Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


8. Mitting, J. in RvGray(2003) EWCA 1001
9. R v Gardner (2004) EWCA 1639
10. Wilcox, R.: Facial Feature Prevalence Survey. London: Home
Office Research, Development and Statistics Directorate. PRAS
33 (1994)
11. Pentland, A., Moshaddam, B., Starber, T.: View-based and mod-
ular Eigenfaces for face recognition. In: Proceedings of the IEEE
Conference on Computerised Vision and Pattern Recognition
1994, pp. 84–91 (1993)
12. Wiskott, L., Fellous, J., Kruger, N., von der Malsburg, C.: Face
recognition and gender determination. In: Proceedings of the
International Workshop on Automatic Face and Gesture Recog-
nition. Zurich (1995)
13. Phillips, P., Wechsler, H., Huang, J., Rauss, P.: The FERET data-
base and evaluation procedure for face recognition algorithms.
Image Vis. Comput. J. 16, 295–306 (1998)
14. Phillips, P., Moon, H., Rizvi, S., Rauss, P.: The FERETevaluation.
In: Face Recognition from Theory to Applications. Springer,
Berlin (1997)
15. Thomas, R.: As UK crime outstrips the US, a hidden eye is
watching: Police switch on a camera that recognizes your face.
The Observer, 11 October 1998, p. 5
16. Wilkinson, C.: Forensic Facial Reconstruction, Cambridge Uni-
versity Press, Cambridge (2004)
17. Auslebrooke, W.A., Becker, P.J., Iscan, M.Y.: Facial Soft Tissue
Thickness in the Adult Male Zulu. Forensic Sci. Int. 79, 83–102
(1996)
18. Lebedinskaya, G.U., Balueva, T.S., Veselovskaya, E.B.: Develop-
ment of Methodological Principles for Reconstruction of
the Face on the Basis of Skull Material, in Forensic Analysis
of the Skull. pp. 183–198 Wiley-Liss, New York, (1993)
19. Wilkinson, C.M., Whittaker, D.K.: Skull Reassembly and the
Implications for Forensic Facial Reconstruction. Sci. Justice
41(3), 5–6 (2002)
20. Vanezis, P., Blowes, R.W., Linney, A.D., Tan, A.C., Richards, R.,
Neave, R.: Application of 3-D computer graphics for facial
reconstruction and comparison with sculpting techniques.
Forensic Sci. Int. 42, 69–84 (1989)
Facial Action Coding
▶ Facial Expression Recognition
Facial Changes
▶ Face Variation
Facial Expression Analysis
▶ Facial Expression Recognition
Facial Expression Recognition
MAJA PANTIC
Department of Computing Imperial College London,
London, UK
Synonyms
Facial Expression Analysis; Facial Action Coding
Definition
Facial expression recognition is a process performed by
humans or computers, which consists of:
1. Locating faces in the scene (e.g., in an image; this
step is also referred to as face detection),
2. Extracting facial features from the detected face
region (e.g., detecting the shape of facial compo-
nents or describing the texture of the skin in a facial
area; this step is referred to as facial feature
extraction),
3. Analyzing the motion of facial features and/or
the changes in the appearance of facial features
and classifying this information into some facial-
expression-interpretative categories such as facial
muscle activations like smile or frown, emotion (af-
fect) categories like happiness or anger, attitude cate-
gories like (dis)liking or ambivalence, etc. (this step
is also referred to as facial expression interpretation).
Introduction
A widely accepted prediction is that computing
will move to the background, weaving itself into the
fabric of our everyday living and projecting the human
user into the foreground. To realize this goal, next-
generation computing (a.k.a . pervasive computing,
400
F
Facial Action Coding

ambient intelligence, and ▶ human computing) will
need to develop human-centered
▶ user interfaces
that respond readily to naturally occurring, multi-
modal, human communication [1]. These interfaces
will need the capacity to perceive and understand
intentions and emotions as communicated by social
and affective signals. Motivated by this v ision of the
future, automated analysis of nonverbal behavior, and
especially of facial behavior, has attracted increas-
ing attention in computer vision, pattern recogni-
tion, and human-computer interaction [2–5]. To wit,
facial expression is one of the most cogent, naturally
preeminent means for human beings to communi-
cate emotions, to clarify and stress what is said, to
signal comprehension, disagreement, and intentions,
in brief, to regulate interactions w ith the environment
and other persons in the vicinity [6, 7]. Automatic
analysis of facial expressions forms, therefore, the
essence of numerous next-generation-computing tools
including
▶ affective computing technologies (proac-
tive and affective user interfaces), learner-adaptive
tutoring systems, patient-profiled personal wellness
technologies, etc.
The Process of Automatic Facial
Expression Recognition
The problem of machine recognition of human facial
expression includes three subproblem areas (Fig. 1):
(1) finding faces in the scene, (2) extracting facial
features from the detected face region, (3) analyzing
the motion of facial features and/or the changes in the
appearance of facial features, and classifying this infor-
mation into some facial-expression-interpretative cate-
gories (e.g., emotions, facial muscle actions, etc.).
The problem of finding faces can be viewed as
a segmentation problem (in machine vision) or as a
detection problem (in pattern recognition). It refers to
identification of all regions in the scene that contain a
human face. The problem of finding faces (face localiza-
tion, face detection) should be solved regardless of clut-
ter, occlusions, and variations in head pose and lighting
conditions. The presence of non-rigid movements due
to facial expression and a high degree of variability
in facial size, color and texture make this problem
even more difficult. Numerous techniques have been
developed for face detection in still images [8, 9],
Facial Expression Recognition. Figure 1 Outline of an automated, geometric-features-based system for facial
expression recognition (for details of this system, see [4]).
Facial Expression Recognition
F
401
F
(see ▶ Face Localization). However, most of them can
detect only upright faces in frontal or near-frontal view.
Arguably the most commonly employed face detector
in automatic facial expression analysis is the real-time
face detector proposed by Viola and Jones [10].
The problem of feature extraction can be viewed as a
dimensionality reduction problem (in machine vision
and pattern recognition). It refers to transforming the
input data into a reduced representation set of features
which encode the relevant information from the input
data. The problem of facial feature extraction from
input images may be divided into at least three dimen-
sions [2, 4]: (1) Are the features holistic (spanning the
whole face) or analytic (spanning subparts of the face)?;
(2) Is temporal information used?; (3) Are the features
view- or volume based (2-D/3-D)?. Given this glossary,
most of the proposed approaches to facial expression
recognition are directed toward static, analytic, 2-D
facial feature extraction [3, 4]. The usually extracted
facial features are either geometric features such as the
shapes of the facial components (eyes, mouth, etc.) and
the locations of facial fiducial points (corners of the
eyes, mouth, etc.), or appea rance features representing
the texture of the facial skin in specific facial areas
including wrinkles, bulges, and furrows. Appearance-
based features include learned image filters from
Independent Component Analysis (ICA), Principal
Component Analysis (PCA), Local Feature Analysis
(LFA), Gabor filters, integral image filters (also known
as box-filters and Haar-like filters), features based on
edge-oriented histograms, etc, (see
▶ Skin Texture, and
▶ Feature Extraction). Several effor ts have also been
reported which use both geometric and appearance
features (e.g., [3]). These approaches to automatic
facial expression analysis are referred to as hybrid
methods. Although it has been reported that methods
based on geometric features are often outperformed by
those based on appearance features using, e.g., Gabor
wavelets or eigenfaces, recent studies show that in some
cases geometric features can outperform the appear-
ance-based ones [4, 11 ]. Yet, it seems that using both
geometric and appearance features might be the best
choice in the case of certai n facial expressions [11].
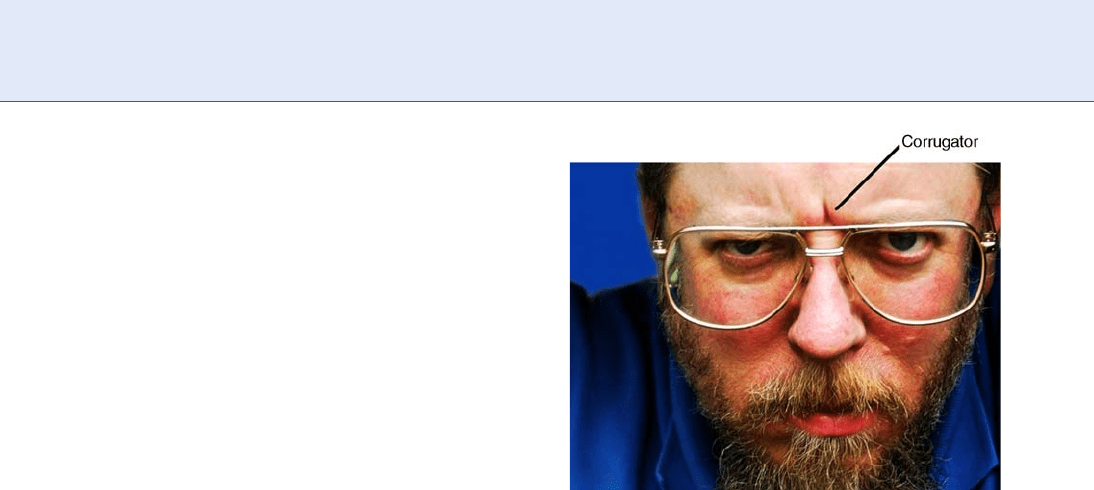
Contractions of facial muscles, which produce
facial expressions, induce movements of the facial
skin and changes in the location and/or appearance of
facial features (e.g., contraction of the Corrugator mus-
cle induces a frown and causes the eyebrows to move
towards each other, usually producing wrinkles between
the eyebrows; Fig. 2). Such changes can be detected
by analyzing optical flow, facial-point- or facial-
component-contour-tracking results, or by using an
ensemble of classifiers trained to make decisions
about the presence of certain changes (e.g., whether
the naso labial furrow is deepened or not) based on
the passed appearance features. The optical flow ap-
proach to describing face motion has the advantage of
not requiring a facial feature extraction stage of proces-
sing. Dense flow information is available throughout
the entire facial area, regardless of the existence of
facial components, even in the areas of smooth texture
such as the cheeks and the forehead. Because optical
flow is the visible result of movement and is expressed
in terms of velocity, it can be used to represent directly
the facial expressions. Many researchers adopted this
approach [2, 3]. Until recently, standard optical flow
techniques were, arguably, most commonly used for
tracking facial characteristic points and contours as
well [4]. In order to address the limitations inherent
in optical flow techniques such as the accumulation of
error and the sensitivity to noise, occlusion, clutter,
and changes in illumination, recent efforts in automatic
facial expression recognition use sequential state esti-
mation techniques (such as Kalman filter and Particle
filter) to track facial feature points in image sequences
(e.g., [4, 11]).
Eventually, dense flow information, tracked move-
ments of facial characteristic points, tracked changes
in contours of facial components, and/or extracted
Facial Expression Recognition. Figure 2 Facial
appearance of the Corrugator muscle contraction (coded
as in the FACS system, [14]).
402
F
Facial Expression Recognition

appearance features are translated into a description of
the displayed facial expression. This description (fac ial
expression interpretation) is usually given either in
terms of shown affective states (emotions) or in
terms of activated facial muscles underlying the dis-
played faci al expression. This stems directly from two
major approaches to facial expression measurement in
psychological research [12]: message and sign judg-
ment. The a im of message judgment is to infer what
underlies a displayed facial expression, such as affect
or personality, while the aim of sign judgment is to
describe the ‘‘surface’’ of the shown behavior, such as
facial movement or facial component shape. Thus, a
brow frown can be judged as ‘‘anger’’ in a message-
judgment and as a facial movement that lowers and
pulls the eyebrows closer together in a sign-judgment
approach. While message judgment is all about inter-
pretation, sign judgment attempts to be objective,
leaving inference about the conveyed message to higher
order decision making. Most commonly used facial
expression descriptors in message judgment app-
roaches are the six basic emotions (fear, sadness, hap-
piness, anger, disgust, surprise; see Fig. 3) proposed by
Ekman and discrete emotion theorists [13], who sug-
gest that these emotions are universally displayed and
recognized from facial expressions. Most commonly
used facial action descriptors in sign judgment appro-
aches are the Action Units (AUs) defined in the Facial
Action Coding System (FACS; [14]). Most facial expres-
sions analyzers developed, so far, target human facial
affect analysis and attempt to recognize a small set of
prototypic emotional facial expressions like happiness
and anger [2, 5]. However, several promising prototype
systems were reported that can recognize deliberately
produced AUs in face images and even few attempts
towards recognition of spontaneously displayed AUs
have been recently reported as well [3–5]. While the
older methods employ simple approaches including
expert rules and machine learning methods such as
neural networks to classify the relevant information
Facial Expression Recognition. Figure 3 Prototypic facial expressions of six basic emotions (left-to-right from top row):
disgust, happiness, sadness, anger, fear, and surprise.
Facial Expression Recognition
F
403
F

from the input data into some facial-expression-
interpretative categories, the more recent (and often
more advanced) methods employ probabilistic, statis-
tical, and ensemble learning techniques, which seem to
be particularly suitable for automatic facial expression
recognition from face image sequences [3, 5].
Evaluating Performance of an
Automated System for Facial Expression
Recognition
The two crucial aspects of evaluating performance of a
designed automatic facial expression recognizer are the
utilized training/test dataset and the adopted evalua-
tion strategy.
Having enough labeled data of the target human
facial behavior is a prerequisite in designing robust
automatic facial expression recognizers. Explorations
of this issue showed that, given accurate 3-D alignment
of the face (see
▶ Face Alignment), at least 50 training
examples are needed for moderate performance (in the
80% accuracy range) of a machine-learning approach
to recognition of a specific facial expression [4].
Recordings of spontaneous facial behavior are difficult
to collect because they are difficult to elicit, short lived,
and filled with subtle context-based changes. In addi-
tion, manual labeling of spontaneous facial behavior
for ground truth is very time consuming, error prone,
and expensive. Due to these difficulties, most of the
existing studies on automatic facial expression recogni-
tion are based on the ‘‘artificial’’ material of deliberately
displayed facial behavior, elicited by asking the subjects
to perform a series of facial expressions in front of a
camera. Most commonly used, publicly available,
annotated datasets of posed facial expressions incl ude
the Cohn-Kanade facial expression database, JAFFE
database, and MMI facial expression database [4, 15].
Yet, increasing evidence suggests that deliberate
(posed) behavior differs in appearance and timing
from that which occurs in daily life. For example,
posed smiles have larger amplitude, more brief dura-
tion, and faster onset and offset velocity than many
types of naturally occurring smiles. It is not surprising,
therefore, that approaches that have been trained on
deliberate and often exaggerated behaviors usually fail
to generalize to the complexity of expressive behavio r
found in real-world settings. To address the general lack
of a reference set of (audio and/or) visual recordings of
human spontaneous behavior, several efforts aimed at
development of such datasets have been recently
reported. Most commonly used, publicly available,
annotated datasets of spontaneous human behavior
recordings include SAL dataset, UT Dallas database,
and MMI-Part2 database [4, 5].
In pattern recognition and machine learning, a
common evaluation strategy is to consider correct
classification rate (classification accuracy) or its com-
plement error rate. However, this assumes that the
natural distribution (prior probabilities) of each class
are known and balanced. In an imb alanced setting,
where the prior probability of the positive class is
significantly less than the negative class (the ratio of
these being defined as the skew), accuracy is inade-
quate as a performance measure since it becomes
biased towards the majority class. That is, as the skew
increases, accuracy tends towards majority class per-
formance, effectively ignoring the recognition capabil-
ity with respect to the minority class. This is a very
common (if not the default) situation in facial expres-
sion recognition setting, where the prior probabilit y of
each target class (a certain facial expression) is signifi-
cantly less than the negative class (all other facial
expressions). Thus, when evaluating performance of
an automatic facial expression recognizer, other per-
formance measures such as precision (this indicates the
probability of correctly detecting a positive test sample
and it is independent of class priors), recall (this indi-
cates the fraction of the positives detected that are
actually correct and, as it combines results from both
positive and negative samples, it is class prior depen-
dent), F1-measure (this is calculated as 2*recall*preci-
sion/(recall + precision) ), and ROC (this is calculated as
P(x|positive)/P(x|negative), where P(x|C) denotes the
conditional probability that a data entry has the class
label C, and where a ROC curve plots the classification
results from the most positive to the most negative
classification) are more appropriate. However, as a
confusion matrix shows all of the information about
a classifier’s performance, it should be used whene ver
possible for presenting the performance of the evalu-
ated facial expression recognizer.
Applications
The potential benefits from efforts to automate the
analysis of facial expressions are varied and numerous
and span fields as diverse as cognitive sciences, medi-
cine, communication, education, and securit y [16].
404
F
Facial Expression Recognition

When it comes to computer science and computing
technologies, facial expressions provide a way to com-
municate basic informati on about needs and demands
to the machine. Where the user is looking (i.e., gaze
tracking) can be effectively used to free computer
users from the classic keyboard and mouse. Also,
certain facial signals (e.g., a wink) can be associated
with certain commands (e.g., a mouse click) offering
an alternative to traditional keyboard and mouse
commands. The human capabilit y to ‘‘hear’’ in noisy
environments by means of lip reading is the basis for
bimodal (audiovisual) speech processing (see Lip-
Movement Recognition), which can lead to the reali-
zation of robust speech-driven user interfaces. To make
a believable talking head (avatar) representing a real
person, recognizing the person’s facial signals and
making the avatar respond to those using synthesized
speech and facial expressions is important. Combin-
ing facial expression spotting with facial expression
interpretation in terms of labels like ‘‘did not under-
stand’’, ‘‘disagree’’, ‘‘inattentive’’, and ‘‘approves’’ could
be employed as a tool for monitoring human reactions
during videoconferences, web-based lectures, and
automated tutoring sessions. The focus of the relative-
ly, recently initiated research area of affective computing
lies on sensing, detecting and interpreting human af-
fective states (such as pleased, irritated, confused, etc.)
and devising appropriate means for handling this af-
fective information in order to enhance current
▶ HCI
designs. The tacit assumption is that in many situa-
tions human-machine interaction could be improved
by the introduction of machines that can adapt to their
users and how they feel. As facial expressions are our
direct, naturally preeminent means of communicating
emotions, machine analysis of facial expressions forms
an indispensable part of affective HCI designs.
Monitoring and interpreting facial expressions can
also provide important information to lawyers, police,
security, and intelligence agents regarding person’s
identity (research in psychology suggests that facial
expression recognition is much easier in familiar per-
sons because it seems that people display the same ,
‘‘typical’’ patterns of facial behaviour in the same situa-
tions), deception (relevant studies in psychology sug-
gest that visual features of facial expression function as
cues to deception), and attitude (research in psycholo-
gy indicates that social signals including accord and
mirroring – mimicry of facial expressions, postures,
etc., of one’s interaction partner – are typical, usually
unconscious gestures of wanting to get along with and
be liked by the interaction partner). Automated facial
reaction monitoring could form a valuable tool in
law enforcement, as now only informal interpretations
are typically used. Systems that can recognize friendly
faces or, more importantly, recognize unfriendly or
aggressive faces and inform the appropriate authorities
represent another application of facial measurement
technolog y.
Concluding Remark
Faces are tangible projector panels of the mechanisms
which govern our emotional and social behaviors.
The automation of the entire process of facial expres-
sion recognition is, therefore, a highly intriguing prob-
lem, the solution to which would be enorm ously
beneficial for fields as diverse as medicine, law, com-
munication, education, and computing. Although the
research in the field has seen a lot of progress in the
past few years, several issues remain unresolved. Argu-
ably the most important unattended aspect of the
problem is how the grammar of facial behavior can
be learned (in a human-centered, context-profiled
manner) and how this infor mation can be properly
represented and used to handle ambiguities in the
observation data. This aspect of machine analysis of
facial expressions forms the main focus of the current
and future research in the field.
Related Entries
▶ Face Alignment
▶ Face Localization
▶ Feature Extraction
▶ Lip Movement Recognition
▶ Skin Texture
References
1. Pantic, M., Pentland, A., Nijholt, A., Huang, T.S.: Human
computing and machine understanding of human behavior:
A Survey. Lect. Notes Artif. Intell. 4451, 47–71 (2007)
2. Pantic, M., Rothkrantz, L.J.M.: Toward an affect-sensitive multi-
modal HCI. Proceedings of the IEEE 91(9), 1370–1390 (2003)
3. Tian, Y.L., Kanade, T., Cohn, J.F.: Facial expression analysis.
In: Li, S.Z., Jain, A.K. (eds.) Handbook of Face Recognition,
pp. 247–276. Springer, New York (2005)
Facial Expression Recognition
F
405
F

4. Pantic, M., Bartlett, M.S.: Machine analysis of facial expressions.
In: Delac, K., Grgic, M. (eds.) 1Face Recognition, pp. 377–416.
I-Tech Education and Publishing, Vienna, Austria (2007)
5. Zeng, Z., Pantic, M., Roisman, G.I., Huang, T.S.: A survey of
affect recognition methods: Audio, visual, and spontaneous
expressions. IEEE Trans. Pattern Anal. Mach. Intell. 31(1),
39–58 (2009)
6. Ambady, N., Rosenthal, R.: Thin slices of expressive behavior
as predictors of interpersonal consequences: A meta-analysis.
Psychol. Bull. 111(2), 256–274 (1992)
7. Ekman, P., Rosenberg, E.L. (eds.): What the face reveals:
Basic and applied studies of spontaneous expression using
the facial action coding system. Oxford University Press,
Oxford, UK (2005)
8. Yang, M.H., Kriegman, D.J., Ahuja, N.: Detecting faces
in images: A survey. IEEE Trans. Pattern Anal. Mach. Intell.
24(1), 34–58 (2002)
9. Li, S.Z., Jain, A.K. (eds.): Handbook of face recognition.
Springer, New York (2005)
10. Viola, P., Jones, M.: Robust real-time face detection. Int. J.
Comput. Vis. 57(2), 137–154 (2004)
11. Pantic, M., Patras, I.: Dynamics of facial expression: Recognition
of facial actions and their temporal segments from face profile
image sequences. IEEE Trans. Syst. Man Cybern. B Cybern.
36(2), 433–449 (2006)
12. Cohn, J.F., Ekman, P.: Measuring facial actions. In: Harrigan,
J.A., Rosenthal, R., Scherer, K. (eds.) The New Handbook of
Methods in Nonverbal Behavior Research, pp. 9–64. Oxford
University Press, New York (2005)
13. Keltner, D., Ekman, P.: Facial expression of emotion. In:
Lewis, M., Haviland-Jones, J.M. (eds.) Handbook of Emotions,
pp. 236–249. Guilford Press, New York (2000)
14. Ekman, P., Friesen, W.V., Hager, J.C.: Facial action coding
system. A Human Face, Salt Lake City, USA (2002)
15. Pantic, M., Valstar, M.F, Rademaker, R., Maat, L. Web-based
database for facial expression analysis. Proc. IEEE Int’l Conf.
Multimedia & Expo (ICME) 317–321 (2005)
16. Ekman, P., Huang, T.S., Sejnowski, T.J., Hager, J.C. (eds.): NSF
Understanding the Face. A Human Face eStore, Salt Lake
City, USA, (see Librar y) (1992)
Facial Landmarks
A number of pixels in a face image clearly corresponds
to some extract physiological semantics, such as the eye
corners, eye centers, mouth corners, nose tips, etc.
These feature points are called facial landmarks. They
are generally used to align different face images for
accurate matching.
▶ Face Misalignment Problem
Facial Mapping
Facial mapping is a frequently used term to describe one-
to-one matching of crime scene and suspect images
undertaken by an expert. A number of different methods
may be used in combination to compare two images to
support the comparison. Also, a number of comparisons
may be made of the face from different angles if multiple
images are available from each source.
▶ Face, Forensic Evidence of
Facial Motion Estimation
▶ Face Tracking
Facial Photograph
▶ Photography for Face Image Data
Factor Analysis
▶ Session Effects on Speaker Modeling
Failure to Acquire Rate
Both the acquiring conditions and the flaw of biomet-
ric itself may cause failure to acquire a biometric trait.
The percentage of this failure is defined as ‘‘Failure to
Acquire Rate.’’ For instance, very low quality face
image may cause the failure of face detection and
subsequent feature extraction.
▶ Evaluation of Biometric Quality Measures
▶ Performance Evaluation, Overview
406
F
Facial Landmarks

Failure-to-Enrol Rate
Failure-to-enrol rate is defined as the proportion of
enrollment transactions in which zero instances were
enrolled. Enrollment in one or more instances is con-
sidered to be successful in the case, the systems accept
multiple biometric samples per person.
▶ Finger Vein Reader
Fake Finger Detection
▶ Anti-spoofing
▶ Fingerprint Fake Detection
False Match Rate
The probability that a biometric system will indicate
that two biometric templates match although they are
not derived from the same individual and should not
match.
▶ Fingerprint Image Quality
▶ Iris on the Move
False Negative Rate
False Negative Rate means that how many percentages
of the authentic test samples are incorrectly classified
as the imposter class. Take the example of the com-
puter account login system, False Negative Rate means
how many percentages of legal users are recognized as
illegal users. As one can see immediately, False Positive
Rate and False Negative Rate are two metrics that
counter each other. For any given biometrics modality
with given matching algorithm, requirement of low
False Positive Rate would unavoidably bring high
False Negative Rate, and vice versa. Performance
comparison between different algorithms is usually
done by comparing False Negative Rate at a fixed
False Positive Rate.
▶ Biometric System Design, Overview
▶ Iris Recognition, Overview
False Non-Match Rate
False non-match rate is the proportion of genuine
comparisons that result in false non-match. False
non-match is the decision of non-match when com-
paring biometric samples that are from same biometric
source (i.e., genuine comparison).
▶ Biometric System Design, Overview
▶ Fingerprint Image Quality
▶ Iris on the Move
False Positive Rate
False Positive Rate means how many percentage of the
imposter test samples are incorrectly classified as the
authentic class. For example, in a computer account
login system, False Positive Rate is what percentage of
the illegal users recognized as legal users. In applica-
tions, which require high security, False Positive Rate is
always required to be as small as possible.
▶ Biometric System Design, Overview
▶ Iris Recognition, Overview
Feathering
Feathering is a feature which occurs on the outsole as a
result of an abrasive wear and has some resemblance to
the ridge characteristics and bifurcations of fingerprint
patterns. It is the result of frictional abrasive forces
applied to the outsole surface such as when scuffing
Feathering
F
407
F

or dragging the shoe. This feature is a lso known as a
Schallamach patter n.
▶ Footwear Recognition
Feature Detection
Finding significant features in images such as land-
marks, edges, or curves. For example, a facial feature
detector aims to find the positions of the center of an
eye, the corners of a mouth, or the top of a nose in a
face image. In the case of an iris image, features may
mean the edges inside an iris or the boundaries around
the iris.
▶ Iris Segmentation Using Active Contours
Feature Extraction
▶ Biometric Algorithms
Feature Fusion
Producing a merged feature vector from a set of feature
vectors representing different aspects of biometric
data. The data can originate from different sensors,
and also from different properties of a signal that
originate from the same sensor.
▶ Fusion, Feature-Level
▶ Multiple Experts
Feature Map
The image produced from a target image to en-
hance the signals of a particular type, such as edges,
ridges, or valleys is referred as a ‘‘feature map.’’
Face alignment programs typically rely on statistics
computed from such features to distinguish facial
features from other regions of the image. More
sophisticated feature maps can be constructed
to capture complicated local image structures and
enhance the stability.
▶ Face Alignment
Feature Selection
Feature selection techniques are aimed towards finding
an optimal feature set for a specific purpose, such as
the optimization of a biometric system verification
performance. In general, feature selection algorithms
try to avoid the evaluation of all the possible feature
combinations when searching for an optimal feature
vector, since these grow exponentially as the number of
feature increases.
▶ Signature Features
Feature Vector
Feature vector is a multidimensional vector that is
obtained from a face by using feature extraction and
image processing techniques to be used and that is
used to memorize and recognize the face.
▶ Face Databases and Evaluation
Features
Biometric features are the information extracted from
biometric samples which can be used for comparison
with a biometric reference. For example, characteristic
measures extrac ted from a face photograph such as eye
distance or nose size etc. The aim of the extraction of
biometric features from a biometric sample is to
408
F
Feature Detection

remove superfluous information which does not con-
tribute to biometric recognition. This enables a fast
comparison and an improved biometric performance,
and may have privacy advantages.
▶ Biometric Algorithms
▶ Vascular Image Data Format, Standardization
Features vs. Templates
▶ Face Recognition, Geometric vs. Appearance-Based
Fidelity
The degree of similarity between a biometric sample
and its source. Fidelity of a sample is comprised of
individual components of fidelity attributed to each
step through which it is processed (e.g., compression).
▶ Biometric Sample Quality
▶ National Institute for Standards and Technology
Field of View (FOV)
Field of view (FOV) is the angular portion of visible
space which is comprised into the image region. The
FOV of the human eye is around 150
. The camera
FOV depends both on the size of the camera sensor
and the geometry of the lens. The camera focal length
determines the field of view falling within the sensor
area, thus determining also the magnification factor of
the image. A shorter camera focal length produces a
wider FOV, while a longer focal length produces a
smaller FOV.
▶ Face Device
Finger Data Interchange Format,
Standardization
RAUL SANCHEZ-REILLO
1
,ROBERT MUELLER
2
1
University Carlos III of Madrid, Avda. Universidad,
Leganes (Madrid), Spain
2
Giesecke & Devrient GmbH, Prinzregentenstr.
Muenchen, Germany
Synonyms
Encoded finger data; Fingerprint data interchange
format
Definition
Set of ISO Standards that define common formats to
encode information related to finger-based biometrics.
Those formats are defined to allow interoperability
among different vendors worldw ide, and have been
developed by the international community taking
part in ISO/IEC JTC1/SC37 standardization subcom-
mittee. Those documents define not only the way
a fingerprint image has to be encoded, but also the
way a feature vector composed of
▶ minutiae points
has to be stored and/or transmitted. Furthermore,
formats for the
▶ spectral data of the finger, as well
as its skeletal data are defined.
Introduction
Standardization is essential for the wide-spread adop-
tion of technologies in open mass applications. Finger-
print recognition is not only the most prominent
biometric measure, but also the biometric trait with
the largest databases and the best long-term experi-
ence. Fingerprints are used in applications such as
physical access control and digital signature creation
but also national ID card schemes and other govern-
mental projects. The need for standardization is con-
spicuous in every single area where it is not applied.
The SC37 Subcommittee from ISO/IEC JTC1 deals
with the standardization of biometrics. Among the
many aspects of its work, SC37’s Working Group 3 is
devoted to defining Interchange Data Formats for
a variety of biometric modalities. To accomplish this,
Finger Data Interchange Format, Standardization
F
409
F