
Performance Measures
P
1067
P

algorithms. An ROC curve is a plotting of the rate
of false positives (i.e., impostor attempts accepted) on
the x-axis against the corresponding rate of true posi-
tives (i.e., genuine attempts accepted) on the y-axi s
plotted parametrically as a function of the decision
threshold.
CMC Curve
For closed-set identification applications, performance
results are often illustrated using a cumulative match
characteristic curve. Figure 3 shows an example of CMC
curves for comparing the performance of a set of face
identification systems. These curves pro vide a graphical
presentation of identification test results and plots rank
values on the x-axis with the corresponding probability of
correc t identification at or below that rank on the y-axis.
Throughput Rates
Throughput rates represent the number of users that can
be processed per unit time, based on both computational
speed and human–machine interaction. These measur es
are generally applicable to all biometric systems and
devices. Attaining adequate throughput rates is critical
to the success of an y biometric system. For verification
systems, throughput rates ar e usually controlled by the
speed of user interaction with the system in the process
of submitting a biometric sample of good quality.
For identification systems, they can be heavily impacted
by the computer processing time required to compare
the acquired sample with the database of enrolled
templates. Hence, depending upon the type of a system,
it may be appropriate to measure the interaction times
of users with the system and also the processing rate of
the computational hardware. Actual benchmark mea-
surement of computer processing speed is cover ed
elsewhere and is considered outside the scope of this
article [13].
Related Entries
▶ CMC Curve
▶ DET Curve
▶ Biometric Sample Quality
▶ Influential Factors to Performance
▶ Interoperable Performance
▶ ROC Curve
References
1. ISO/IEC JTC1/SC37 IS19795-1: Biometric Performance Tasting
and Reporting- Part 1: Principles and Framework (2006)
2. ISO/IEC JTC1/SC37 FDIS 19795-2: Biometric Performance
Tasting and Reporting- Part 2: Testing methodologies for tech-
nology and scenario evaluation (2006)
3. Phillips, P.J., Martin, A., Wilson, C.L., Przybocki, M.: An Intro-
duction to Evaluating Biometric Systems. IEEE Computer
Magazine (2000)
4. Phillips, P.J., Wechsler, H., Huang, J., Rauss, P.: The FERET
database and evaluation procedure for face-recognition algo-
rithms. Image Vis Comput, 16(5), 295–306 (1998)
5. Phillips, P.J., Moon, H., Rizvi, S., Rauss, P.: The FERET evalua-
tion methodology for face recognition algorithms. IEEE Trans.
PAMI, 22, 1090–1104 (2000)
6. Blackburn, D., Bone, M., Phillips, P.J.: Face recognition vendor
test 2000. Technical report. http://www.frvt.org (2001).
Accessed 19 Aug, 2008
7. Phillips, P.J., Grother, P., Micheals, R., Blackburn, D., Tabassi, E.,
Bone, J.: Face Recognition Vendor Test 2002: Evaluation Report.
Technical Report NISTIR 6965, National Institute of Standards
and Technology (2003)
8. Maio, D., Maltoni, D., Cappelli, R., Wayman, J.L., Jain, A.K.:
FVC2000: fingerprint verification competition. IEEE Trans.
PAMI, 24(3), 402–412 (2000)
9. Maio, D., Maltoni, D., Cappelli, R., Wayman, J.L., Jain, A.K.:
FVC2002: In: Second Fingerprint Verification Competition. Pro-
ceedings of the 16th ICPR, vol. 3, pp. 811–814 (2002)
10. Maio, D., Maltoni, D., Cappelli, R., Wayman, J.L., Jain, A.K.:
FVC2004: Third Fingerprint Verification Competition. Proceed-
ings of the ICBA Springer LNCS, 3072, pp. 1–7 (2004)
11. NIST Speaker Recognition Evaluations. Available online at
http://www.nist.gov/speech/tests/spk/
12. Martin, A., Przybocki, M.: The NIST 1999 speaker recognition
evaluation an overview. Digit. Signal Process. 10, 1–18 (2000)
13. Mansfield, A.J., Wayman, J.L.: Best Practices in Testing and
Reporting Performance of Biometric Devices, Version 2.01,
NPL Report CMSC 14/02 (2002)
Performance Metrics
▶ Performance Measures
1068
P
Performance Metrics
Performance of Biometric Quality
Measures
▶ Biometric Sample Quality
Performance Testing
▶ Performance Evaluation, Overview
Performance Testing Methodology
Standardization
MIC HAEL THIEME
International Biometric Group, New York, NY, USA
Synonym
Biometric performance evaluation standardization
Definition
Performance testing methodology standards define pro-
cesses for test planning, hardware and software configu-
ration and calibration, data collection and management,
enrollment and comparison, performance measurement
and reporting, and documenting the statistical signifi-
cance of test results. The application of performance
testing standards enables meaningful measurement,
prediction, and comparison of biometric systems’ en-
rollment rates, accuracy, and throughput. Interoperabil-
ity of biometric data elements acquired or generated
through different components can also be quantified
through standardized performance tests. Standardized
performance testing methodologies have been devel-
oped for technology tests, in which algorithms process
archived biometric data; scenario tests, in which bio-
metric systems collect and process data from test sub-
jects in a specified application; and operational tests, in
which a biometric system collects and processes data
from actual system users in a field application.
Motivation for the Development of
Biometric Performance Evaluation
Standards
The development of biometric performance testing
standards has been driven by the need for precise,
reliable, and repeatable measurement of biometric sys-
tem accuracy, capture rates, and throughput. Match
rates, enrollment and acquisition rates, and through-
put are central considerations for any organization
deciding whether to deploy biometrics or determining
which modalities and components to implement.
Organizations need to know whether a claimed perfor-
mance level for System A can be compared to a claimed
performance level for System B; if test conditions
varied between two evaluations, comparison of the
same performance metrics may be useless. For exam-
ple, if a vendor claims that its system delivers a false
match rate (FMR) of 0.01%, for example, a potential
deployer might ask:
1. How many test subjects and samples were used to
generate this figure?
2. What was the composition of the test population
whose data was used?
3. How much time elapsed between enrollment and
verification?
4. Were all comparisons accounted for, or were some
samples discarded at some point in the test?
5. What is the statistical significance of the claimed
error rate?
6. What were the corresponding false non-match rate
(FNMR) and failure to enroll rate (FTE) at this
operating point?
7. Was the algorithm tuned to perform for a specific
application or test population?
8. How were test subjects trained and guided?
9. How were errors discovered?
Organizations also need to understand biometric per-
formance evaluation standards in order to properly
specify performance requirements. A lack of under-
standing of biometric performance testing often leads
organizations to specify requirements that cannot be
validated through testing.
Once an organization has decided to deploy a bio-
metric system, standardized performance testing
methods are no less important. Organizations must
properly calibrate systems prior to deployment and
monitor system performance once operational. This
Performance Testing Methodology Standardization
P
1069
P