Барыкин С.Г., Плотникова Н.В. Системы искусственного интеллекта
Подождите немного. Документ загружается.


71
ленных угловых элементов. Совокупность таких векторов А описывает все объ-
екты заданного класса.
Основные методы идентификации и классификации изображений.
Идентификация объектов в СТЗ чаще всего производится методами сравнения с
эталоном. При этом, как правило, СТЗ решают одну из двух задач. Первая задача
заключается в получении изображения одного объекта и сравнении со всеми эта-
лонами заданного класса. По совпадению выбирается наилучший эталон и осу-
ществляется идентификация объекта, а затем при необходимости находятся па-
раметры его положения и ориентации.
Вторая задача заключается в получении изображения нескольких объекте в
и поочерёдном их сравнении с эталоном того объекта, который необходимо вы-
делить. После этого вычисляются его положение и ориентация в рабочей зоне
робота.
Полное совпадение объекта с эталоном в пространстве выбранных при-
знаков, как правило, не достигается, поэтому задаётся допустимое различие ме-
жду эталоном и изображением, в пределах этого различия и проверяется их сов-
падение.
Если обозначить исходное изображение объекта F(i, j), эталон E(i, j), а вы-
численное различие Т, то процедуру сравнения можно формально записать как
(
)
∑∑
∑
∑
−=
−=
ij
ij
jiEjiFT
jiEjiFT
.),(),(
;),(),(
2
(3.2)
Здесь индексы i и j характеризуют положение элементов в дискретном
цифровом изображении.
Совпадение эталона с объектом проверяется по правилу
T
D
≥
, (3.3)
где D – заданное пороговое различие.
Если условие (3.3) не выполняется, то необходимо заменить эталон или пе-
рейти к другому изображению.
Покажем особенности метода сравнения с эталонами при использовании
некоторых систем признаков. Если в качестве признаков выбраны площадь и пе-
риметр изображения, размеры вписанных и описанных фигур, момент инерции и
подобные геометрические свойства, то следует учесть масштабирование и на
этапе предварительной обработки нормировать изображения по какому-либо па-
раметру. Например, площадь описанного прямоугольника или окружности нор-
мируется квадратом периметра изображения, а периметр – значением корня
квадратного из площади изображения.
Важным методом идентификации изображений по геометрическим или
другим признакам служит метод построения графов решений. Его успешно при-
меняют в тех случаях, когда в заданном классе изображений имеются объекты,
которые невозможно различить по одному признаку изображения, и для пра-
вильного распознавания необходимо использовать несколько признаков. От ме-
тода сравнения изображения и эталона по векторам признаков метод графов от-
72
личается тем, что в нём на каждом этапе сравнения происходит отбор возмож-
ных решений. Таким образом, число возможных решений задачи распознавания
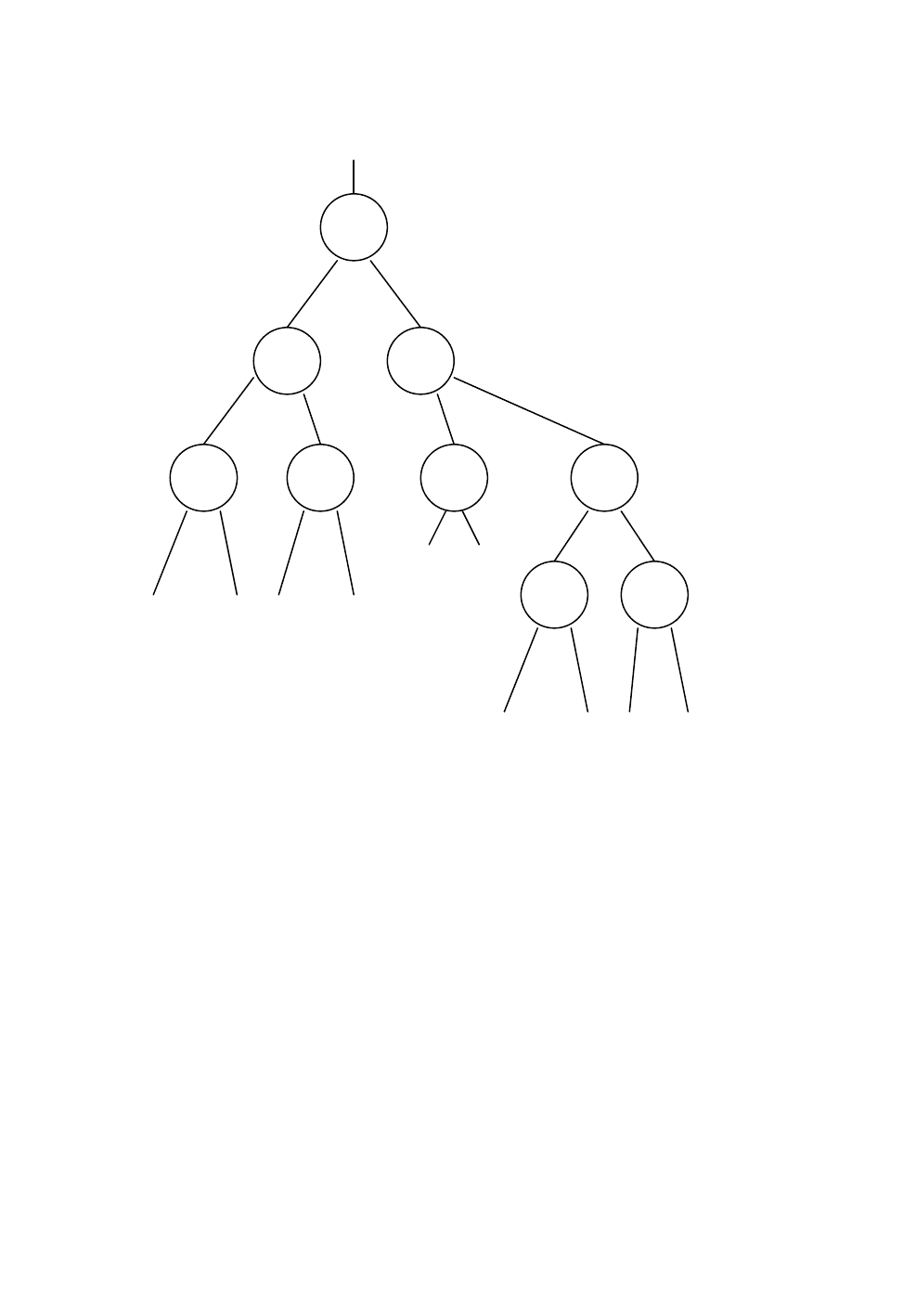
уменьшается на каждом этапе сравнения. Граф (или дерево) распознавания по
геометрическим признакам представлен на рисунке.
X II
I V III VIII
IV VII VI IX
Рис. 3.2. Дерево вывода
Цифрами I, II, ..., X обозначены возможные решения – номера распозна-
ваемых объектов. Буквы А, В, ..., Q в вершинах графа обозначают операторы, вы-
деляющие определённые признаки изображения. Например, оператор А проводит
классификацию изображения по длине и высоте описанного прямоугольника,
операторы В и С – по площади, DЕFG могут быть операторами, проводящими
классификацию по числу углов, H и Q – по отстоянию углов друг от друга. Граф
может иметь больше или меньше уровней, и содержание операторов может быть
различным.
Модификацией метода сравнения с эталоном является корреляционный ме-
тод, основанный на вычислении взаимокорреляционной функции между этало-
ном и изображением. Классификация изображений проводится, по результату:
чем больше значение функции взаимной корреляции, тем с большей вероятно-
стью эталон совпадает с изображением. Используя обозначения, принятые в вы-
ражении (3.2), формулу для вычисления взаимокорреляционной функции К мож-
но представить в виде
∑
∑
⋅=
ij
jiEjiFK ).,(),(
A
B C
D E F G
H Q

73
Максимальное значение взаимокорреляционной функции равно
(
)
∑
∑
ij
jiE
2
),(
.
Оно достигается при полном совпадении изображения с эталоном. Норми-
рованная взаимокорреляционная функция
()
∑∑
∑
∑
⋅
=
ij
ij
jiF
jiEjiF
R
2
),(
),(),(
при совпадении эталона с изображением достигает максимального значения,
равного единице.
Использование корреляционного метода и метода прямого сравнения с
эталоном предъявляет к процессу предварительной обработки изображений об-
щие требования. Они заключаются в том, что изображение и эталон должны
быть одинаково ориентированы, иметь равный масштаб и не быть сдвинутыми
друг относительно друга в поле изображения. Другим свойством этих методов,
которое следует учитывать, является необходимость использования большого
количества эталонов. Это особенно важно, в тех случаях, когда решаются задачи
распознавания объектов изменением их проекции.
Алгоритмы вычисления параметров положения объекта.
Под параметрами положения объекта обычно понимаются три значения
координат его центра масс и три угла, задающие его ориентацию в трёхмерном
пространстве. Чаще всего в робототехнических задачах обрабатываются двумер-
ные сцены, и под параметрами положения понимают две координаты на плоско-
сти и угол наклона оси симметрии объекта к одной из координатных осей.
Алгоритмы вычисления параметров положения объектов на двумерных
изображениях сцены могут быть реализованы, если на изображении с несколь-
кими объектами выделен один из них или если задано изображение с одним объ-
ектом.
В простейшем случае для определения положения объекта достаточно вы-
числить координаты центра описанного прямоугольника. Определяются макси-
мальная и минимальная абсциссы
max
j
и
min
j
и ординаты
max
i
и
min
i
, на кото-
рые в кадре попадает изображение объекта. В некоторых задачах требуется оп-
ределить «центр масс» изображения, тогда, вместо
ij
δ
используется функция яр-
кости
ij
f

74
.
;
∑∑
∑∑
∑∑
∑
∑
⋅
=
⋅
=
ij
ij
ij
ijij
c
ij
ij
ij
ijij
c
yf
y
xf
x
δ
δ
Как уже указывалось, задача определения ориентации плоского изображе-
ния сводится к вычислению наклона его оси симметрии к осям координат.
Рассмотрим систему координат поля зрения XOY. Допустим, что система
координат с началом в центре объекта X*CY* связана с осями симметрии
θθ
CYX
.
Тогда центробежный момент инерции
θ
J
относительно системы
θθ
CYX
равен
нулю. Его выражение и выражения моментов инерции
x
J
и
y
J
относительно
осей
θ
OX
и
θ
OY
имеют вид
∑
∑
⋅=
Θ
ij
ijij
yxJ
;0
=
ij
δ
∑∑
∑
∑
⋅−=
⋅−=
ij
ijcijy
ij
ijcijx
xyJ
xxJ
.)(
;)(
2
2
δ
δ
Переход от системы координат XOY к системе X*CY*:
c
xxx
−
=
;
c
yyy
−
=
.
Переход от системы X*CY* к системе
θθ
CYX
;sincos
θ
θ
⋅
−
⋅
=
Θ
yxx
.sinsin
θ
θ
⋅
−
⋅
=
Θ
yxy
Если теперь, используя подстановку, записать выражение для момента
θ
J
в системе координат X*CY* и приравнять его к нулю, то придём к уравнению
,2arctg
2
1
xy
xy
JJ
J
−
=
θ
где
∑
∑
⋅−⋅−=
ij
ijcijcijxy
yyxxJ .)()(
δ
Приведём в заключение ещё одну формулу для вычисления наклона оси
объекта. Эта формула широко применяется для определения наклона аппрокси-
мирующих прямых и получена по методу наименьших квадратов:
2
2
)(
tg
xx
xyxy
−
−
=
θ
, (3.4)

75
где
∑∑
∑∑
⋅
=
ij
ij
ij
ijij
x
x
δ
δ
;
∑∑
∑
∑
⋅
=
ij
ij
ij
ijij
y
y
δ
δ
;
∑∑
∑
∑
⋅⋅
=
ij
ij
ij
ijijij
yx
xy
δ
δ
;
∑∑
∑
∑
⋅
=
ij
ij
ij
ijij
x
x
δ
δ
2
2
)(
.
Однако выражение (3.4) позволяет вычислить наименьший угол наклона
осей объекта. Это означает, что если под меньшим углом к оси ОХ окажется на-
клонённой не продольная, а поперечная ось, то именно её наклон и будет вычис-
лен.
3.3. СХЕМА МОДЕЛИ ВОСПРИЯТИЯ РЕЧИ
Изобразим наиболее вероятную общую схему устройства, предназначен-
ного для распознавания достаточно большого количества (2÷3 тыс.) устных слов
[1]. На вход устройства поступает речевой сигнал, представляющий собой неста-
ционарную функцию времени f(t). Выходной блок должен выдавать решение о
принадлежности неизвестной реализации одному из заранее указанных 2÷3 ты-
сяч слов словаря Х0 с надёжностью P0, сравнимой с надёжностью распознавания
этих речевых сигналов человеком. Ясно, что такое устройство должно иметь ие-
рархическую структуру.
Необходимо уточнить количество ступеней (элементарных автоматов),
конкретизировать содержание каждой ступени и описать процедуру обработки
сигнала при его прохождении от входа до выхода устройства.
На каждом иерархическом уровне можно выделить блок, осуществляющий
процедуру восприятия (рецептор X
i
), блок принятия решения (классификатор D
i
)
и блок фиксации принятых с надежностью P
i
, решений (эффектор X
i
).
Можно ожидать, что из-за ограниченных возможностей классификатора D
i
,
распознавание элементов X
i
, будет производиться с неприемлемо низкой надёж-
ностью P
i
. Целесообразно было бы иметь на каждом уровне блоки исправления
ошибок (H
i
). Ошибки можно устранять за счёт априорной информации о речи и
языке, которая хранится в долговременной памяти. Эта информация имеет раз-
личную природу: это сведения либо об ограничениях в физических характери-
стиках речеобразующего аппарата, либо о лингвистических закономерностях
языка.
С учётом сказанного, процедура распознавания элементов на одном из
уровней может выглядеть следующим образом. Классификатор D
i
, указывает не-
сколько гипотез X
i
, к которым с наибольшей вероятностью может быть отнесён
вектор неизвестной реализации X
i
. Логически необходимо наличие некоторого
блока Q (назовём его «супервайзер»), который должен оценивать качество при-

76
нимаемых решений и по мере необходимости включать те или иные резервы по-
вышения надёжности распознавания. Оценка качества в простейшем случае мо-
жет состоять в определении разности ∆P
i
апостериорных вероятностей конкури-
рующих гипотез X
i
. Решение считается удовлетворительным, если ∆P
i
превыша-
ет некоторый фиксированный порог Q.
Повысить надёжность можно за счёт привлечения всё более полного опи-
сания реализации X
i
, т.е. анализа более широкого круга параметров. После того
как эти возможности исчерпаны, a ∆P
i
≤
Θ
, супервайзер включает блок исправле-
ния ошибок H
i
, за счёт априорной информации о характеристиках речевого трак-
та или лингвистических закономерностях. Такая последовательная процедура
повышения надёжности распознавания обеспечивает минимум математического
ожидания затрат на принятие решения.
Следует отметить, что порядок привлечения тех или иных средств по-
вышения надёжности распознавания зависит от отношения полезного эффекта
данного средства к затратам на его реализацию. Это отношение нам пока неиз-
вестно, поэтому набор и порядок включения средств супервайзером может и от-
личаться от описанного выше.
Если на некотором шаге вероятность одной гипотезы превысит вероят-
ность любой другой больше чем на
Θ
, то эта гипотеза X
i
поступает на вход сле-
дующей (i+1)-й ступени распознавания. В противном случае запоминается не-
сколько наиболее вероятных гипотез, которые затем передаются на вход (i+1)-го
уровня последовательно, в порядке убывания их вероятности. Можно предста-
вить себе и другой – параллельный – способ, при котором все конкурирующие
гипотезы одновременно поступают на входы нескольких однотипных классифи-
каторов (i+1)-го уровня. Если при последовательной схеме экономится количе-
ство функциональных элементов, то при параллельной – уменьшается время на
принятие решения.
Эффективность распараллеливания алгоритмов решения сложных задач на
вычислительных системах указывает на целесообразность параллельной схемы
обработки информации, особенно когда нужно получить высокую производи-
тельность на базе функциональных медленнодействующих элементов. Однако
прямых экспериментальных фактов в пользу той или иной схемы обработки ин-
формации мозгом мы пока не имеем.
Приведённые в начале данной работы факты говорят в пользу того, что на
уровне распознавания фонем решение принимается с учётом информации, рассе-
янной на участке типа открытого слога. Отсюда следует, что в схеме автомата
должен быть блок сегментации С, речевого потока на открытые слоги. Возмож-
но, блоки членения на участки того или иного типа присутствуют и на других
иерархических уровнях.
Итак, кроме X, D, X и P схеме должны фигурировать блоки Q, Н и С. Как
будет теперь выглядеть процедура обработки речевого сигнала при его прохож-
дении через распознающее устройство?

77
При последовательном варианте обработки (рис.3.3) речевой сигнал f(t)
преобразуется в самом начале в некоторое довольно полное описание в про-
странстве XI (частота – время). На участке («окно») некоторой длины, опреде-
ляемой ёмкостью оперативной памяти входных цепей слухового анализатора,
выделяются признаки XI типа статических и динамических характеристик фор-
мант, характеристик шумовой части спектра и т. д., нормализованных по громко-
сти, темпу и некоторым другим параметрам. Возможно, эта процедура расчленя-
ется на ряд более мелких этапов, например таких: нормализация по громкости,
выделение статических характеристик, нормализация по темпу, определение ди-
намических характеристик и т. п.
f(t)
X1 X2 X3
Рис. 3.3. Схема восприятия речи человеком (последовательный вариант)
В технических моделях может потребоваться сегментатор С1, устанавли-
вающий границы временного «окна».
Необходимая надёжность распознавания признаков P
i
может обеспечи-
ваться за счёт использования информации о физических законах речеобразова-
ния такого типа: частота основного тона меняется не быстрее некоторой ве-
личины; одновременное существование таких-то признаков невозможно; вслед
за такой-то комбинацией признаков наиболее вероятно появление таких-то при-
знаков и т. д.
В живых системах эти сведения, вероятно, заложены в конструкции бло-
ков, измеряющих характеристики речевого сигнала в виде постоянных времени,
ширины полосы частот, схем подавления или обострения различных максимумов
и пр. В технических устройствах информация о речеобразовании может хранить-
ся в долговременной памяти M1.
Использование информации подобного рода продолжается до тех пор, пока
вероятность какого-либо варианта признаков не станет больше вероятности дру-
M1
H1
D1
C1
S1P1
M2
H2
Q
D2
C2
S2P2
M3
H3
D3
C3
S3P3
Q
S0P0
Q

78
гих вариантов на некоторую пороговую величину
Θ
. Затем этот вариант посту-
пает на вход следующей ступени преобразования, где последовательность таких
признаков образует пространство описания Х2.
На втором уровне происходит распознавание фонем Х2. С этой целью
классификатор D2 использует информацию на участке типа открытого слога,
границы которого определяются сегментатором С2. Для сокращения чиста воз-
можных вариантов некоторой фонемы используется информация, содержащаяся
в описании Х2, а затем, если необходимо, и информация из M2 о структуре по-
следовательности фонем. С этой целью блоком Н2 формируются последователь-
ности наиболее вероятных вариантов фонем и, с учетом всех этих априорных и
апостериорных сведений, выбираемся наиболее вероятная последовательность.
Если разность вероятности этой избранной последовательности и любой другой
превышает некоторый порог
Θ
, то фонемный код слога передаётся на вход сле-
дующего блока. В противном случае категорического решения не принимается, и
запоминаются коды фонем XI нескольких (наиболее вероятных) слогов. Если же
этих вариантов слишком много, то можно повторить процедуру, вызвав по линии
Ql – Q2 на вход блока другой вариант признаков Х2.
Для распознавания слов из словаря Х0 пространство Х3, кроме кодов фо-
нем, должно содержать информацию и об ударениях. Сегментатор С3 осуще-
ствляет членение речевого потока на участки, от ударения до ударения. В двух
таких соседних участках содержится, так минимум, одно слово словаря Х0. По-
иск нужного слова и одновременное определение его границ может осуще-
ствляться с помощью алгоритма Лисенко [10]. Па этом этапе, как и раньше при
выборе решения могут использоваться дополнительные априорные сведения из
М3 об элементах словаря (блок Н3) и, если окажется необходимым, осуще-
ствляется вызов (по линии Q2 – Q3) на вход Х3 других вариантов фонемных по-
следовательностей.
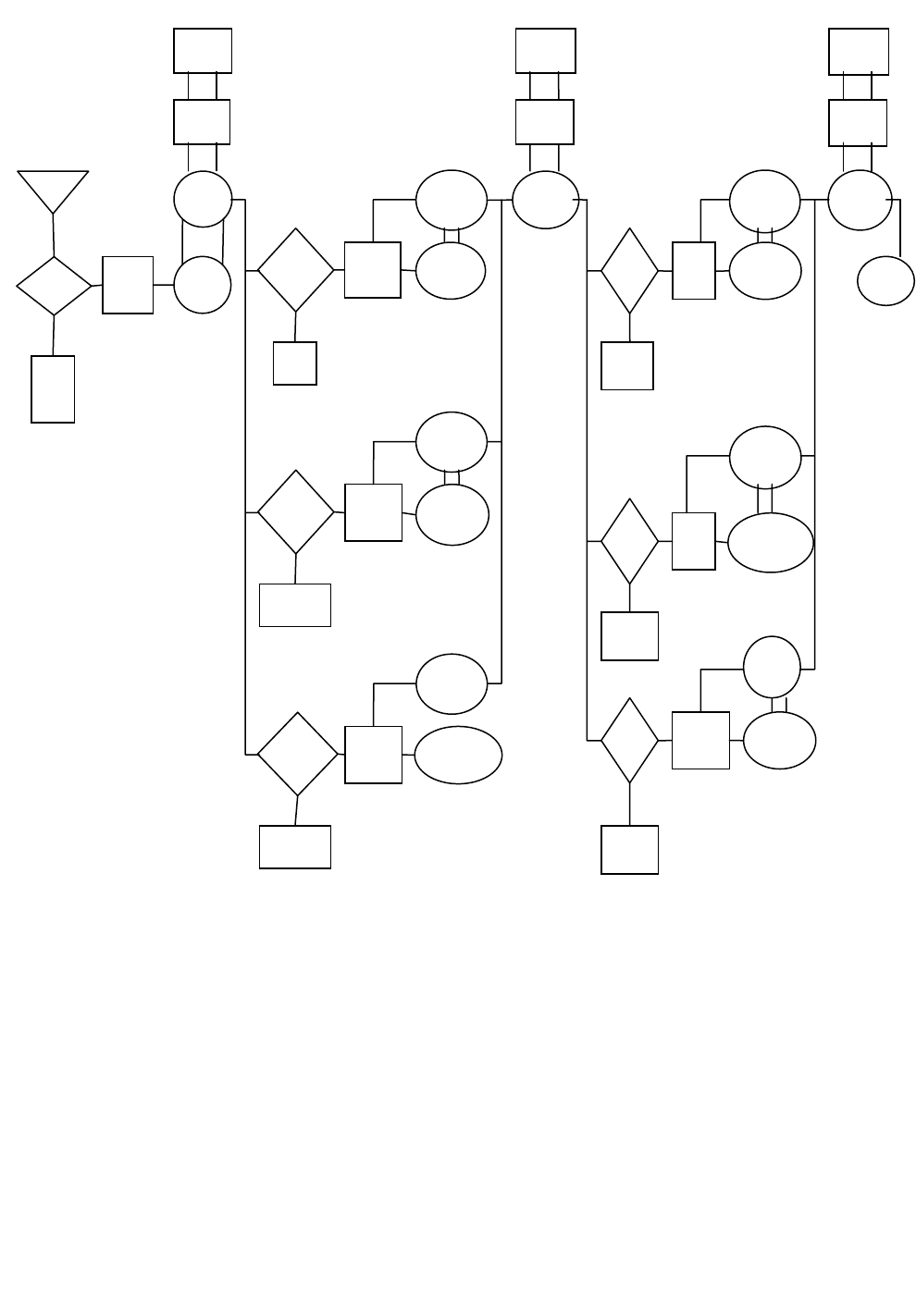
В отличие от этого в схеме с параллельно работающими блоками (рис 3.4)
на вход второго уровня передаётся одновременно несколько наиболее вероятных
вариантов признаков X1. В каждой из
α
ветвей классификатор D2
α
устанавливает
принадлежность вектора X2
α
одной из фонем алфавита Х2.
Наиболее вероятные гипотезы передаются супервайзерами q2
α
на вход су-
первайзера Q2, который функционирует так же, как и Q2 в последовательном ва-
рианте. Аналогичны особенности работы и параллельно работающих блоков
третьего уровня распознавания.
Эти схемы не противоречат известным в настоящее время фактам о вос-
приятии речи человека. Вместе с тем ясно, что дальнейшее развитие исследова-
ний в этой области приведёт как к конкретизации этих схем, так возможно, и к
необходимости их существенного изменения.
Ближайшие задачи, по нашему мнению, состоят с одной стороны, в даль-
нейшем исследовании структуры способов функционирования и взаимодействия
человеческих прототипов тех блоков, которые входят в приведённые выше схе-

79
мы, и с другой – в составлении и экспериментальной проверке алгоритмов рабо-
ты этих блоков.
3.4.
РАСПОЗНАВАНИЕ РЕЧИ НА ОСНОВЕ
НЕЙРОСЕТЕВОЙ АППРОКСИМАЦИИ ФОНЕМ
Задача автоматического распознавания речи до сих пор не имеет качест-
венного решения, которое бы позволило пользователю полноценно взаимодейст-
вовать с ЭВМ посредством голоса. Перед разработчиками встает ряд проблем,
среди которых в первую очередь следует выделить большую размерность и зна-
чительную нестабильность речевого сигнала. В частности, длительность произ-
несения может довольно серьезно варьироваться, изменяясь нелинейно в рамках
одного и того же слова.
В работе [14] в качестве аппарата для аппроксимации сигнала были вы-
браны искусственные нейросети. Задача распознавания речи при этом сводилась
к задаче нейросетевого прогнозирования динамики речевого процесса с после-
дующим фонетическим и лексическим анализом полученных цепочек выделен-
ных звуков, образующих слово. Обучающее множество для каждой нейросети
формируется методом окон на участке, априорно отнесенном к соответствующей
фонеме. В режиме распознавания тем же методом окон формировались входные
сигналы сети. Выходы сетей сравнивались с соответствующими реальными зна-
чениями сигнала и по минимуму ошибки делался вывод о фонеме, к которой
принадлежит данный участок речи.
Сложная форма и значительная нестабильность речевого сигнала не позво-
ляют делать вывод о фонеме по отдельным мгновенным значениям амплитуды.
Для получения достоверной информации необходимо рассматривать результаты
распознавания на достаточно большом участке и делать вывод по суммарной
ошибке каждой нейросети. Кроме того, в теории распознавания речи принято
считать, что использование одних только математических методов обработки ре-
чевого сигнала не позволяет достичь высокого уровня распознавания. Необходи-
мо привлечение лингвистических знаний, требующих рассмотрения отдельных
речевых единиц в контексте всего высказывания. Сочетание формально-
эвристических подходов положено в основу данного метода распознавания, пред-
ставленного функциональной схемой на рис. 3.5.
Первый уровень схемы состоит из N нейросетей, каждая из которых обучена на
распознавание одной фонемы. Для всех нейросетей используется один и тот же
входной образ, получаемый из «окна прогноза», скользящего вдоль оси времени
в пределах анализируемого сегмента речи. Прогнозные значения на выходах
нейросетей сравниваются с реальным значением речевого сигнала, и определяет-
ся ошибка, характеризующая степень принадлежности текущего окна данной
фонеме. На втором уровне схемы полученная ошибка накапливается на всей
протяженности окна сегмента речи.
80
Рис. 3.4 Схема восприятия речи человеком (параллельный вариант)
Интегральная ошибка для данного сегмента поступает на третий уровень,
где из всех фонем селектором выбираются наилучшие по критерию минимума
ошибки. Полученный набор фонем участвует в формировании цепочек, пред-
ставляющих гипотезы о произносимом слове. Каждая из гипотез характеризуется
степенью достоверности, определяемой как суммарная достоверность входящих
в неё фонем. Наконец, на последнем уровне схемы, используя знания о синтакси-
се и семантике допустимых высказываний, выбирается лучшая из полученных
гипотез, определяющая произнесенное слово.
Проиллюстрируем работу метода на примере распознавания слова «один».
В примере задействовано 4 фонемы. Архитектура нейросетей для распознавания
отдельных фонем применялась одинаковой: трехслойные сети обратного распро-
странения с 80 входами и количеством нейронов в слоях 10–10–1.
1
M
1
H
1
Q
1
B
1
P
S
1
C
1
2
q
1
2
D
1
2
1
2
PS
1
2
C
2
2
q
2
2
D
2
2
2
2
PS
2
2
C
a
q
2
a
D
2
aa
PS
22
a
C
2
2
M
2
Q
1
3
q
3
D
1
3
1
3
PS
2
3
q
3
D
2
3
2
3
PS
2
3
C
a
q
3
a
D
3
a
a
PS
33
a
C
3
3
M
3
H
3
Q
00
PS
2
H
1
X
f
(
t
)
1
2
x
2
2
x
a
x
2
a
x
3
1
3
x
2
3
x
1
3
С