Малхорта, Нэреш К. Маркетинговые исследования. Практическое руководство
Подождите немного. Документ загружается.


точные и своевременные отчеты, используемые в
процессе
наблюдения и контроля над работой
персонала на местах: отчеты о квотах, о распределении звонков (call disposition), о возникнове-
нии инцидентов, заключительные отчеты по данным о респондентах и отчеты об эффективно-
сти работы интервьюеров. Такая возможность автоматизации процесса отчетности повышает
действенность наблюдения и контроля и способствует повышению качества полученных дан-
ных в целом. Поскольку благодаря использованию компьютеров для составления сводных от-
четов требуется намного меньше времени, больше внимания можно уделить интерпретации
полученных данных и
непосредственно
наблюдению над процессом сбора информации.
Распределение звонков (call disposition)
В отчете о распределении звонков фиксируются результаты интервью, проведенных по
телефону.
В центре внимания Burke
Компания Burke делает все возможное, чтобы интервьюеры, работающие в рамках того
или иного проекта, имели необходимую подготовку и мотивы для хорошей работы, и чтобы
их работа должным образом контролировалась и оценивалась предельно точно. Все это по-
зволяет повысить эффективность и качество ее исследований. Как же компании удается
управлять этим сложным процессом?
Первый этап заключается в поиске хороших менеджеров. Для реализации программ по
подготовке менеджеров компания менеджеров нанимает самых лучших из своих интервьюе-
ров и людей с университетским образованием. Каждый
служащий
перед поступлением на
работу проходит
6—12-месячную
подготовку (в зависимости от опыта и уровня образова-
ния), затем проходит 24
двух-трехчасовые
тренировочные программы, после чего проводит-
ся тестирование полученных им знаний (его выполняет старший менеджер по сбору дан-
ных). Основное внимание уделяется стандартным процедурам сбора информации. Кроме
того, в рамках программы по подготовке менеджеров дополнительно изучаются
следующие
дисциплины, а именно:
• обслуживание клиентов;
• методы управления
выборорчным
наблюдением;
•
управление кадрами;
• управление взаимоотношениями (отношения между служащими, оценочные процеду-
ры, разрешение конфликтов и т.д.).
В компании Burke в департаменте по сбору информации постоянно работают специали-
сты по кадровым вопросам, в обязанности которых входит найм и подготовка как менедже-
ров, так и штата для работы на местах. Компания старается нанимать сотрудников из трех
основных групп населения: студентов колледжей; лиц, желающих иметь дополнительный
заработок; интервьюеров, нацеленных на карьеру в этой деятельности. Для привлечения та-
ких людей Burke использует разнообразные способы:
• реклама (в газетах и по радио);
• ярмарки вакансий, специализированные выставки, дни открытых дверей;
« подробные внутренние справочные программы;
• работа в студенческих общежитиях;
• использование временного штата.
В компании Burke разработаны и применяются четко определенные процедуры отбора и
подготовки работников по сбору данных на местах, На одном из этапов первичного про-
смотра претенденту предлагается простой тест на проверку грамотности и умения считать.
К сожалению, высокий процент кандидатов не в состоянии пройти этот тест или делают это
514 Часть III.
Сбор,
подготовка и анализ данных

с большим
трудом.
В подготовительном процессе компании уделяется большое внимание
!
улучшению этих навыков. На начальной стадии занятий кандидатам предлагается принять
j
участие в работе дискуссионной группы, и в ходе их общения за ними ведется наблюдение,
|
оценивается их способность слушать других и логически и точно реагировать на услышан-
ное. После прохождения этих проверок принимается окончательное решение, которое осно-
вывается на следующем:
• практические занятия по набору телефонных номеров под
тщательным
наблюдением
контролера;
• прослушивание и
оценка
контролерами;
• тренинги и обсуждение успешных интервью в группе;
• способность читать и вызывать собеседника на диалог;
• явный профессионализм;
• навыки при выполнении стандартных процедур и основных рекомендаций.
Интервьюеры проходят курсы по следующим направлениям:
• как вести себя в случае отказа респондента отвечать на вопрос и как правильно прекра-
щать интервью;
• эффективность процесса опроса;
• речевой курс (правильное
произношение
и т.д.);
• машинопись;
• тренинг по работе с клиентом (проведение опроса в качестве представителя конкретной
организации).
Для обеспечения целостности процесса сбора данных в каждом проекте Burke постоянно
отслеживает качество и последовательность работы интервьюеров:
• ежедневное прослушивание и оценка каждого интервьюера по каждому проекту;
• стандартизация отчетности с использованием компьютерных систем управления;
• продолжительность интервью каждого интервьюера;
коэффициент прерывания интервью на одного интервьюера;
распределение звонков на одного интервьюера;
время работы в электронной компьютерной
сети,
подробный отчет с продолжением;
участие руководителей высшего звена в программах открытого мониторинга, в рамках
которых менеджеры произвольно выбирают интервьюера и слушают, как он работает.
РЕЗЮМЕ
В распоряжении маркетологов имеется две основные возможности для сбора данных — они
могут создать свой собственный коллектив либо заключить контракт с агентством, специали-
зирующимся
на полевых работах. Полевой персонал должен состоять из здоровых, инициатив-
ных, коммуникабельных, приятных, образованных и опытных людей. Они должны пройти
подготовку по важнейшим аспектам полевых работ, включая то, как следует налаживать перво-
начальный контакт, как задавать вопросы, как стимулировать исчерпывающие ответы, как за-
писывать ответы и заканчивать интервью. Наблюдение над работой полевого персонала заклю-
чается в контроле качества и редактирования данных, в выборочном контроле, контроле для
выявления случаев мошенничества и контроле из центрального офиса. Проверка результатов
полевых работ выполняется повторным обзваниванием
10—25%
респондентов, указанных ин-
тервьюером, и выяснения, действительно ли их опрашивали. Работа полевого персонала оце-
Глава
13.
Полевые работы
515

нивается
на основе их денежных и временных затрат, показателей доли ответивших от общего
количества намеченных респондентов, качества опроса и качества собранных данных.
Поскольку во многих странах нет местных агентств, специализирующихся на сборе данных,
если речь идет о международных маркетинговых исследованиях, отбор, подготовка, наблюде-
ние за работой персонала по сбору информации и его оценка приобретает даже большее значе-
ние. Морально-этический аспект работы по сбору данных на местах заключается в том, что
оп-
рос должен вестись в дружественной и непринужденной манере, что позволит сформировать у
респондента позитивное отношение к таким
опросам.
Необходимо сделать все возможное, что-
бы полученные данные были высокого качества. Качество работы на местах значительно
по-
вышается благодаря Internet и компьютерной технике.
ОСНОВНЫЕ ТЕРМИНЫ И ПОНЯТИЯ
• выборочный контроль (sampling control) • распределение
звонков
(call disposition)
•
стимулирование
ответов (probing)
УПРАЖНЕНИЯ
Вопросы
1. Какие возможности для сбора информации есть в распоряжении маркетолога?
2. Опишите процесс полевых работ.
3. Какой квалификацией должен обладать полевой персонал?
4. Каковы основные рекомендации относительно процедуры предложения вопросов?
5. В чем заключается стимулирование полных ответов?
6.
Как записывать ответы на неструктурированные вопросы?
7. Как интервьюер должен
прекращать
интервью?
8. Каковы аспекты наблюдения за работой полевого персонала?
9. Как управлять проблемами отбора респондентов?
10. В чем заключается проверка результатов полевых работ? Как она проводится?
11. Опишите критерии, используемые при оценке работы персонала по сбору информации.
12. Опишите основные источники ошибок в ходе полевых работ.
Задачи
1. Составьте несколько
инструкций
для студентов для проведения личного опроса на дому.
2. Прокомментируйте следующие ситуации, которые могут возникнуть в процессе полевой
работы, и предложите методы их решения.
a)
Один из интервьюеров имеет очень большой показатель отказов респондентов отвечать
при личном опросе на дому.
b)
При опросе с использованием автоматизированных компьютерных систем при первой
попытке набора многие номера
океазываются
занятыми.
c)
Один из интервьюеров сообщил, что в конце интервью многие респонденты спрашива-
ют его, правильно ли они ответили на вопросы.
d) В ходе проверки результатов опроса одна из
респонденток
сообщила,
что не может
вспомнить, чтобы ей кто-либо звонил с просьбой ответить на вопросы, а интервьюер
настаивает на том, что он проводил опрос.
516 Часть III.
Сбор,
подготовка и анализ данных

УПРАЖНЕНИЯ С ИСПОЛЬЗОВАНИЕМ INTERNET
И КОМПЬЮТЕРА
1. Посетите Web-сайты каких-либо компаний, специализирующихся на маркетинговых ис-
следованиях. Составьте отчет по всем материалам, связанным с полевыми работами, разме-
шенными на этих сайтах.
2.
Посетите
Web-сайт
Marketing Research Association
(www.
mra-net.
org)
и
внимательно
озна-
комьтесь с разделами этического кодекса, относящимися к процессу сбора данных. Со-
ставьте краткий отчет.
3. Воспользуйтесь специальным программным обеспечением PERT/CPM, например
MacProject,
Timeline, Harvard Project Manager, Microsoft Project или Category
PertMaster,
и
разработайте график полевых работ для проведения
обще
национального
опроса о предпоч-
тениях потребителей по поводу продуктов быстрого приготовления на основе 2500 интер-
вью в Лос-Анджелесе,
Солт-Лэйк-Сити,
Далласе,
Сант-Луисе,
Милуоки, Нью-Орлеане,
Цинциннати, Орландо, Атланте, Нью-Йорке и Бостоне.
КОММЕНТАРИИ
1. Reg Baker, "Nobody's Talking", Marketing Research A Magazine of Management &
Applications,
Spring 1996, p.
11-A;
"Study Tracks Trends in Refusal Rates", Quirk's
Marketing
Research
Review,
August-September 1989, p. 16-18, 42-43.
2. Gale D.
Muller,
Jane Miller, "Interviewers Make the Difference", Marketing Research A Magazine of
Management &
Application,
Spring 1996, p.
8—9;
"JDC
Interviews Michael
Redington",
Journal of
Data
Collection,
Spring 1985, p. 2-6.
3. James H. Frey, Sabine M. Oishi, How to Conduct Interviews by
Telephone
and In Person (Thousand
Oaks, CA: Sage Publications, 1995).
4. Gale D. Muller, Jane Miller, "Interviewers Make the Difference", Marketing Research A Magazine of
Management & Applications, Spring 1996, p.
8—9;
Jean Morton-Williams, Interviewer Approaches
(Brookfield:
Ashgate Publishing Co, 1993).
5.
Joseph
A. Catina, Diane
Bemson,
Jesse Canchola, Lance M. Pollack et
al,
"Effects of Interviewer
Gender, Interviewer Choice, and Item Wording on Responses to Questions Concerning Sexual Be-
havior", Public Opinion
Quarterly.,
Fall 1996, p.
345—375;
Philip
B. Coulter, "Race of Interviewer
Effects on Telephone Interviews",
Public
Opinion Quarterly, Summer 1982, p.
278—284;
Eleanor
Singer, Martin R. Frankel, Marc B.
Classman,
"The
Effect
of Interviewer Characteristics and Ex-
pectations on
Response",
Public
Opinion
Quarterly,
Spring 1983, p.
68—83.
6. Darren W. Davis,
"Nonrandom
Measurement Error and Race of Interviewer Effects among African
Americans", Public Opinion
Quarterly,
Spring 1997, p.
183—207;
Raymond F. Barker, "A Demo-
graphic Profile of Marketing Research Interviewers", Journal of the Market Research
Society
(UK),
July
29, 1987, p. 279-292.
7.
M.K.
Kacmar,
W.A.
Hochwarter,
"The Interview as a Communication Event A Field Examination
of Demographic Effects on Interview Outcomes", Journal of Business Communication, July 1995,
p.
207—232;
Martin Collins, Bob Butcher, "Interviewer and Clustering Effects in an Attitude Sur-
vey", Journal of the Market Research Society (UK), January 1983, p.
39—58.
8. James H.
Frey.
Sabine M. Oishi, How to Conduct Interviews by Telephone and in
Perwn
(Thousand
Oaks, CA: Sage Publications. 1995); Bud Phillips, "The Four
Faces
of Interviewers",
Journal
of
Data
Collection,
Winter
1983,
p.
35-40.
9. Pamela
Kiecker,
James E. Nelson, "Do Interviewers Follow Telephone Survey Instructions",
Journal
of the Market Research
Society^
April 1996, p,
161—176;
P.J. Guenzel, T.R.
Berkmans,
C.F.
Cannell,
General
Interviewing
Techniques (Ann Arbor, MI: Institute for Social
Research,
1983).
Глава 13. Полевые работы 517

10. Mick P Couper, "Survey Introductions and Data Quality", Public Opinion Quarterly, Summer 1997,
p. 317-338.
11. Эта
методика
соответствует
той,
которую использует Burke Marketing Research, Cincinnati.
12. "Market Research Industry Sets Up Interviewing Quality Standards", Management
Auckland,
March
1997, p. 12;
"JDC
Interviews Michael
Redington",
Journal of Data Collection, Spring
1985,
p.
2—6.
13.
Данный раздел тесно связан с Interviewer's
Manual,
rev. ed. (Ann Arbor, MI: Survey Research
Center,
institute
for Social Research, University of Michigan);
PJ.
Guenzel, T.R. Berkmans, C.F.
Cannell,
General
Interviewing Techniques (Ann Arbor, MI: Institute for Social Research).
14. См. работы Interviewer's Manual, p. 15—19; Michelle
Marchetti,
"Probing Customer Problems",
Sales & Marketing Management, March 1996, p. 46.
15. Interviewer's
Manual,
rev.
ed. (Ann Arbor, MI: Survey Research Center, Institute for Social
Research,
University of Michigan), p 16. Перепечатывается с разрешения Institute for Social
Research.
16. "Market Research Industry Sets Up Interviewing Quality Standards",
Management-Auckland,
March 1997, p. 12; Jean Morton
Williams,
Wendy Sykes, "The Use of Interaction Coding and Fol-
low up Interviews to Investigate Comprehension of Survey
Questions",
Journal of the Market
Research Society, April
1984,
p. 109-127,
17.
Robert F. Hurley, Jukka M.
Laitamaki,
"Total Quality Research Integrating Markets and the Or-
ganization", Call forma Management Review, Fall 1995, p.
59—78;
Martin Collins, Bob Butcher,
"Interviewer and Clustering Effects in an Attitude Survey", Journal of the Market Research Society
(UK), January 1983, p. 39-58.
18. Samuel
Greengard,
"50% of Your Employees Are Lying, Cheating & Stealing", Workforce, October
1997, p.
44—53;
Donald S.
Tull,
Larry E, Richards, "What Can Be Done about
Interviewer
Bias", in
Jagdish Sheth
(ed.),
Research in Marketing (Greenwich, CT:
JAI
Press,
1980),
p. 143-162.
19.
Elame
D. Pulakos,
Neal
Schmitt,
David Whitney, Matthew Smith, "Individual Differences in Inter-
viewer Ratings. The Impact of Standardization. Consensus Discussion, and Sampling Error on the
Validity
of
a Structured Interview", Personnel Psychology, Spring 1996, p.
85—102.
20. Jack Edmonston, "Why Response Rates Are Declining", Advertising Age's Business Marketing, Sep-
tember
1997,
p.12,
21. Thomas T. Semon,
"Select
Local Talent When Conducting Research Abroad", Marketing News,
September 15, 1997, p. 28, Laurel Wentz, "Poll Europe Favors U.S. Products", Advertising Age,
September 23, 1991).
22. James E. Nelson, Pamela L.
Kiecker,
''Marketing
Research Interviewers and Their Perceived Ne-
cessity
of
Moral Compromise",
Journal
of Business Ethics, October 1996, p.
1107—1117.
23. Glen J. Nowak, Joseph Phelps, "Direct Marketing and the Use of Individual-Level Consumer In-
formation Determining How and When Privacy Matters", Journal of Direct
Marketing,
Autumn
1997,
p.
94-108.
518
Часть III.
Сбор,
подготовка и
анализ
данных

Глава
14
Подготовка данных к анализу
После изучения материала этой главы вы должны уметь ...
1. Описать суть и этапы подготовки к анализу данных, собранных в результате
маркетингово-
го исследования.
2. Объяснить, как ведется проверка и редактирование анкет, и описать суть работы с неудов-
летворительными ответами с помощью повторных полевых работ, присвоения пропущен-
ных значений и отсеивания неудовлетворительных ответов.
3. Перечислить основные рекомендации относительно кодирования анкет, содержащих
структурированные и неструктурированные ответы.
4. Обсудить процесс "очищения" данных и методы, используемые для работы с пропущен-
ными ответами: замена их нейтральными значениями, использование вмененных ответов,
исключение наблюдения
целиком
и попарное исключение переменных.
5. Дать определение причин и описать методы статистической корректировки данных: умно-
жение на весовой коэффициент, переопределение переменной и преобразование шкалы.
6. Описать процедуру выбора стратегии анализа данных и назвать факторы, влияющие на это
решение.
7. Описать классификацию основных статистических методов, уметь подробно классифици-
ровать одномерные и многомерные методы статистического анализа.
8. Понимать суть внутри
культурного,
пан
культурного
и межкультурного подходов к анализу
данных в процессе выполнения международных маркетинговых исследований.
9. Дать определение этическим проблемам, связанным с обработкой данных, особенно с про-
цессом отбраковки неудовлетворительных ответов, нарушением предположений, лежащих
в основе различных методов анализа данных, оценкой и интерпретацией результатов иссле-
дования.
10. Описать использование Internet и компьютеров при подготовке данных к анализу и в ходе
самого анализа.
КРАТКИЙ ОБЗОР
Определив проблему маркетингового исследования и разработав наиболее подходящий под-
ход к ее решению (глава 2), нужно составить соответствующий план проведения исследования
(главы
3—12).
Затем следует этап, на котором проводится сбор данных (полевые работы) (глава 13),
завершив который, исследователь может перейти к подготовке данных и их анализу. Эта деятель-
ность
составляет
пятый этап маркетинговых исследований. Перед тем как передать исходные
данные, содержащиеся в анкетах, для статистического анализа, их необходимо преобразовать в
подходящую для анализа форму. Качество статистических результатов напрямую зависит от
того,
насколько тщательно и аккуратно данные готовились к анализу. Недостаточное внимание к этой
деятельности может серьезно исказить статистические выводы, что, в свою очередь, ведет к непра-
вильной интерпретации данных всего маркетингового исследования.
В этой главе описывается процесс сбора данных, который начинается с проверки полноты
заполнения анкет. Затем мы обсудим вопросы редактирования данных и дадим общие реко-
мендации относительно того, как работать с нечитабельными, неполными, непоследователь-
ными, неоднозначными и прочими ответами неудовлетворительного качества. Мы также
Глава 14. Подготовка данных к анализу 519

опишем
процедуры кодирования, преобразования и "очистки" данных и при этом уделим осо-
бое внимание работе с
пропущенными
ответами и вопросам статистической корректировки
данных. В этой главе также обсуждаются проблемы выбора
стратегии
анализа собранных дан-
ных и рассказывается о классификации статистических методов. Кроме того, вы найдете опи-
сание различных принципов подхода к анализу данных, применяемых в процессе междуна-
родных маркетинговых
исследований:
внутри
культурные,
панкультурные
и межкультурные
подходы. Здесь также описываются этические вопросы, связанные с обработкой данных, и осо-
бое внимание уделяется отбраковке (отсеиванию из анализа) неудовлетворительных ответов,
проблемам нарушения предположений, лежащих в основе
выбранного
метода анализа, а также
оценке и интерпретации полученных результатов. И наконец, в этой главе обсуждается роль
Internet и компьютеров в процессе подготовки и анализа собранных данных.
Начнем с ряда примеров, связанных с подготовкой данных.
ПРИМЕР. Обычное "очищение" данных
По данным корпорации
Joann
Harristhal
of Custom Research, Inc., заполненные анкеты, по-
ступившие с мест сбора данных, зачастую содержат множество мелких ошибок, и происхо-
дит это вследствие
неодинакового
качества проведения опросов. Например, нередко ответы
не обводятся кружком либо не совсем точно выдерживаются шаблоны пропусков.
Такие, казалось бы, безобидные ошибки обходятся очень дорого. Учитывая это, при вво-
де ответов из анкет в память компьютера специалисты
Custom
Research запускают специаль-
ную "чистящую" программу для проверки полноты и правильности их заполнения. Расхо-
ждения обычно выявляются в распечатках в процессе их проверки контролером, в обязанно-
сти которого входит составление сводных таблиц. При обнаружении ошибки проводятся
определенные
корректирующие
мероприятия, и только после этого данные направляются на
анализ. По мнению специалистов из Custom Research, такая процедура значительно повыша-
ет качество результатов статистического анализа [1].
СКВОЗНОЙ
ПРИМЕР.
ВЫБОР УНИВЕРМАГА
Подготовка данных к анализу
В ходе
реачизации
проекта "Выбор универмага" информация собиралась в ходе личных ин-
тервью с респондентами на дому. Анкеты после их сдачи интервьюерами редактировались
бригадирами, тщательно проверялись на наличие неполных и логически непоследователь-
ных ответов или лишней
информации.
Анкеты с неудовлетворительными ответами возвра-
щались
на места сбора данных (в "поле"), и интервьюеры
еще
раз встречались с указанными
респондентами, чтобы получить всю
необходимую
информацию. В результате девять анкет
все же были отсеяны из анализа, поскольку доля ответов неудовлетворительного качества в
них была очень велика. В итоге размер финальной выборки составил
271
анкету.
Для кодирования анкет была разработана кодовая книга. Кодирование довольно простое,
поскольку в анкете не было открытых вопросов, Затем данные вводились в память компью-
тера,
после чего около 25% введенного объема информации проверялось на наличие ошибок
ввода с клавиатуры. Данные были "подчищены" путем выявления и отсеивания ответов,
выпадающих из определенного диапазона, и логически непоследовательных ответов. По-
давляющая
часть рейтинговой информации собиралась с использованием шестибалльной
шкалы, поэтому ответы 0, 7 и 8 считались
выходящими
за пределы диапазона, а код 9 при-
сваивался
пропущенным
ответам.
Все
пропущенные
ответы отсеивались по методу исключения объекта целиком, в соотвстст- |
вии с которым анкеты, в которых было
пропущено
хотя бы одно значение, в анализ не I
включались. Такой способ исключения выбран потому, что количество наблюдений с про-
\
пущенными переменными было незначительным, а размер выборки достаточно велик. I
I
В процессе статистической корректировки данных вместо категориальных
переменных
бы-
|
ли подставлены заменители. Кроме того, новые переменные выводились на основе исход- |
520 Часть
lit.
Сбор, подготовка и анализ данных
ных.
Так, в результате суммирования рейтинговых оценок степени ознакомления респон-
дентов с десятью универмагами был вычислен
коэффициент
степени ознакомления и раз-
[
работана стратегия анализа данных.
Описанный выше пример отражает разные стадии процесса подготовки данных к анализу.
Обратите внимание на то, что этот процесс начинается, когда работа по сбору данных на местах
еще продолжается. Приведенный выше пример, описывающий опыт компании
Custom
Research,
свидетельствует об огромной важности процедуры "очищения" данных, выявления ошибок и
корректировочных мероприятий перед тем, как приступить к анализу собранных данных.
Подготовка
предварительного
плана
проведения
анализа данных.
Проверка анкет
Редактирование
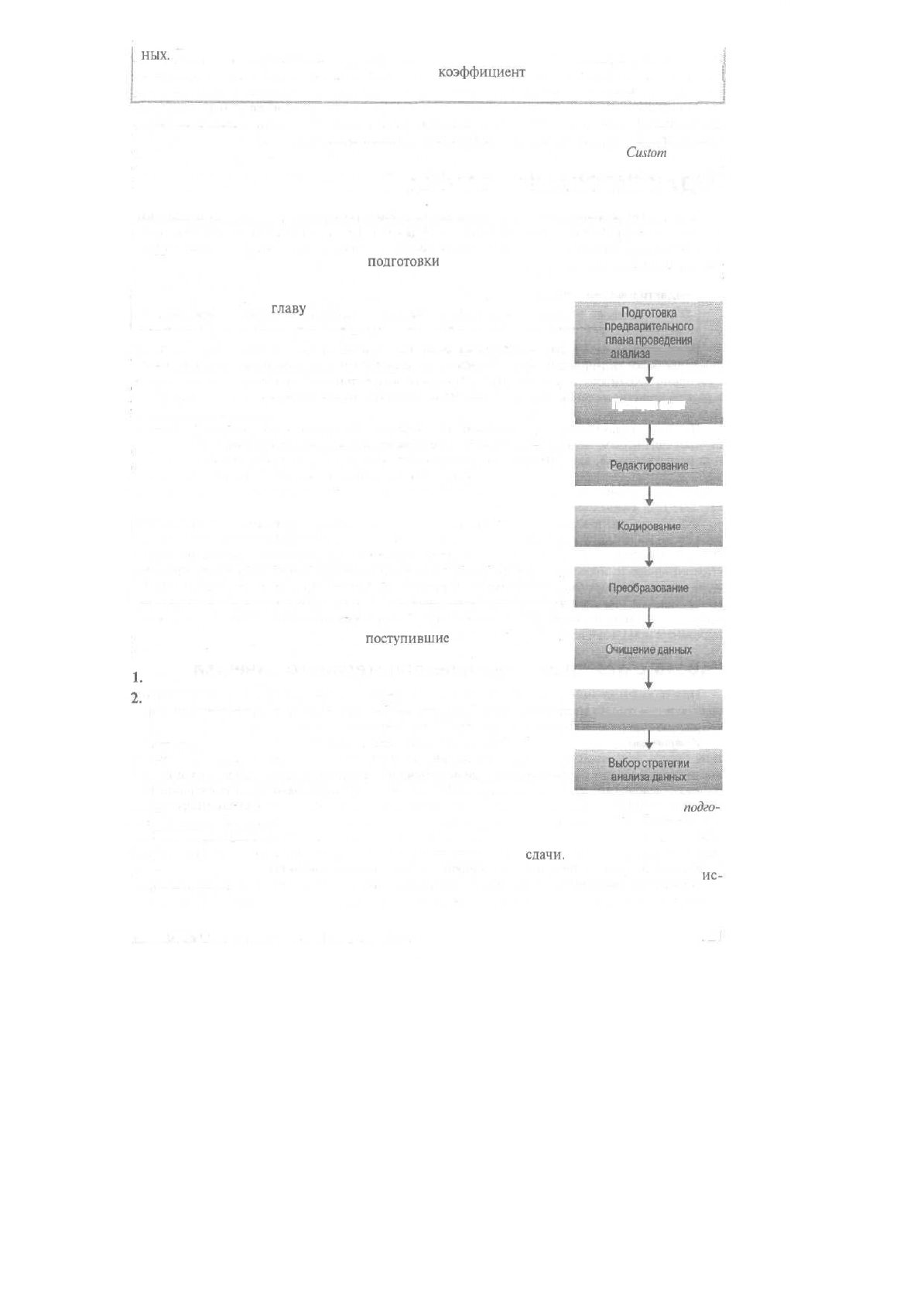
ПРОЦЕСС ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ
Наглядное отображение процесса
подготовки
данных к анализу представлено на рис. 14.1.
Весь этот процесс определяется предварительно подготовленным планом анализа данных, ко-
торый составляется еще в ходе разработки всего плана маркетингово-
го исследования (см.
главу
3). Первым его этапом выступает про-
верка пригодности анкет, Затем наступает черед редактирования,
кодирования и переноса данных. Данные очищаются и при необ-
ходимости проводится работа с пропущенными данными, Часто
необходимо также провести статистическую корректировку ин-
формации для того, что бы сделать ее репрезентативной для гене-
ральной совокупности. Затем исследователю необходимо выбрать
подходящую стратегию анализа данных.
Подготовка данных должна начинаться сразу же после того, как
станут доступными первые анкеты, в то время как полевые работы
еще продолжаются. Поэтому, если возникнут проблемы, ход полевых
работ можно скорректировать в нужном направлении.
ПРОВЕРКА АНКЕТ
Первый этап проверки анкет заключается в их проверке на пол-
ноту заполнения и качество интервьюирования. Зачастую этот про-
цесс ведется параллельно с полевыми работами. Следует отметить,
что если эта процедура выполняется по контракту специализирован-
ным агентством, исследователь обязан провести независимую про-
верку после ее завершения. Анкеты,
поступившие
с мест сбора дан-
ных, могут быть не приняты по следующим причинам.
1.
Не заполнены отдельные части анкеты.
2.
Представленные ответы свидетельствует о том, что респондент не
понял вопросов либо не точно следовал инструкциям по запол-
нению анкеты. Например, не был соблюден шаблон пропусков
ответов.
3. Ответы варьируются очень незначительно или не варьируются
вовсе, например, респондент пометил одни четверки в серии се-
мибалльных рейтинговых шкал.
4. Возвращенная анкета является неполной — отсутствует одна или
несколько страниц.
5. Анкета получена по истечении заранее определенного срока
сдачи.
6. Ответы в анкете даны респондентом, не входящим в группу, выделенную для участия в
ис
следовании.
Статистическая
корректировка данных
Рис. 14. ]. Процесс
подго-
товки данных к анализу
Глава 14. Подготовка данных к анализу
521

Если были определены конкретные квоты респондентов либо назначены размеры ячеечных
групп, все принятые анкеты необходимо соответствующим образом классифицировать и подсчи-
тать. Любые проблемы, связанные с выполнением требований, предъявляемых к выборкам,
должны выявляться своевременно, и необходимые корректировочные мероприятия, например,
дополнительные интервью в ячейках, представленных по результатам опроса недостаточно полно,
следует провести перед тем, как приступать к редактированию данных.
РЕДАКТИРОВАНИЕ ДАННЫХ
Процесс редактирования (editing) заключается в обработке собранных анкет для повышения
точности и аккуратности представленных в них данных. Он заключается в просмотре анкет, в
ходе которого выявляются нечитабельные, неполные, логически непоследовательные или не-
однозначные ответы.
Редактирование (editing)
Обработка
анкет,
повышающая точность и аккуратность представленной в них информации.
Если ответы неаккуратно и небрежно записаны, они могут быть неразборчивыми. Такая
ситуация более типична для анкет, содержащих много неструктурированных вопросов. Чтобы
правильно закодировать данные, они должны быть читабельными. Кроме того, анкеты бывают
в разной степени не до
конца
заполнены. Они могут содержать несколько или множество во-
просов без ответов.
На этапе редактирования исследователь проводит предварительную проверку анкет на
предмет логической непоследовательности представленных в них ответов.
Существует
ряд яв-
ных несоответствий, выявить которые не составляет большого труда. Так, возможна ситуация,
когда респондент сообщает, что его годовой доход составляет не больше 20 тысяч долларов, но
при этом указывает, что является постоянным покупателем таких престижных универмагов,
как Saks Fifth Avenue или
Neiman-Marcus.
Ответы на неструктурированные вопросы могут быть неоднозначными, в результате их
сложно точно интерпретировать. Бывает, что ответ респондента записан сокращенно либо при
его записи использованы слова, имеющие несколько смысловых значений. Даже если вопросы
структурированы, нередки ситуации, когда респондент помечает больше одного варианта отве-
та на вопрос, по которому необходимо дать однозначный ответ. Предположим, респондент по-
мечает пункты 2 и 3 по пятизначной рейтинговой шкале. Как следует
расценивать
такой ответ:
что он имел в виду значение 2,5? В таком случае дело осложняется еще тем, что в процедуре ко-
дирования используются только целые числа.
Работа с ответами неудовлетворительного качества
При получении анкет, содержащих ответы неудовлетворительного качества, их обычно от-
правляют обратно на места сбора данных для уточнения, либо назначаются
пропущенные
зна-
чения, либо такие анкеты отбраковываются и не включаются в анализ.
Возврат анкет на место сбора данных. Анкеты, содержащие неудовлетворительные резуль-
таты опроса, возвращаются на места сбора данных, и интервьюеров обязуют провести повтор-
ное интервью. Такой вариант обычно применяется при проведении промышленных маркетин-
говых исследований, для которых характерны выборки небольших размеров и идентифициро-
вать
респондентов,
предоставивших ответы низкого качества, не составляет большого труда.
Однако данные, полученные в результате вторичного опроса, могут сильно отличаться от пер-
воначальных. Эта разница
обуславливается,
например, тем, что между опросами прошло опре-
деленное время, а также тем, что опросы проводились с использованием разных режимов
(например, первый раз по телефону, а второй — в ходе личного контакта).
Назначение пропущенных значений. Если
возвращение
анкеты на место сбора данных при-
знано экономически нецелесообразным, редактор может самостоятельно присвоить
неудовле-
522 Часть III. Сбор, подготовка и анализ данных

творительным откликам
пропущенные
значения. Рекомендуется применять
этот
метод в сле-
дующих случаях: если количество респондентов, ответы которых признаны неудовлетвори-
тельными, невелико; доля ответов неудовлетворительного качества
в
ответах каждого респон-
дента незначительна; переменные по неудовлетворительным ответам не основные.
Отсеивание анкет респондентов, содержащих ответы неудовлетворительного качества.
При этом методе респонденты, предоставившие ответы неудовлетворительного качества, про-
сто отбраковываются и их анкеты не включаются в анализ. Данный способ эффективен в сле-
дующих случаях: если доля "неудовлетворительных" респондентов невелика (меньше 10%); ес-
ли размер выборки велик; если "неудовлетворительные" респонденты явно не отличаются от
"удовлетворительных" (например, по демографическому признаку или основным характери-
стикам использования товара); если доля неудовлетворительных откликов на каждого респон-
дента велика; если пропущены ответы по основным переменным. Однако бывают
ситуации,
когда "неудовлетворительные" респонденты отличаются от "удовлетворительных" либо реше-
ние признать респондента "неудовлетворительным" предельно субъективно. В этих случаях
использование данного метода повлечет за собой искажение данных. Если исследователь при-
нимает решение отбраковать неудовлетворительные ответы того или иного респондента, он
должен отчитаться, на основе какой именно процедуры он идентифицировал данного респон-
дента. Это подтверждается следующим примером.
ПРИМЕР. Отсеивание респондента из анализа
В процессе межкультурного исследования поведения менеджеров по маркетингу в ряде
англоязычных африканских стран разослали анкеты в 565 фирм. Возвращено было 192 за-
полненные анкеты, из которых четыре сразу отбраковали, поскольку респонденты ответили,
что они не несут непосредственной ответственности за принятие решений общего характера
в маркетинге. Решение об отсеивании этих четырех анкет приняли на том основании, что
размер выборки был достаточно велик, а доля "неудовлетворительных" респондентов незна-
чительна [2].
КОДИРОВАНИЕ
Процедура кодирования (coding) заключается в присваивании кода, обычно цифрового, ка-
ждому возможному варианту ответа по каждому вопросу.
Кодирование (coding)
Процедура присвоения кода
конкретному
ответу на конкретный вопрос. Информация, полу-
ченная
в
результате исследования и образующая код, распределяется по столбцам.
Код включает указание на положение столбцов (полей) и информации, которая в них со-
держится. Так, пол респондентов может кодироваться
следующим
образом: 1
—
для женщин и
2—
для мужчин. Поле отображает единичный элемент данных, например пол респондента.
Запись состоит из ряда
соответствующих
полей: пол, семейное положение, возраст, состав се-
мьи, занятие респондента и т.д. Все демографические и личностные характеристики респон-
дента, как правило, содержатся в одной регистрационной записи. Обычно каждая запись со-
стоит из 80 столбцов, хотя это и не обязательное условие. На одного респондента можно завести
несколько записей.
Данные (т.е. все записи) по всем респондентам хранятся в компьютерном файле, пример
которого вы видите в табл. 14.1. Столбцы представляют собой поля, а строки — записи.
В табл. 14.1 представлены фрагменты закодированных данных по респондентам, опрошенным
в ходе реализации уже привычного нам проекта "Выбор универмага".
Все данные соответствуют схеме кодирования, изображенной на рис. 14.2.
Глава
14. Подготовка данных к анализу 523