Мангейм Дж.Б., Рич Р.К. Политология. Методы исследования
Подождите немного. Документ загружается.

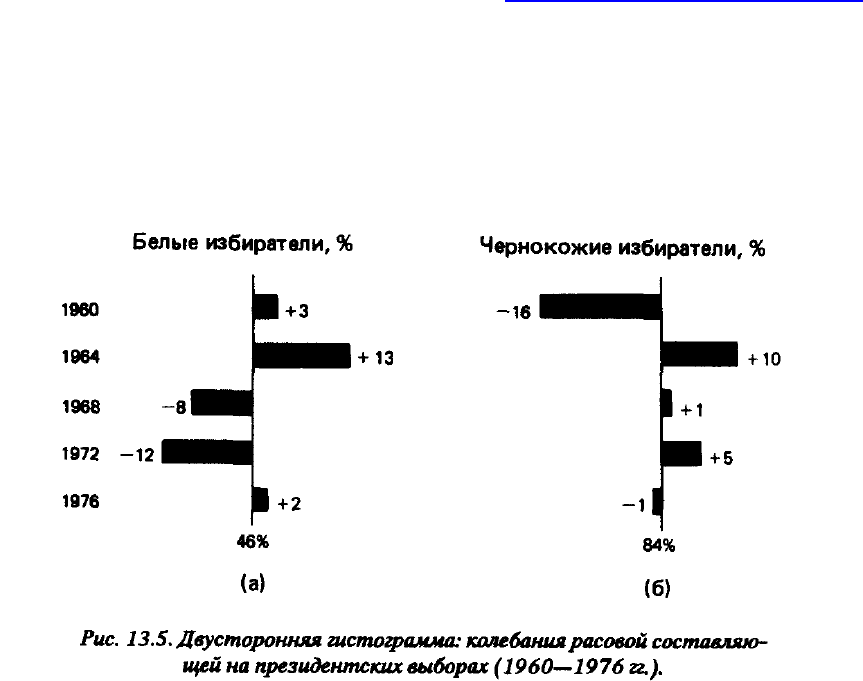
Еще одним видом графиков, который часто встречается в политологической
литературе, является двустороння гистограмма. Двусторонняя гистограмма –
это расположенный [c.385] в двух направлениях график, используемый для
того, чтобы показать колебания сверх или менее какой-то нормы,
представленной центральной линией. Две типичные двусторонние гистограммы
изображены на рис. 135. На рис. 13.5а центральная линия – это среднее
(усредненное) количество белых, голосовавших за демократов на
президентских выборах в 1960–1976 гг., выраженное в процентах (46%).
Столбцы представляют колебания вокруг среднего значения на каждых из пяти
выборов; при этом столбцы справа от линии обозначают поддержку демократов
белыми избирателями со значением выше среднего, а слева – ниже среднего.
Протяженность столбцов показывает степень отклонения от среднего, цифры
обозначают точное значение разницы. Например, среднее значение (46%) плюс
отклонение (3%) в 1960 г. вместе составляют 49% проголосовавших “за” в том
году, который отмечен в табл. 13.1. Рис. 13-5 представляет схожий анализ
голосования чернокожих избирателей, основанный на среднем количестве
голосовавших “за” в 84%.
Эти цифры добавляют еще одну грань в анализ данных, представленных в табл.
13.1, и, взятые вместе, они доказывают, что в I960 г. негры представляли
довольно серьезную оппозицию партии, чем в более поздний период; что как
белые, так и чернокожие избиратели оказали необычно сильную поддержку
демократам в 1964 г.; что белые покидали партию в 1968 и 1972 гг., тогда как
поддержка чернокожих избирателей была чуть выше среднего, и что уровень
голосования обеих [c.386] групп в 1976 г. был приблизительно равен его
среднему значению за весь рассматриваемый период. Если добавить эту новую
информацию к нашем прежним выводам, то мы получим более полную картину
роли белых и чернокожих избирателей в успехах демократической партии в эти
годы. В целом можно сказать, что информация, заключенная в двусторонних
гистограммах, углубляет и дополняет ту, что можно получить при
использовании других графических способов. [c.387]
ТАБЛИЦА ВЗАИМНОЙ СОПРЯЖЕННОСТИ ПРИЗНАКОВ
Еще одна форма табличного изображения данных заслуживает нашего
внимания, прежде чем мы перейдем к обсуждению статистических процедур. В
самом деле, это, наверное, наиболее распространенная в современных
политологических исследованиях форма таблиц; она может служить основой
для некоторых статистических расчетов, которые мы обсудим в следующей
главе. Эта форма подачи данных известна как таблица взаимной
сопряженности признаков (см. табл. 13.2 и 13.3).
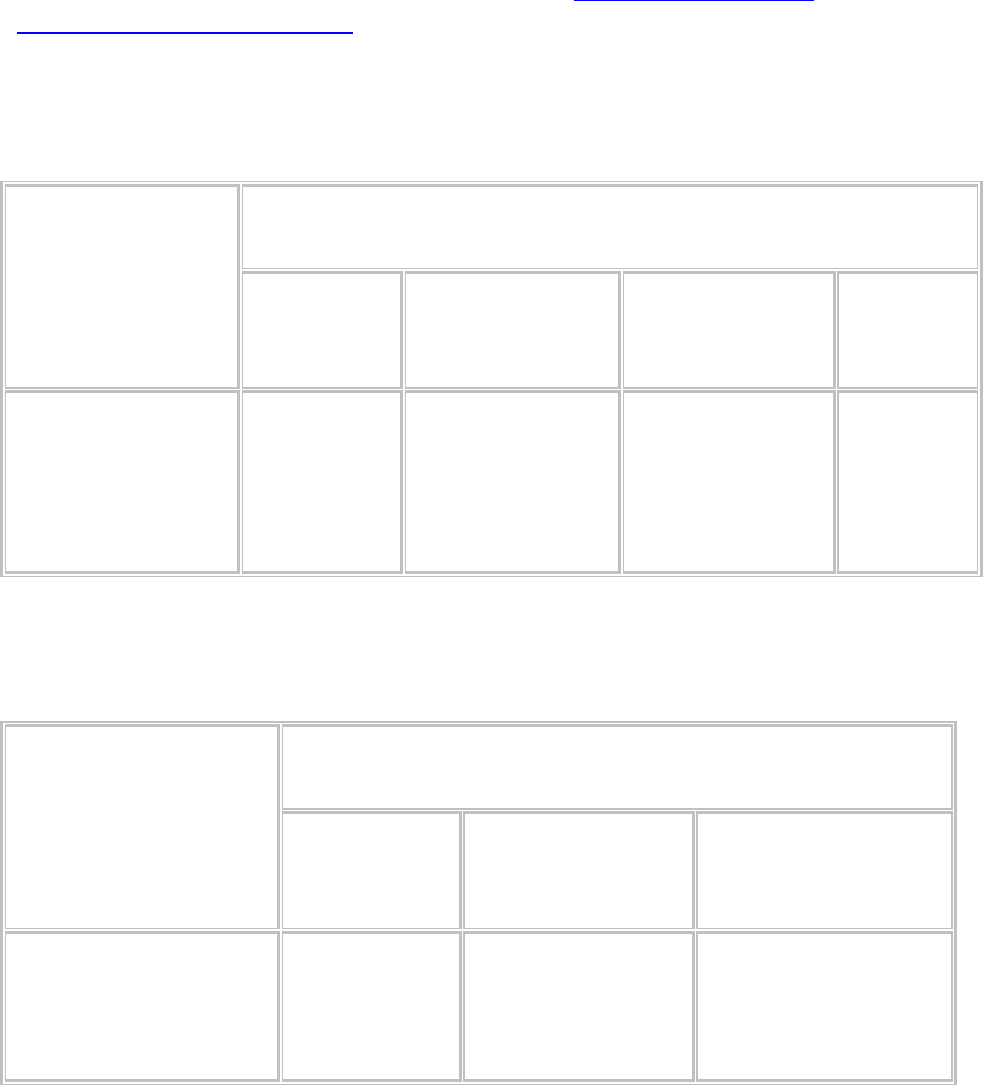
Таблица 13.2.
Расовые различия на президентских выборах 1964 г., %
Расовая
принадлежность
Голосование за кандидата
от
демократов
от
республиканцев
Всего,
%
Число
случаев
Белые
Чернокожие
Все
проголосовавшие
59
94
61
41
6
39
100
100
100
1 350
150
1 500
Таблица 13.3
Расовые различия на президентских выборах 1972 г., %
Голосование
за кандидата
Расовая принадлежность
Белые Чернокожие Все
проголосовавшие
От демократов
От республиканцев
Всего, %
34
66
100
89
11
100
40
60
100

Число случаев 1 350 150 1 500
[c.387]
По формату и структуре таблица взаимной сопряженности признаков похожа
на перечневую таблицу, о которой говорилось ранее, однако содержание у нее
совершенно другое. Таблицы взаимной сопряженности признаков в большей
степени основаны на предположениях и построены так, чтобы облегчить
изучение взаимосвязей между переменными. Таблица 13.2, например,
суммирует взаимосвязь между расовой принадлежностью и голосованием за
президента в 1964 г., табл. 13.3 подытоживает те же сведения за 1972 г. В обоих
случаях приведены данные гипотетического обследования 1 500 избирателей.
Таблицы построены так, чтобы позволить нам изучить гипотезу, что в любом из
приведенных годов чернокожие избиратели по той или иной причине чаще
голосуют за демократов, чем белые.
Каждый пункт перечисления в таблице (частный или итоговый) называется
графой. Каждая из этих таблиц, таким образом, имеет четыре графы. Таблицы
могут быть также описаны количеством содержащих в них рядов и колонок,
если каждый ряд представляет определенное значение одной переменной, а
каждая колонка – определенное значение другой, т. е. табл. 13.2 и 13.3 можно
считать таблицами 2х2 (два на два), поскольку каждая имеет два ряда и две
колонки.
Таблицы сопряженности всегда строятся так, что данные о независимой или
объясняющей переменной суммируются. В нашем случае такой переменной
является расовая принадлежность. Это значит, что если таблица содержит
процентные распределения, то они будут основаны на 100%-ном итоге по
независимой переменной. Так, в табл. 13.2 утверждается, что в 1964 г. 59%
белых голосовали за демократов, но отнюдь не то, что 59% всех
проголосовавших за демократов были белыми. Подсчитать процентные
распределения возможно и по другому, но в нашем случае это не имеет никакой
информационной ценности, поскольку партийные привязанности неизбежно
приобретаются позже, чем расовая принадлежность. В 1-й строке таблицы
суммируются процентные распределения для всех (для 100%) белых
избирателей, во 2-й строке – для всех чернокожих избирателей, и в 3-й строке –
для всех проголосовавших. Колонка, обозначенная “Число случаев”, суммирует
количество респондентов [c.388] нашего гипотетического обследования,
которые были отнесены к каждой из групп. Сведения этой колонки определяют
частотное распределение (оно будет рассмотрено в следующей главе) и из-за
своего расположения в таблице часто называются маргинальными.
Независимая переменная в таблице сопряженности может располагаться как по
ряду (см. табл. 13.2), так и по колонке (см. табл. 13.3). Оба способа
распространены в научной литературе. Однако, если уж вы выбрали ту или
иную форму, важно следовать ей до конца исследования, с тем чтобы не путать
читателя.
При изучении таких таблиц, как эти, часто бывает возможно в общих словах
сказать, насколько данные подтверждают гипотезу. Так, например, из обеих
таблиц – 13.2 и 13.3 – ясно, что чернокожие избиратели постоянно голосовали
более продемократически, чем белые. В 1972 г. чернокожие избиратели отдали
большую часть голосов демократам, тогда как белые – республиканцам, и даже
в 1964 г., когда обе группы голосовали в основном за демократов, чернокожие
избиратели составили более надежную их опору, чем белые. Тем не менее эти
прикидки “на глазок” в лучшем случае грубы, и, когда, таблицы сложнее, чем
эти, состоят из многих граф или имеют не столь прямолинейные результаты,
подобные прикидки часто ненадежны. В следующей главе мы рассмотрим
некоторые статистические способы, которые помогают более точно установить
степень соответствия гипотезы имеющимся данным. [c.389]
НЕКОТОРЫЕ ПРЕДОСТЕРЕЖЕНИЯ
В заключение давайте еще раз отметим три важнейших аспекта использования
таблиц и графиков.
Во-первых, они должны быть и наглядны и конструктивны. Как часть самого
исследовательского процесса, они могут быть чрезвычайно полезны для
наиболее глубокой разработки нашей концепции и для твердого понимания
того, что же наши данные говорят нам. Гибкость и способность к новым
формам анализа могут значительно помочь в углублении наших знаний о
политических событиях, а методики, даже такие простые, как эти, окажут
действие в оформлении выводов. [c.389]
Во-вторых, таблицы и графики нужно правильно применять. Даже из этого
короткого обзора ясно, что совершенно не исключена возможность ошибочного
представления результатов из-за небольшого искажения методики, и точно так
же не исключена возможность, что кто-то будет одурачен этим бездумным
злоупотреблением. У исследователей существуют моральные обязательства по
отношению к другим – излагать свои выводы не только точно, но и правдиво –
и интеллектуальные обязательства по отношению к себе – тщательно их
проверять. Эти обязательства составляют краеугольный камень исследования.
Мы не должны забывать о них.
Наконец, ваша работа не должны быть перегружена таблицами и графиками.
Обилие подобного материала забивает текст и ухудшает его восприятие.
Авторское решение включить таблицу или диаграмму в текст воспринимается
читателем как сигнал к тому, что автор придает особое значение заключенной в
них информации. Автор обязан делать выбор, а не просто предлагать читателю
“шведский стол” информации. Такая осмотрительность не только повышает

ценность работы, но и вынуждает его или ее подумать и решить, что важнее, и,
таким образом, вносит дополнительный вклад в работу. [c.390]
Дополнительная литература
Прекрасным руководством по применению таблиц, схем и диаграмм в
политологических исследованиях является кн.: Веnsоn О. Political Science
Laboratory. – Columbus (Oh.): Merrill, 1969, ch. 2,3. Полезная информация о
графическом изложении данных содержится в: Spear М.Е. Practical Charting
Techniques. – N.Y.: McGraw-Hill, 1969; Rogers А.С. Graphic Charts Handbook. –
Washington (D.C): Public Affairs Press, 1961; Smart L.E., Arnold S. Practical Rules
for Grade Presentation of Business Statistics. – Columbus (Oh.): Bureau of Business
Research, Ohio State University, 1947; Тufte Е.R. The Visual Display of Quantitative
Information. – Cheshire (Conn.): Grades Press, 1983. Этот же автор в кн.:
Envisioning Information. – Cheshire, Conn.: Graphics Press, 1994, приводит много
примеров использования графических методик для обобщения данных. Об
ошибках при графическом отображении информации можно узнать из кн.: Huff
D. How to Lie with Statistics. - N.Y.: Norton, 1954.
Одним из лучших примеров использования графических методик можно
считать работу: Vегbа S., Niе N. Political Participation in American Political
Democracy and Social Equality. – N.Y.: Harper and Row 1972.
Далее
14. СТАТИСТИКА I: АНАЛИЗ ОДНОМЕРНЫХ РАСПРЕДЕЛЕНИЙ
К оглавлению
ПРИМЕЧАНИЯ
1
Неверно или небрежно шкалированная ось может запутать читателя или даже
исследователя, преувеличивающего или недооценивающего порядок величин
или степень изменений. Конечно, усеченные графики (те, в которые не
включены наименьшие значения) или протяженные графики (те, в которых
масштаб увеличен для одной группы значений и уменьшен для другой) могут
быть умышленно использованы для введения невнимательного читателя в
заблуждение. К счастью, использование подобных приемов более характерно
для рекламы или комментариев к исследованиям, чем для научной литературы.
Вернуться к тексту
2
Цифры мало отличаются от представленных в таблице частично в результате
округления, частично потому, что действительное представительство, которое
лежит в основе данных табл. 13.1, лишь приближается к 90% и 10%,
использованным здесь. Если бы мы взяли действительные данные о
представительстве, так же как и частичные процентные сведения таблицы, в
сумме они были бы сопоставимы с количеством голосующих за демократов.
Очевидно, что особенно наши подсчеты будут отличаться от реальных данных

таблицы за 1960 и 1964 гг., когда негры в некоторых районах все еще активно
воздерживались от голосования и их представительство было относительно
ниже.
Вернуться к тексту

Мангейм Дж.Б., Рич Р.К. Политология. Методы исследования: Пер. с англ. /
Предисловие А.К. Соколова. – М.: Издательство “Весь Мир”, 1997. – 544 с.
Красным шрифтом в квадратных скобках обозначается конец текста на
соответствующей странице печатного оригинала данного издания
14. СТАТИСТИКА I: АНАЛИЗ ОДНОМЕРНЫХ РАСПРЕДЕЛЕНИЙ
Зачастую в политологических исследованиях одни таблицы и графики не дают
достаточных сведений о данных для успешного решения исследовательских
задач. Иногда это проблема сложности (или слишком много градаций
переменных, или слишком большой массив, или задействовано слишком много
переменных, для того чтобы данные годились для непосредственного анализа),
иногда – вопрос точности (степень различий небольших колебаний переменных
может оказаться важной, а при оценке таблицы или схемы “на глазок” их
бывает трудно уловить). В случаях, подобных нашему, когда нужен более
глубокий анализ, ученые прибегают к статистическому анализу.
Статистика с этой точки зрения – это количественные значения, которые
оценивают распределения градаций или взаимосвязи между переменными.
Статистика является своего рода математической стенографией, дающей
возможность визуально и с большой точностью оценить, что показывают (а
иногда – что не показывают) данные. “Каковы политико-философские взгляды
типичного студента колледжа? Всегда ли белые избиратели отличаются в своих
партийных пристрастиях от негров? Какие действия или ситуации в мировом
сообществе вероятнее всего могут привести к возникновению вооруженного
конфликта? “Если мы располагаем верными данными для анализа, статистика в
состоянии ответить как на эти, так и на многие другие вопросы.
Статистика чрезвычайно сложна. Однако так же верно и то, что многие из
основных принципов и приемов статистического анализа необычайно просты,
очень быстро запоминаются и могут увести вас в изучении вашего предмета
гораздо дальше, чем вы думаете. Фактически если вы изучали алгебру в
средней школе, то вы знаете о математике все, что вам понадобится; вы будете
удивлены, насколько интуитивно очевидны многие математические выкладки.
[c.392]
Следует уточнить, что эта глава и две последующие не научат вас ни всему
тому, что можно узнать о статистике, ни даже всему тому, что можно узнать о
конкретных статистических методах, которые мы будем обсуждать. Тем не
менее к тому моменту, когда вы прочитаете эти главы, вы будете иметь
достаточно полное представление о том, что такое статистическая процедура и
как ее можно применять (или почему ее нужно применять); у вас также
появится некоторое понимание того, что лежит за цифрами и подсчетами; вы
сможете относительно легко применять некоторые специальные статистические

методы. Все вместе эти навыки позволят вам использовать статистический
анализ в своем исследовании и глубже и критичнее воспринимать то, что вы
читаете в научных журналах и других политологических исследованиях.
Эту главу мы посвятим изучению статистических методов, которые позволят
нам ответить на следующие вопросы о массиве данных: “Как выглядят
одномерные распределения? Как выглядит типичная единица массива?
Насколько она типична?”
В каждом случае мы рассмотрим различные статистические методы для
различных типов измерения – номинального, порядкового и интервального. Из
гл. 3 вы помните, что эти типы (уровни) отличаются один от другого тем, что
первый просто дифференцирует категории, второй ранжирует их, в третьем
устанавливается постоянный интервал различий между ними. Иными словами,
цифры эминальной, порядковой и интервальной шкал есть различные виды
цифр с разными свойствами. Если точнее, цифры номинального измерения
мало содержательны, данные не очень много могут сказать нам. Поскольку они
лишь разделяют объекты на группы и служат не более чем ярлыками для этих
групп, их нельзя складывать или вычитать. Соответственно применить сложные
методы статистического анализа к номинальным данным нельзя. (цифры же
интервальных шкал гораздо более содержательны и точны, они несут гораздо
больше информации о тех данных, которые они представляют. Их можно
складывать, вычитать, возводить в квадрат и изменять по-всякому. В результате
они дают возможность более гибкого подхода и применения более сложных
методов анализа. Именно по этим причинам к разным уровням измерения
[c.393] применяются разные методики. И именно по этим причинам, конечно,
необходимо применять эти методики правильно. [c.394]
ИЗМЕРЕНИЕ СРЕДНЕЙ ТЕНДЕНЦИИ И ДИСПЕРСИИ
Для описания распределения признаков по значениям одной переменной
используют два типа статистических процедур. Первый – измерение средней
арифметической величины признака – помогает нам выявить наиболее
типичные значения, одно или несколько, которые наилучшим способом
представляют весь комплекс признаков по этой переменной. Вообразите, что
нам сказали, будто так называемый средний американец – это “синий
воротничок”, получивший среднее образование и вместе со своей женой
имеющий в среднем 1,7 ребенка. Понятно, что не каждый американец отвечает
этим требованиям, но если бросить на американцев этакий общий взгляд, то
приведенный набор характеристик может оказаться весьма близким к тому
общему впечатлению, которое у нас сложится. Вот именно такое представление
об усредненном или типичном случае мы получаем при измерении средней
арифметической величины. И именно это измерение было использовано при
выявлении наиболее типичных свойств американцев.
Однако, как уже отмечалось, не все американцы обладают такими
характеристиками. Многие являются “белыми воротничками”, либо
специалистами, либо даже безработными, некоторые закончили только
начальную школу, у других – более высокое образование, иные имеют 10 или
20 детей, другие же не женаты и детей не имеют. Иными словами, “типичный”
американец представляет лишь среднюю тенденцию внутри совокупности, но
не отражает точно каждый отдельный признак. Ну, а поскольку такой
типичный признак найден, мы вправе задать вопросы:
“Насколько это типично? Насколько правильно эти усредненные признаки
отражают распределение свойств всех единиц массива по данной переменной?”
Мы ответим на них, если используем другой тип статистических расчетов –
дисперсию. Измеряя дисперсию, мы узнаем, как колеблется (варьирует)
отклонение от того среднего значения, которое мы нашли, в каких случаях
можно быть уверенным, что наше среднее значимо, и не является ли
отклонение [c.394] настолько большим, что наиболее типичный признак на
самом деле не является репрезентативным для всей совокупности.
В связи с этим возникает важная проблема, которую дует обсудить, прежде чем
двигаться куда-либо дальше. Статистика – это могучее средство анализа; она
можно сказать о наших данных гораздо больше, чем можно выявить любым
другим путем. Но сама по себе статистика бездумна. Можно произвести любые
статистические счеты на любом массиве данных и, казалось бы, выжать из
данных все до последней капли. Однако многие из этих “результатов” по двум
причинам могут оказаться бессмысленными. Первую причину мы уже
обсуждали, логика ее станет яснее по мере дальнейшего продвижения. Говоря
проще, уровень сложности анализа может превосходить уровень сложности,
заложенный в данных. Если выбранный нами метод требует сложить две
цифры, а данные основаны на номинальной шкале, для которой неприемлема
сама концепция сложения, то вообще-то механически можно сложить значения
двух кодов, однако результат этого окажется бесполезным. Так, если код 1
представляет рабочих – “синих воротничков”, код 2 – “белых воротничков”, а 3
– специалистов, то мы, конечно, можем к ому прибавить два и получить три, но
неужели мы действительно будем утверждать, что один рабочий – “синий
воротничок” плюс один рабочий – “белый воротничок” равны одному
специалисту? Конечно, нет.
Другая причина, по которой результаты статистические расчетов могут
оказаться незначимыми, –это то, что одна статистика сама по себе часто не
может представить всю картину целиком. Если единственный наиболее
типичный уровень образования американцев – это средняя школа, но только
25% всего населения достигли этого уровня и остановились на нем, то
насколько много в действительности может сказать нам это среднее значение?
Не так уж много. И много ли вы знаете людей, которые действительно имеют
1,7 ребенка? Таким образом, хотя мы можем точно подсчитать и представить
эти цифры, нельзя останавливаться только на них. Каждое измерение средней
арифметической должно быть взвешено или оценено сопутствующим
измерением дисперсии. И еще (мы обсудим это позже): всегда, когда мы имеем
дело с [c.395] расчетами, каждое измерение взаимосвязей между двумя
переменными следует сопровождать измерением статистической значимости,
т.е. следует обозначить, насколько точно найденные величины представляют
существенные связи между данными переменными. Таким образом,
статистические расчеты должны не только соответствовать уровню измерений
данных, но и быть существенно значимыми, если мы хотим получить от них
максимум пользы.
Любое измерение средней тенденции и дисперсии основано на общей оценке
градаций переменных и единиц массива, которая называется частотным
распределением. Частотное распределение – это упорядоченный подсчет
количества признаков по каждому значению какой-либо переменной.
Представьте, например, что мы задали 100 респондентам вопрос об их занятии
в настоящее время и затем распределили их ответы по типам. Тогда частотное
распределение для переменной “тип занятий” может выглядеть так, как это
показано в табл. 14.1.
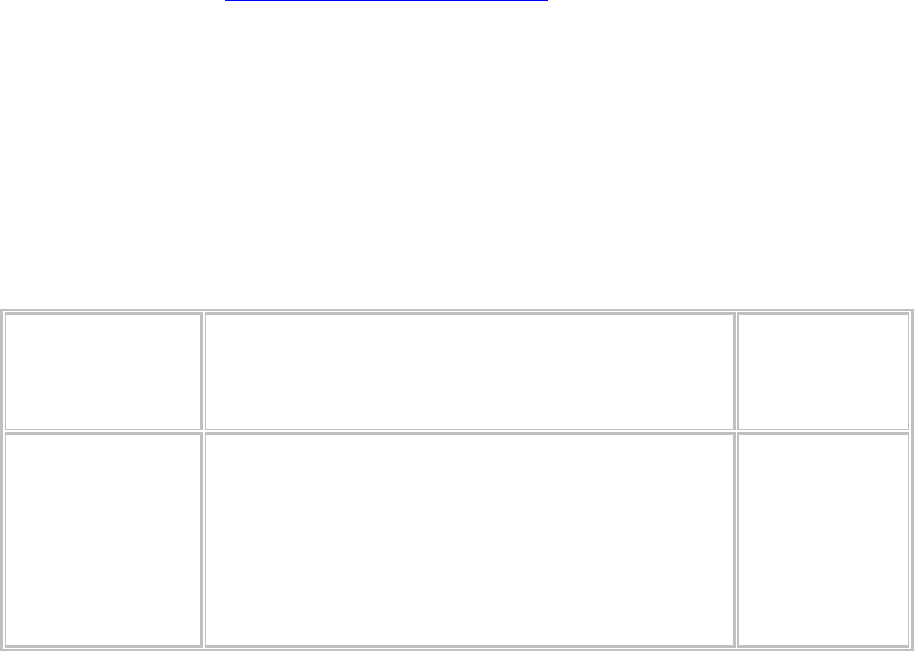
Таблица 14.1.
Частотное распределение: типы занятий респондентов
Код Значение Число
случаев
1
2
3
4
5
“Синие воротнички”
“Белые воротнички”
Специалисты
Фермеры
Безработные
25
23
22
20
10
В частотном распределении исследователь просто перечисляет все значения
переменной и показывает, сколько имеется случаев каждого значения. Та же
самая информация может быть представлена в виде гистограммы, как показано
на рис. 14.1. Используя эту информацию, можно выделить наиболее типичный
случай и определить его репрезентативность. [c.396]