Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


The partitioning of pixels in an image into sets
based on a common characteristics.
▶ Deformable Models
▶ Gait Recognition, Silhouette-Based
▶ Hand shape
▶ Iris Super-Resolution
Image Warping
The process of manipulating an image is such
that the pixels of the original image are moved
to new locations, without changing their color and
intensity. In face processing, images are sometimes
warped such that their shape is normalized, i.e., all
warped images have the same width, height, eye loca-
tion, etc.
▶ Face Alignment
▶ Face Device
▶ Face Tracking
▶ Face Recognition, Component-Based
Imaging Spectroscopy
▶ Multispectral and Hyperspectral Biometrics
Imaging Volume
The width of the imaging volume is defined by the field
of view of the imaging system, and the depth of the
imaging volume is defined by the depth of field of the
imaging system.
▶ WavefrontCodingforEnhancingtheImaging
Volume in Iris Recognition
Implementation Under Test (IUT)
The implementation under test is that which imple-
ments the base standard(s) being tested. Depending on
the conformance requirements of the base standard,
this may simply be a set of biometric data interchange
records (BDIRs) or it may be a computer algorithm or
other product that creates the BDIRs and/or uses the
data contained in the BDIRs.
▶ Conformance Testing for Biometric Data Inter-
change Formats, Standardization of
Impostor
A generic term for a person unknown by a biometric
system who wishes to obtain the privileges of a client
by claiming her/his identity.
▶ Liveness Detection: Iris
▶ Multiple Experts
Imposter Distribution
The probability distribution of the match score of a
biometric for cases where two instances of biometric
templates that are derived from different individuals
are compared.
▶ Iris on the Move™
Impostor Match
Imposter match is the match between a pair of
biometrics from two different persons.
▶ Fingerprint Matching, Automatic
▶ Individuality of Fingerprints
730
I
Image Warping

Imprecise Localization
The fiducial points on the face (such as eye corners, eye
centers, eyebrows) cannot always be manually marked
or automatically detected with pixel precision. This is
generally due to the ambiguous nature of the gray or
color patterns at these positions. Also, changes in illu-
mination and pose, effect the perception of image
rendering of such fiducials.
▶ Face Misalignment Problem
▶ Face Recognition, Component-Based
Incremental Learning
XIN GENG,KATE SMITH-MILES
Deakin University, Melbourne, VIC, Australia
Synonyms
Adaptive learning; Online learning; Transfer learning
Definition
Incremental learning is a machine learning paradigm
where the learning process takes place whenever new
example(s) emerge and adjusts what has been learned
according to the new example(s). The most prominent
difference of incremental learning from traditional
machine learning is that it does not assume the avail-
ability of a sufficient training set before the learning
process, but the training examples appear over time.
Introduction
For a long time in the history of machine leaning, there
has been an implicit assumption that a ‘‘good’’ training
set in a domain is available a priori. The training set is
so ‘‘good’’ that it contains all necessary knowledge that
once learned, can be reliably applied to any new exam-
ples in the domai n. Consequently, emphasis is put on
learning as much as possible from a fixed training set.
Unfor tunately, many real-world applications cannot
match this ideal case, such as in dynamic control
systems, web mining, and time series analysis, where
the training examples are often fed to the learning
algorithms over time, i.e., the learning process is incre-
mental. There are several reasons for the need for
incremental learning:
1. It might be infeasible in time, storage, or other costs
to obtain a sufficiently large number of representa-
tive examples before the learning process.
2. Even when
▶ training data, sufficiency can be
obtained before learning, the learning algorithm
might get computationally intractable if directly
applied to all the available training data, or the
whole training set cannot be loaded into the main
memory.
3. When new examples become available, learning
from scratch might waste time and computation
resource. Instead, modifying learned knowledge
according to the new examples might be a better
choice, especially for those applications requiring
real-time response.
4. If the example generation itself is time-dependent,
e.g.,
▶ time series data, then it inherently suits an
incremental style of learning.
5. Nonstationary environments might change the tar-
get concept over time (
▶ concept drift). In such
case, the learner should be able to self-adapt to
the changing environments.
In actual fact, incremental learning is quite com-
mon in reality. Some researchers even claim that incre-
mentality is rather ubiquitous in learning [1], which
can be evidenced by the way humans acquire knowl-
edge over time. Although in some cases, such as
theor y refinement [2], all of the ‘‘teachable’’ knowledge
may be available a priori, most learning tasks are
inherently incremental. Interestingly, sometimes learn-
ing is only possible when data is presented incremen-
tally. For example , Elman [3] ever gave an example of
learning grammar with a recurrent network, where
‘‘the network fails to learn the task when the entire
data set is presented all at once, but succeeds when the
data are presented incrementally.’’
Considering the purpose of dealing with incremen-
tality, several terms other than ‘‘incremental learning’’
has been used for the similar meanings. Some research-
ers [4] named the algorithms which can learn from
increasing training examples as onli ne lear ning
Incremental Learning
I
731
I
algorithms. The algorithms attempting to solve the
concept drift problem are sometimes called adaptive
learning algorithms [5], and some others are called
transfer learning algorithms [6].
The possibly earliest incremental learning algo-
rithm is the nearest neighbor classification method
[7], although the term ‘‘incremental learning’’ was
not explicitly proposed then. Most work on incremental
learning starts from late 1980s. For example, Schlimmer
and Fisher [8] proposed an algorithm named ID4
which incrementally generated a decision tree by
updating the splits that were no longer the best given
new examples. Aha et al. [9] proposed a framework
called instance-based learning to solve incremental
learning tasks using only specific instances. Syed et al.
[10] found that the support vectors in SVM could form
a succinct and sufficient training set for incremen-
tal learning. Ross et al. [11] proposed an incremental
learning algorithm for visual tracking based on a low-
dimensional subspace representation, which can well
handle changes in the appearance of the target.
Evaluation Criteria
Same with traditional machine learning methods,
many incremental learning algorithms were evaluated
by the prediction accuracy on some benchmark data
sets. Additional to this general criterion, researchers
also proposed other more specific criteria according to
the characteristics of incremental learning.
Schlimmer and Granger [12] proposed three cri-
teria to measure the usefulness and effectiveness of an
incremental learning method: (1) the number of obser-
vations (examples) needed to obtain a ‘stable’ concept
description, (2) the cost of updating memory, and
(3) the quality of learned concept descriptions. These
measures are specifically designed for online algo-
rithms trained on time-based examples.
More generally, Syed et al. [10] claimed that in
order to measure an incremental learning algorithm,
two new questions need to be answered: (1) How
much better is a learned model at step n þ i than
another model obtained after step n? (2) Can an incre-
mental algorithm recover in the next incremental
step(s), if it goes drastically off the ‘‘actual’’ concept at
any stage? Consequently, they proposed three criteria
for evaluation of the robustness of incremental learning
algorithms: (1) Stability – the prediction accuracy on
the test set should not vary wildly at every incremental
learning step; (2) Improvement – there should be im-
provement in the prediction accuracy as the training
progresses and the learning algo rithm sees more train-
ing examples; and (3) Recoverability – the learning
method should be able to recover from its errors, i.e.,
even if the performance drops at a certain learning
step, the algorithm should be able to recover to the
previous best performance.
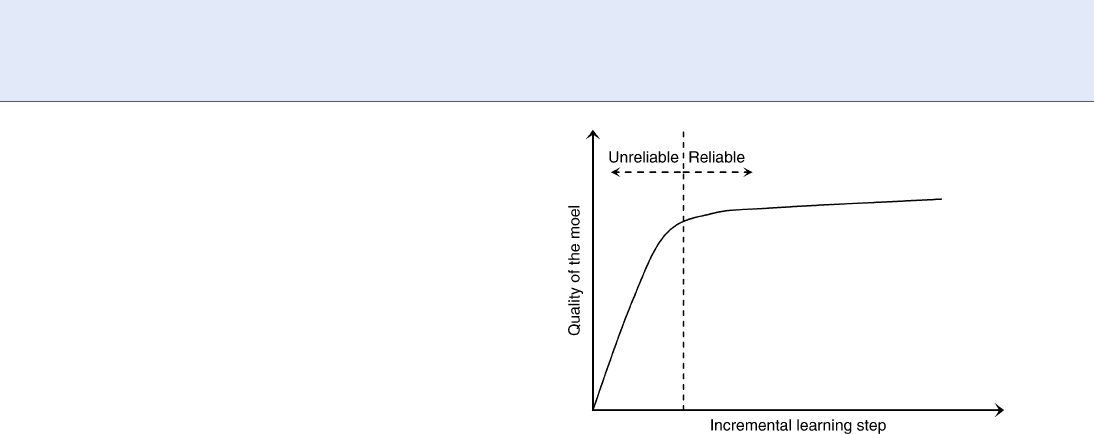
Another often used criterion is the learning curve.
An incremental algorithm may start learning from
scratch and gradually obtain knowledge with an increas-
ing amount of training examples. Consequently, the
quality of the learned model (usually measured by pre-
diction accuracy) displays a gradually improving curve
over time, which is called a learning curve. A typical
example of the learning curve of an incremental learning
algorithm is shown in Fig. 1. Usually the learned model
is not very reliable at the early stage of the curve.
Decisions can be made according to the learning
curve on how valuable the output of the incremental
learner might be at a certain stage. However, in prac-
tice, it is often difficult to determine the point at which
the model has learned ‘‘enough’’ to be reliable. Gener-
ally, a typical ‘‘good’’ learning curve should increase
rapidly to a relatively steady high level.
Incremental Learning Tasks and
Algorithms
The term incremental has been applied to both
learning tasks and learning algorithms. Giraud–Carrier
Incremental Learning. Figure 1 A typical example of
incremental learning curve.
732
I
Incremental Learning

[1] gave definition of incremental learning tasks and
algorithms as follows:
Definition 1: A learning task is incremental if the
training examples used to solve it become available
over time, usually one at a time.
Definition 2: A learning algorithm is incremental if,
for any given training sample e
1
,...,e
n
, it produces a
sequence of hypotheses h
0
,h
1
,...,h
n
, such that h
iþ1
depends only on h
i
and the current example e
i
.
This definition is based on the incrementality of
training examples. Zhou and Chen [13] later extended
this definition by distinguishing three different kinds
of incremental tasks:
1. Example-Incremental Learning Tasks (E-IL Tasks):
New training examples are provided after a learning
system is trained. For example, a face recognition
system can gradually improve its accuracy by incor-
porating new face images of the registered users
when they use it without reconfiguring and/or
retraining the entire system. The descript ion of the
E-IL tasks is similar to Definition 1.
2. Class-Incremental Learning Tasks (C-IL Tasks):New
output classes are provided after a learning system
is trained. For example , if a new user is added into
the registered user group in the aforementioned
face recognition system, the system should be able
to recognize the new user without reconfiguring
and/or retraining the entire system.
3. Attribute-Incremental Learning Tasks (A-IL Tasks):
New input attributes are provided after a learning
system is trained. For example, if the camera used
in the aforementioned face recognition system is
changed from gray-scale camera to color camera,
the system should be able to utilize the additional
color features without reconfiguring and/or retrain-
ing the entire system.
While this taxonomy provides more insights into incre-
mental learning, the definition based on incremental
training examples has been widely accepted. In fact,
new classes and new attributes are regarded as possible
changes of the new examples, then C-IL and A-IL
tasks can also be regarded as E-IL tasks. This is why we
still use the incrementality of training examples to give
definition of incremental learning at the beginning of
this essay.
The relationship between incremental/nonincremen-
tal tasks and learners is described by two matric es in [1]:
the application matrix and the utility matrix, as shown
in Fig. 2. The application matrix indicates whether a
particular learner can be applied to a particular task,
while the utility matrix indicates whether a particular
match of learner and task is of high utility. From the
definitions of incremental learning task and algo-
rithm (learner), it is natural to expect high utility of
applying incremental learners to incremental tasks and
nonincremental learners to nonincremental tasks. The
off-diagonal match in the application matrix (incre-
mental learner to nonincremental task, and nonincre-
mental learner to incremental task) is also possible, but
of low utility.
On the one hand, incremental learners can be
applied to nonincremental tasks if taking the train-
ing examples one by one, although all of the training
examples are available a priori. However, since incre-
mental learners can only make use of current hypo-
thesis and example, its ‘‘vision’’ is inherently local.
In this case, the global information contained in the
entire training set of the nonincremental task might be
ignored by the incremental learner.
On the other hand, nonincremental learners
can be applied to incremental tasks if retraining the
system whenever a new example is available. This
brute-force way is certainly inefficient or sometimes
infeasible in terms of memory requirement (for the
storage of all previous training samples) and computa-
tional resources. Moreover, in cases where concept
drift occurs, the most recent examples provide most
information for the new concept. Thus retraining on
Incremental Learning. Figure 2 Relationship between incremental/nonincremental tasks and learners [1]:
(a) application matrix and (b) utility matrix.
Incremental Learning
I
733
I

the entire training set might not be able to perceive the
changes of the tar get concept.
Even when applied to incremental tasks, the suit-
able incremental learni ng algorithm must be carefully
designed. In cases where the target concept is relatively
stable or gradually changes, the new examples help to
refine the existing learned concept model. In cases
where the concept changes are substantial, the system
might need to discount or even ‘‘ forget’’ the old exam-
ples, and adjust what has been induced from them.
In some applications, the incremental learning algo-
rithms even have to automatically distinguish the above
two cases and tak e actions to either improve the current
concept representation as more supportive examples
become available, or respond to suspected changes in
the definition of the target concept when the incoming
examples become inconsistent with the learned concept.
Applications
With increasing demands from real applications for
machine learning algorithms to be more adaptive,
scalable, robust, and responsive, incremental learning
has been successfully applied to solve a w ide range of
real-world problems. Generally speaking, incremental
learning is most suitable for the following three kinds
of applications:
1. Applications where the target concepts change over
time.
Examples:
(a) Robotics. The environment around a robot is
often changing and unpredictable. In order
to accomplish the assigned missions, a robot
must be able to adapt to the new environment
and react properly, which is naturally an incre-
mental learning process.
(b) Intelligent agent. An intelligent agent is an
entity which can observe and act upon an
environment and direct its activity towards
achieving goals. Incremental learning can help
an intelligent agent to perceive changes of the
environment and accordingly adjust its strategy
to achieve goals.
2. Applications where the ‘‘sufficient training sets’’ are
too big.
Examples:
(a) Content based image retrieval (CBIR) . CBIR is
the problem of searching for digital images in
large databases or from the internet based on
analysis of the actual contents of the images. In
order to learn sufficient concepts for retrieval
purpose, usually a large amount of images
should be included in the training set. The
size of the training set could even be infinite
in the case of online image retrieval. Incremen-
tal learning can be used to solve the problem of
shortage in computation and storage resources.
Also it can help to implement an ‘‘improve
while using’’ system by gradually improving
accuracy whenever new examples emerge dur-
ing the use of the system.
(b) Face recognition. The main challenge of auto-
matic face recognition is that face images could
present changes in various aspects, such as pose,
illumination, expression, and occlusion. Taking
all of these affective factors into consideration
consequently requires a huge training set.
Similarly, incremental learning techniques can
help to realize a face recognition system which
learns while in use, i.e., every time a user uses
the system, a new face image is provided to the
system for incremental learning.
3. Applications where the training examples are
obtained over time (time series data).
Examples:
(a) Visual object tracking. During visual tracking,
the appearance of the target object is usually
highly variable (e.g., pose variation, shape de-
formation, illumination changes, etc.) in dif-
ferent video frames over time. Incremental
learning techniques can be adopted to update
the internal representation of the target object
in realtime for constantly and efficiently track-
ing the object.
(b) Software project estimation. Estimating the cost
and duration of a software project is ver y im-
portant for project management. However,
useful information about a project becomes
available over time while the project progresses.
Thus software project estimation is inherently
an incremental learning task.
Summary
Incrementality is part of the nature of learning. Com-
pared with traditional machine learning which requires
734
I
Incremental Learning

a training set beforehand, incremental learning shows
several advantages: (1) It does not require a sufficient
training set before learning; (2) It can continuously
learn to improve when the system is running; (3) It
can adapt to changes of the target concept; (4) It
requires less computation and storage resources than
learning from scratch; (5) It naturally matches the
applications depending on time series. Nevertheless,
incremental learning is not suitable for many non-
incremental learning tasks due to the fact that it is
inherently ‘‘myopic’’ and tends to ignore the global
information in the entire training set.
Related Entries
▶ Machine-Learning
References
1. Giraud-Carrier, C.G.: A note on the utility of incremental
learning. AI Commun. 13(4), 215–224 (2000)
2. Ourston, D., Mooney, R.J.: Theory refinement combining ana-
lytical and empirical methods. Artif. Intell. 66(2), 273–309
(1994)
3. Elman, J.L.: Learning and development in neural net-
works: The importance of starting small. Cognition 46(1),
71–99 (1993)
4. Cheng, L., Vishwanathan, S.V.N., Schuurmans, D., Wang, S.,
Caelli, T.: Implicit online learning with kernels. In: Advances
in Neural Information Processing Systems 19, pp. 249–256.
Vancouver, Canada (2006)
5. Huo, Q., Lee, C.H.: On-line adaptive learning of the continuous
density hidden markov model based on approximate recursive
bayes estimate. IEEE Trans. Speech Audio Process. 5(2), 161–172
(1997)
6. Pan, S.J., Kwok, J.T., Yang, Q.: Transfer learning via dimension-
ality reduction. In: Proceedings of the AAAI Conference on
Artificial Intelligence, pp. 677–682. Chicago, IL (2008)
7. Cover, T.M., Hart, P.E.: Nearest neighbour pattern classification.
Trans. Inf. Theory 13, 21–27 (1967)
8. Schlimmer, J.C., Fisher, D.H.: A case study of incremental con-
cept induction. In: Proceedings of the National Conference on
Artifical Intelligence, pp. 496–501. San Mateo, CA (1986)
9. Aha, D.W., Kibler, D.F., Albert, M.K.: Instance-based learning
algorithms. Mach. Learn. 6, 37–66 (1991)
10. Syed, N.A., Liu, H., Sung, K.K.: Handling concept drifts in incre-
mental learning with support vector machines. In: Proceedings of
ACM International Conference on Knowledge Discovery and Data
Mining, pp. 317–321. San Diego, CA (1999)
11. Ross, D.A., Lim, J., Lin, R.S., Yang, M.H.: Incremental learning
for robust visual tracking. Int. J. Comput. Vis. 77(1-3), 125–141
(2008)
12. Schlimmer, J.C., Granger, R.H.: Incremental learning from noisy
data. Mach. Learn. 1(3), 317–354 (1986)
13. Zhou, Z.H., Chen, Z.: Hybrid decision tree. Knowl. Based Syst.
15(8), 515–528 (2002)
Independent Component Analysis
SEUNGJIN CHOI
Department of Computer Science, Pohang University
of Science and Technology, Korea
Synonyms
Blind source separation; Independent factor analysis
Definition
Independent component analysis (ICA) is a statistical
method, the goal of which is to decompose multivari-
ate data into a linear sum of non-orthogonal basis
vectors with coefficients (encoding variables, latent
variables, hidden variables) being statistically indepen-
dent. ICA generalizes a widely-used subspace analysis
method such as principal component analysis (PCA)
and factor analysis, allowing latent variables to be non-
Gaussian and basis vectors to be non-orthogonal in
general. Thus, ICA is a density estimation method
where a linear model is learnt such that the probability
distribution of the observed data is best captured,
while factor analysis aims at best modeling the covari-
ance structure of the observed data.
Introduction
Linear latent variable model assumes that m-dimensional
observed data x
t
2 R
m
is generated by
x
t
¼ a
1
s
1;t
þ a
2
s
2;t
þa
n
s
n;t
þ E
t
; ð1Þ
where a
i
2 R
m
are basis vectors and s
i,t
are latent
variables (hidden variables, coefficients, encoding
variables) which are introduced for parsimonious
representation (n m). Modeling uncertainty or
noise is absorbed in E
t
2 R
m
. Neglecting the uncertainty
E
t
in (1), the linear latent varia ble model is nothing but
Independent Component Analysis
I
735
I

linear transformation. For example, if a
i
are chosen
as Fourier or Wavelet basis vectors, then s
i,t
are asso-
ciated Fourier or Wavelet coefficients that are served
as features in pattern recognition. In the case where
a
i
are orthonormal, it is referred to as orthogonal
transformation. Subspace analysis methods that are
popular in pattern recognition also considers the linear
model (1), assuming Gaussian factors s
i,t
and (isotro-
pic) independent Gaussian noise E
t
. In such a case,
model parameters such as a
i
and diagonal covariance
matrix of E
t
are estimated by expectation maximiza-
tion algorithms [1].
The simplest form of independent component
analysis (ICA) considers a noise-free linear latent vari-
able model with assuming m ¼ n, where observed
variables x
t
2 R
n
is assumed to be generated by
x
t
¼
X
n
i¼1
a
i
s
i;t
¼ As
t
; ð2Þ
where A ¼½a
1
; ...; a
n
2R
mn
is referred to as mi xing
matrix and s
t
¼½s
1;t
; ...; s
n;t
>
2 R
n
are constrained
to have independent components. ICA generalizes PCA
in the sense that latent variables (components) are
non-Gaussian and A is allowed to be non-orthogonal
transformation, whereas PCA considers only orthogo-
nal transformation and implicitly assumes Gaussian
components. Fig. 1 shows a simple example, emphasiz-
ing the main difference between PCA and ICA.
Exemplary basis face images learned by PCA and ICA
are shown in Fig. 2.
Methods
The task of ICA is to estimate the mixing matrix A or
its inverse W ¼ A
1
(referred to as dexming matrix)
such that elem ents of the estimate y
t
¼ A
1
x
t
¼ Wx
t
are as independent as possible. A variety of methods
for ICA have been developed so far. The followi ng
books are good resources for comprehensive under-
standing on ICA: Lee [2] where a unifi ed view of several
different principles, including
▶ mutual information
minimization, informati on maximization, maximum
likelihood estimation, and negentropy maximization
are found; Hyva
¨
rinen et al. [3] where many useful
fundamental background on ICA and FastICA algo-
rithms are found; Cichocki and Amari [4] where vari-
ous methods of source separation in the perspective of
signal processing can be found. In addition to these
books, several tutorial or review papers are also avail-
able [5, 6].
Methods for ICA can be categorized into two
groups:
Unsupervised learning methods: Factorial coding
is a primary principle for efficient information
representation and is closely related to
Independent Component Analysis. Figure 1 Two-dimensional data with two main arms are fitted by two different
basis vectors: (a) PCA makes the implicit assumption that the data have a Gaussian distribution and determines the
optimal basis vectors that are orthogonal, which are not efficient at representing non-orthogonal distributions; (b) ICA
does not require that the basis vectors be orthogonal and considers non-Gaussian distributions, which is more suitable in
fitting more general types of distributions.
736
I
Independent Component Analysis
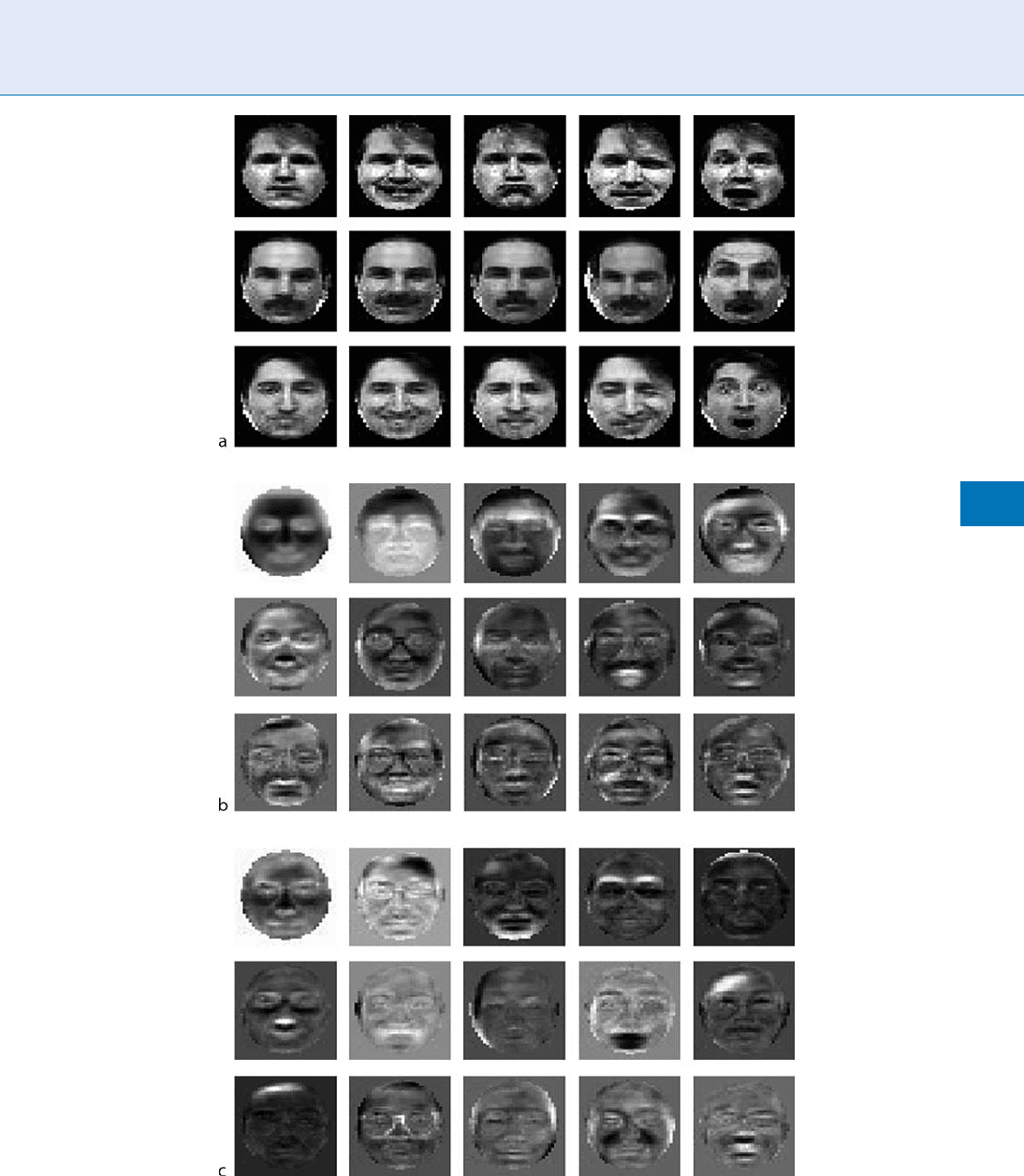
Independent Component Analysis. Figure 2 Sample face images from Yale DB are shown in (a). First 20 basis images
determined by: (b) PCA; (c) ICA. A first application of ICA to face recognition is found in [25].
Independent Component Analysis
I
737
I

redundancy reduction that provides a principled
method for unsupervised learning [7]. It is also
related to ICA, aiming at a linear data representa-
tion that best model the probability distribution of
the data, so higher-order statistical structure is
incorporated.
– Maximum likelihood estimation (Kullback
matching): It is well known that maximum
likelihood estimation is equivalent to Kullback
matching where the optimal model is esti-
mated by minimizing Kullback-Leibler (KL)
divergence between empirical distribution and
model distribution. We consider KL divergence
from the empirical distribution
~
pðxÞ to the
model distribution p
y
(x)
KL½
~
pðxÞjjp
y
ðxÞ ¼
Z
~
pðxÞlog
~
pðxÞ
p
y
ðxÞ
dx
¼Hð
~
pÞ
Z
~
pðxÞlog p
y
ðxÞdx;
ð3Þ
where Hð
~
pÞ¼
R
~
pðxÞlog
~
pðxÞdx is the entropy
of
~
p. Given a set of data points, fx
1
; ...; x
N
gdrawn
from the underlying distribution p(x), the em piri-
cal distributio n
~
pðxÞ puts probability
1
N
on each
data point, leading to
~
pðxÞ¼
1
N
X
N
t¼1
dðx x
t
Þ: ð4Þ
It follows from (3) that
arg
u
minKL½
~
pðxÞjjp
y
ðxÞ arg
u
max log p
y
ðxÞ
hi
~
p
; ð5Þ
where
hi
~
p
represents the expectation with respect
to the distribution
~
p. Plugging (4) into the right-
hand side of (3), leads to
log p
y
ðxÞ
hi
~
p
¼
1
N
Z
X
t¼1
Ndðx x
t
Þlog p
y
ðxÞdx
¼
1
N
X
N
t¼1
log p
y
ðx
t
Þ:
ð6Þ
Apart from the scaling factor
1
N
, this is just the
log-likelihood function. In other words, maximum
likelihood estimation is obtained from the minimi-
zation of (3).
– Mutual information minimization: M utual infor-
mation is a measure for statistical independence.
Demixing matrix W is learned such that the
mutual information of y ¼ Wx is minimized,
leading to the following objective function:
J
mi
¼
Z
pðyÞlog
pðyÞ
Q
n
i¼1
p
i
ðy
i
Þ
2
6
6
4
3
7
7
5
dy
¼HðyÞ
X
n
i¼1
log p
i
ðy
i
Þ
*+
:
ð7Þ
Note that pðyÞ¼
pðxÞ
jdet W j
. Thus, the objective func-
tion (7) is given by
J
mi
¼log jdet W j
X
n
i¼1
log p
i
ðy
i
Þ
; ð8Þ
where hlogp(x)i is left out since it does not depend
on parameters W.
– Information maximization: Infomax [8] involves
the maximization of the output entropy z ¼ g(y)
where y ¼ Wx and g() is a squashing function
(e.g., g
i
ðy
i
Þ¼
1
1þe
y
i
). It was shown that info-
max contrast maximization is equivalent to the
minimization of KL divergence between the
distribution of y ¼ Wx and the distribution
pðsÞ¼
Q
n
i¼1
p
i
ðs
i
Þ. In fact, infomax is nothing
but mutual information minimization in ICA
framework.
– Negentropy maximization: Negative entropy or
negentropy is a measure of distance to Gaus-
sianity, yielding the larger value for random
variable whose distribution is far from Gauss-
ian. Negentropy is always nonnegative and
vanishes if and only if the random variable is
Gaussian. Negnetropy is defined as
JðyÞ¼Hðy
G
ÞHðyÞ; ð9Þ
where y
G
is a Gaussian random vector whose
mean vector and covariance matrix are the same
as y. It is shown that the negentropy maximization
is equivalent to the mutual information minimiza-
tion [2].
Algebraic methods: Algebraic methods have been de-
veloped mainly for blind source separation (BSS), the
task of which is to restore unknown sourc es s without
the knowledge of A, given the observed data x.
They, in general, are based on eigen-decomposition
of certai n statistical information matrix such as
covariance matrix (or correlation matrix), higher-
order moment matrix, or cumulant matrix.
– Generalized eigenvalue decomposition: Simulta-
neous diagonalization of two covariance matrices
738
I
Independent Component Analysis

with distinct eigenvalues achieves BSS. Earlier
work includes FOBI [9] and AMUSE [10].
– Joint approximate diagonalization: Statistical
efficiency increases when several covariance
matrices or cumulant matrices are considered
for joint approximate diagonalization. JADE
[11] considers 4th-order cumulant matrices,
SOBI [12] uses time-delayed correlation matri-
ces, and SEON S [13] incorporates time-varying
correlation matrices. All these methods use
Jacobi rotation to jointly diagonalize the matri-
ces considered. On the other hand, correlation
matching is an alternative metho d, which is
solved by least squares technique [14, 15].
Algorithms
Latent variables s
i
or their estimates y
i
are assumed
to be statistically independe nt, i.e., the joint dis-
tribution is factored into the product of marginal
distributions
pðsÞ¼
Y
n
i¼1
p
i
ðs
i
Þ; or pðyÞ¼
Y
n
i¼1
p
i
ðy
i
Þ: ð10Þ
It follows from the relation pðxÞ¼pðsÞ=jdet Aj that
the single factor of log-likelihood is given by
log p
y
ðxÞ¼log jdet Ajþ
X
n
i¼1
log p
i
ðs
i
Þ: ð11Þ
Then the objective function for on-line learning is
given by
J¼log p
y
ðxÞ¼log jdet Aj
X
n
i¼1
log p
i
ðs
i
Þ; ð12Þ
which is equivalent to (8) that is used for mutual
information minimization.
The gradient descent method gives a learning algo-
rithm for A that has the form
DA ¼
@J
@A
¼A
>
I ’ðsÞs
>
; ð13Þ
where >0 is the learning rate and ’(s) is the negative
score function whose ith element ’
i
(s
i
) is given by
’
i
ðs
i
Þ¼
d log p
i
ðs
i
Þ
ds
i
: ð14Þ
Employing the natural gradient [16], we have
DA ¼AA
>
@L
@A
¼AI ’ðsÞs
>
: ð15Þ
At each iteration, latent variables s are computed by
s ¼ A
1
x using the current estimate of A. Then the
value of A is updated by (15). This procedure is repeat-
ed until A converges.
The function ’
i
(s
i
) depends on the prior p
i
(s
i
) that
has to be specified in advance. Depending to the choice
of prior, we have different data representation. In
the case of Laplacian prior, the function ’
i
(s
i
) has the
form
’
i
ðs
i
Þ¼sgnðs
i
Þ; ð16Þ
where sgn() is the signum function. Sparseness con-
straint was shown to be useful to describe the receptiv e
field characteristics of simple cells in primary visual cor-
tex [17]. Generalized Gaussian prior for s
i
is useful in
approximating most of uni-modal distributions [18].
Alternatively, it is possible to learn A
1
instead of A.
The A
1
coincides w ith the ICA filter [8]. If we define
W ¼ A
1
, then the natural gradient learning algo-
rithm for W is given by
DW ¼ I ’ðyÞy
>
W : ð17Þ
This is a well-known ICA algorithm [19].
Softwares
We briefly introduce several ICA softwares so that one
can immediately play with these MATALB codes or
toolboxes to see how they are working on data sets.
ICA Central (URL: http://www.tsi.enst.fr/icacentral/)
was created in 1999 to promote research on ICA
and blind source separation by means of public mail-
ing lists, a repository of data sets, a repository of
ICA/BSS algorithms, and so on. ICA Central might
be the first place where you can find data sets and
ICA algorithms. In addition, several widely-used soft-
wares include
1. ICALAB Toolboxes (http://www.bsp.brain.riken.go.
jp/ICALAB/): ICALAB is an ICA Matlab software
toolbox developed in laboratory for Advanced
Brain Signal Processing in RIKEN Brain Science
Institute, Japan. It consists of two independent
packages: ICALAB for signal processing and
Independent Component Analysis
I
739
I