Berg J.M., Tymoczko J.L., Stryer L. Biochemistry
Подождите немного. Документ загружается.

III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.1. Transcription Is Catalyzed by RNA Polymerase
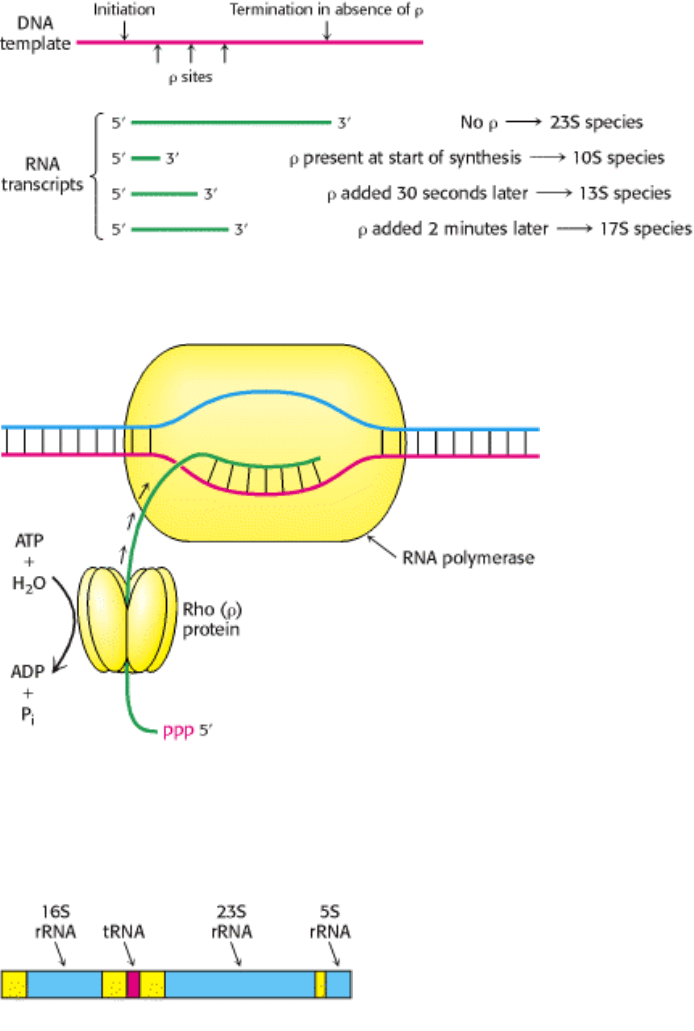
Figure 28.11. Effect of ρ Protein On the Size of RNA Transcripts.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.1. Transcription Is Catalyzed by RNA Polymerase
Figure 28.12. Mechanism For the Termination of Transcription by ρ Protein. This protein is an ATP-dependent
helicase that binds the nascent RNA chain and pulls it away from RNA polymerase and the DNA template.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.1. Transcription Is Catalyzed by RNA Polymerase
Figure 28.13. Primary Transcript. Cleavage of this transcript produces 5S, 16S, and 23S rRNA molecules and a tRNA
molecule. Spacer regions are shown in yellow.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.1. Transcription Is Catalyzed by RNA Polymerase
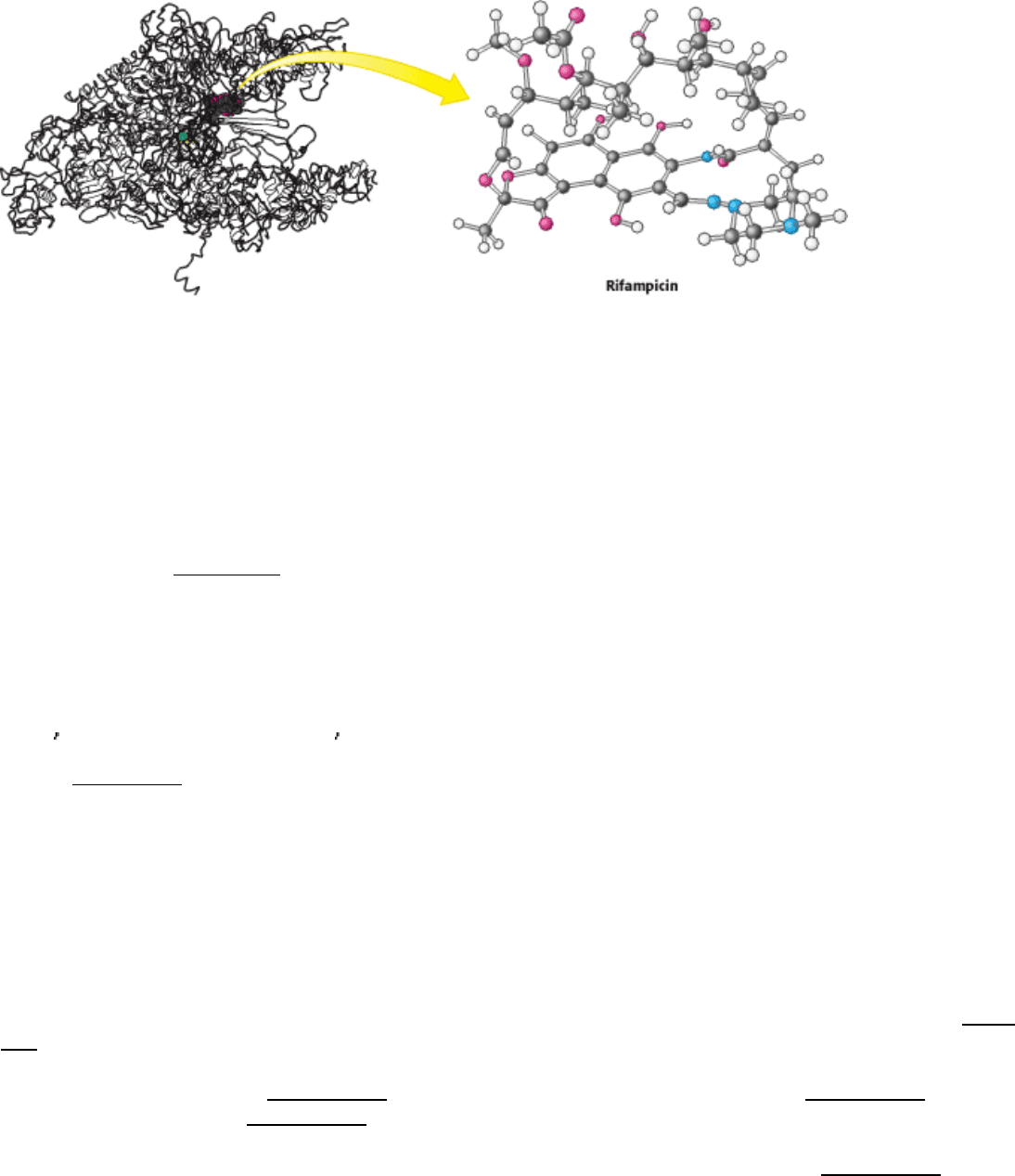
Figure 28.14. Antibiotic Action. Rifampicin binds to a pocket in the channel that is normally occupied by the newly
formed RNA-DNA hybrid. Thus the antibiotic blocks elongation after only two or three nucleotides have been added.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing
28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
We turn now to transcription in eukaryotes, a much more complex process than in prokaryotes. In eukaryotes,
transcription and translation take place in different cellular compartments: transcription takes place in the membrane-
bounded nucleus, whereas translation takes place outside the nucleus in the cytoplasm. In prokaryotes, the two processes
are closely coupled (Figure 28.15). Indeed, the translation of bacterial mRNA begins while the transcript is still being
synthesized. The spatial and temporal separation of transcription and translation enables eukaryotes to regulate gene
expression in much more intricate ways, contributing to the richness of eukaryotic form and function.
A second major difference between prokaryotes and eukaryotes is the extent of RNA processing. Although both
prokaryotes and eukaryotes modify tRNA and rRNA, eukaryotes very extensively process nascent RNA destined to
become mRNA. Primary transcripts (pre-mRNA molecules), the products of RNA polymerase action, acquire a cap at
their 5
ends and a poly(A) tail at their 3 ends. Most importantly, nearly all mRNA precursors in higher eukaryotes are
spliced (Section 5.6.1). Introns are precisely excised from primary transcripts, and exons are joined to form mature
mRNAs with continuous messages. Some mRNAs are only a tenth the size of their precursors, which can be as large as
30 kb or more. The pattern of splicing can be regulated in the course of development to generate variations on a theme,
such as membrane-bound and secreted forms of antibody molecules. Alternative splicing enlarges the repertoire of
proteins in eukaryotes and is a clear illustration of why the proteome is more complex than the genome.
28.2.1. RNA in Eukaryotic Cells Is Synthesized by Three Types of RNA Polymerase
In prokaryotes, RNA is synthesized by a single kind of polymerase. In contrast, the nucleus of a eukaryote contains three
types of RNA polymerase differing in template specificity, location in the nucleus, and susceptibility to inhibitors (Table
28.2). All these polymerases are large proteins, containing from 8 to 14 subunits and having a total molecular mass
greater than 500 kd. RNA polymerase I is located in nucleoli, where it transcribes the tandem array of genes for 18S,
5.8S, and 28S ribosomal RNA (Section 29.3.1). The other ribosomal RNA molecule (5S rRNA, Section 29.3.1) and all
the transfer RNA molecules (Section 29.1.2) are synthesized by RNA polymerase III, which is located in the nucleoplasm
rather than in nucleoli. RNA polymerase II, which also is located in the nucleoplasm, synthesizes the precursors of
messenger RNA as well as several small RNA molecules, such as those of the splicing apparatus (Section 28.3.5).
Although all eukaryotic RNA polymerases are homologous to one another and to prokaryotic RNA polymerase, RNA
polymerase II contains a unique carboxyl-terminal domain on the 220-kd subunit; this domain is unusual because it
contains multiple repeats of a YSPTSPS consensus sequence. The activities of RNA polymerase II are regulated by
phosphorylation on the serine and threonine residues of the carboxyl-terminal domain. Another major distinction among
the polymerases lies in their responses to the toxin α -amanitin, a cyclic octapeptide that contains several modified
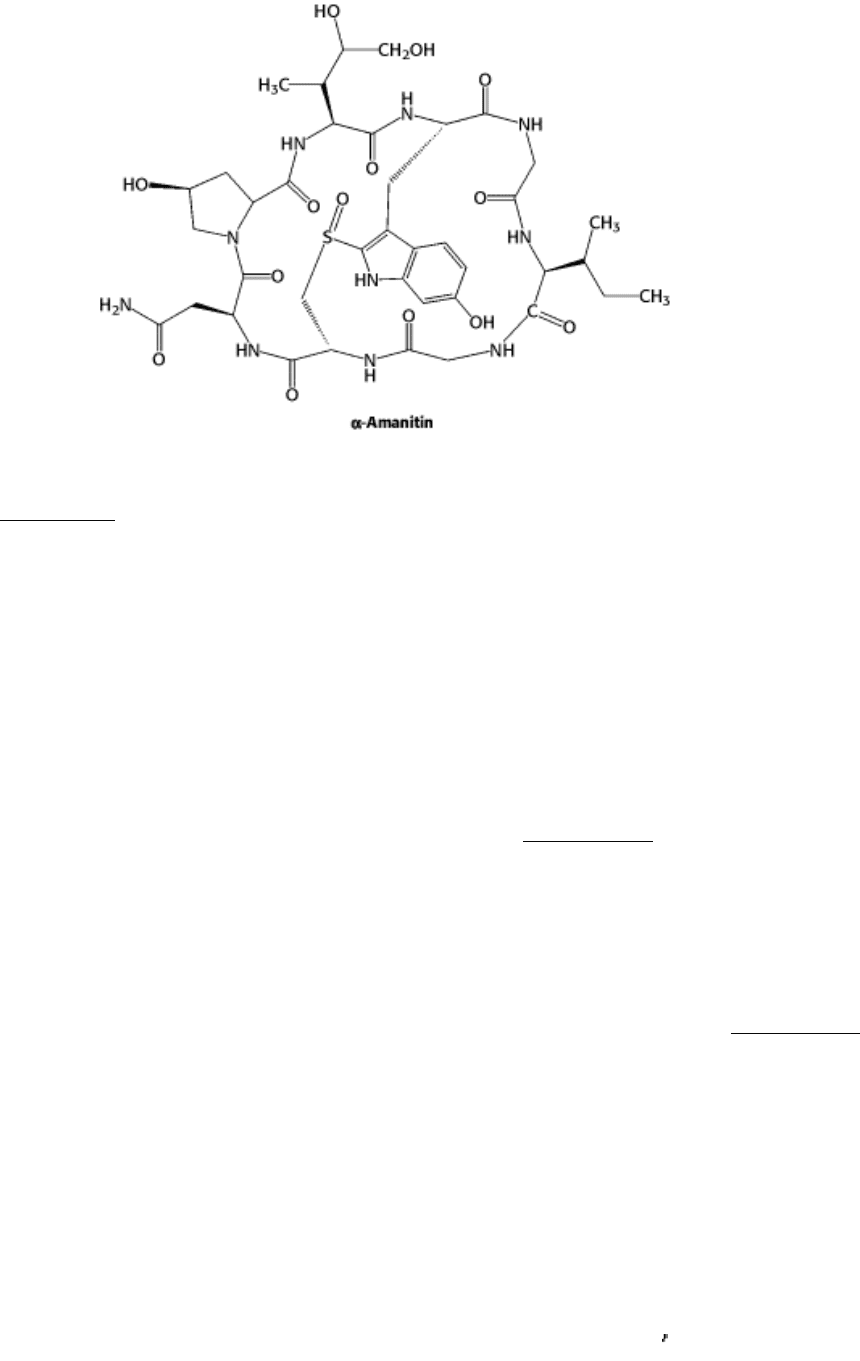
amino acids.
α-Amanitin is produced by the poisonous mushroom Amanita phalloides, which is also called the death cup or the
destroying angel (Figure 28.16). More than a hundred deaths result worldwide each year from the ingestion of poisonous
mushrooms. α-Amanitin binds very tightly (K
d
= 10 nM) to RNA polymerase II and thereby blocks the elongation
phase of RNA synthesis. Higher concentrations of α-amanitin (1 µM) inhibit polymerase III, whereas polymerase I is
insensitive to this toxin. This pattern of sensitivity is highly conserved throughout the animal and plant kingdoms.
28.2.2. Cis- And Trans-Acting Elements: Locks and Keys of Transcription
Eukaryotic genes, like their prokaryotic counterparts, require promoters for transcription initiation. Each of the three
types of polymerase has distinct promoters. RNA polymerase I transcribes from a single type of promoter, present only
in rRNA genes, that encompasses the initiation site. In some genes, RNA polymerase III responds to promoters located
in the normal, upstream position; in other genes, it responds to promoters imbedded in the genes, downstream of the
initiation site. Promoters for RNA polymerase II can be simple or complex (Section 28.2.3). As is the case for
prokaryotes, promoters are always on the same molecule of DNA as the gene they regulate. Consequently, promoters are
referred to as cis-acting elements.
However, promoters are not the only types of cis-acting DNA sequences. Eukaryotes and their viruses also contain
enhancers. These DNA sequences, although not promoters themselves, can enormously increase the effectiveness of
promoters. Interestingly, the positions of enhancers relative to promoters are not fixed; they can vary substantially.
Enhancers play key roles in regulating gene expression in a specific tissue or developmental stage (Section 31.2.4).
The DNA sequences of cis-acting elements are binding sites for proteins called transcription factors. Such a protein is
sometimes called a trans-acting factor because it may be encoded by a gene on a DNA molecule other than that
containing the gene being regulated. The binding of a transcription factor to its cognate DNA sequence enables the RNA
polymerase to locate the proper initiation site. We will continue our investigation of transcription by examining these
cis- and trans-acting elements in turn.
28.2.3. Most Promoters for RNA Polymerase II Contain a TATA Box Near the
Transcription Start Site
Promoters for RNA polymerase II, like those for bacterial polymerases, are located on the 5
side of the start site for
transcription. The results of mutagenesis experiments, footprinting studies, and comparisons of many higher eukaryotic

genes have demonstrated the importance of several upstream regions. For most genes transcribed by RNA polymerase II,
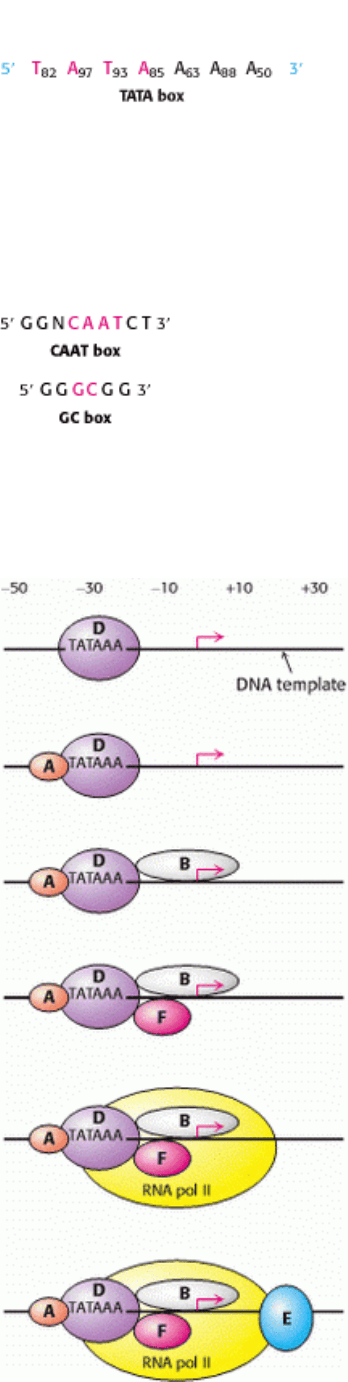
the most important cis-acting element is called the TATA box on the basis of its consensus sequence (Figure 28.17). The
TATA box is usually centered between positions -30 and -100. Note that the eukaryotic TATA box closely resembles the
prokaryotic - 10 sequence (TATAAT) but is farther from the start site. The mutation of a single base in the TATA box
markedly impairs promoter activity. Thus, the precise sequence, not just a high content of AT pairs, is essential.
The TATA box is necessary but not sufficient for strong promoter activity. Additional elements are located between -40
and -150. Many promoters contain a CAAT box, and some contain a GC box (Figure 28.18). Constitutive genes (genes
that are continuously expressed rather than regulated) tend to have GC boxes in their promoters. The positions of these
upstream sequences vary from one promoter to another, in contrast with the quite constant location of the -35 region in
prokaryotes. Another difference is that the CAAT box and the GC box can be effective when present on the template
(antisense) strand, unlike the -35 region, which must be present on the coding (sense) strand. These differences between
prokaryotes and eukaryotes reflect fundamentally different mechanisms for the recognition of cis-acting elements. The -
10 and -35 sequences in prokaryotic promoters correspond to binding sites for RNA polymerase and its associated σ
factor. In contrast, the TATA, CAAT, and GC boxes and other cis-acting elements in eukaryotic promoters are
recognized by proteins other than RNA polymerase itself.
28.2.4. The TATA-Box-Binding Protein Initiates the Assembly of the Active
Transcription Complex
Cis-acting elements constitute only part of the puzzle of eukaryotic gene expression. Transcription factors that bind to
these elements also are required. For example, RNA polymerase II is guided to the start site by a set of transcription
factors known collectively as TFII (TF stands for transcription factor, and II refers to RNA polymerase II). Individual
TFII factors are called TFIIA, TFIIB, and so on. Initiation begins with the binding of TFIID to the TATA box (Figure
28.19).
The key initial event is the recognition of the TATA box by the TATA-box-binding protein (TBP), a 30-kd component
of the 700-kd TFIID complex. TBP binds 10
5
times as tightly to the TATA box as to noncognate sequences; the
dissociation constant of the specific complex is approximately 1 nM. TBP is a saddle-shaped protein consisting of two
similar domains (Section 7.3.3; Figure 28.20). The TATA box of DNA binds to the concave surface of TBP. This
binding induces large conformational changes in the bound DNA. The double helix is substantially unwound to widen its
minor groove, enabling it to make extensive contact with the antiparallel β strands on the concave side of TBP.
Hydrophobic interactions are prominent at this interface. Four phenylalanine residues, for example, are intercalated
between base pairs of the TATA box. The flexibility of AT-rich sequences is generally exploited here in bending the
DNA. Immediately outside the TATA box, classical B-DNA resumes. This complex is distinctly asymmetric. The
asymmetry is crucial for specifying a unique start site and ensuring that transcription proceeds unidirectionally.
TBP bound to the TATA box is the heart of the initiation complex (see Figure 28.19). The surface of the TBP saddle
provides docking sites for the binding of other components (Figure 28.21). Additional transcription factors assemble on
this nucleus in a defined sequence. TFIIA is recruited, followed by TFIIB and then TFIIF an ATP-dependent helicase
that initially separates the DNA duplex for the polymerase. Finally, RNA polymerase II and then TFIIE join the other
factors to form a complex called the basal transcription apparatus. Sometime in the formation of this complex, the
carboxyl-terminal domain of the polymerase is phosphorylated on the serine and threonine residues, a process required
for successful initiation. The importance of the carboxyl-terminal domain is highlighted by the finding that yeast
containing mutant polymerase II with fewer than 10 repeats is not viable. Most of the factors are released before the
polymerase leaves the promoter and can then participate in another round of initiation.
Although bacteria lack TBP, archaea utilize a TBP molecule that is structurally quite similar to the eukaryotic
protein. In fact, transcriptional control processes in archaea are, in general, much more similar to those in
eukaryotes than are the processes in bacteria. Many components of the eukaryotic transcriptional machinery evolved
from an ancestor of archaea.

28.2.5. Multiple Transcription Factors Interact with Eukaryotic Promoters
The basal transcription complex described in Section 28.2.4. initiates transcription at a relatively low frequency.
Additional transcription factors that bind to other sites are required to achieve a high rate of mRNA synthesis and to
selectively stimulate specific genes. Upstream stimulatory sites in eukaryotic genes are diverse in sequence and variable
in position. Their variety suggests that they are recognized by many different specific proteins. Indeed, many
transcription factors have been isolated, and their binding sites have been identified by footprinting experiments (Figure
28.22). For example, Sp1, an ~ 100-kd protein from mammalian cells, binds to promoters that contain GC boxes. The
duplex DNA of SV40 virus (a cancer-producing virus that infects monkey cells) contains five GC boxes from 50 to 100
bp upstream or downstream of start sites. The CCAAT-binding transcription factor (CTF; also called NF1), a 60-kd
protein from mammalian cells, binds to the CAAT box. A heat-shock transcription factor (HSTF) is expressed in
Drosophila after an abrupt increase in temperature. This 93-kd DNA-binding protein binds to the consensus sequence
Several copies of this sequence, known as the heat-shock response element, are present starting at a site 15 bp upstream
of the TATA box. HSTF differs from σ
32
, a heat-shock protein of E. coli (Section 28.1.2), in binding directly to
response elements in heat-shock promoters rather than first becoming associated with RNA polymerase.
28.2.6. Enhancer Sequences Can Stimulate Transcription at Start Sites Thousands of
Bases Away
The activities of many promoters in higher eukaryotes are greatly increased by another type of cis-acting element called
an enhancer. Enhancers' sequences have no promoter activity of their own yet can exert their stimulatory actions over
distances of several thousand base pairs. They can be upstream, downstream, or even in the midst of a transcribed gene.
Moreover, enhancers are effective when present on either DNA strand (equivalently, in either orientation). Enhancers in
yeast are known as upstream activator sequences (UASs).
A particular enhancer is effective only in certain cells. For example, the immunoglobulin enhancer functions in B
lymphocytes but not elsewhere. Cancer can result if the relation between genes and enhancers is disrupted. In
Burkitt lymphoma and B-cell leukemia, a chromosomal translocation brings the proto-oncogene myc (a transcription
factor itself) under the control of a powerful immunoglobin enhancer. The consequent dysregulation of the myc gene is
believed to play a role in the progression of the cancer.
Transcription factors and other proteins that bind to regulatory sites on DNA can be regarded as passwords that
cooperatively open multiple locks, giving RNA polymerase access to specific genes. The discovery of promoters and
enhancers has opened the door to understanding how genes are selectively expressed in eukaryotic cells. The regulation
of gene transcription, discussed in Chapter 31, is the fundamental means of controlling gene expression.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
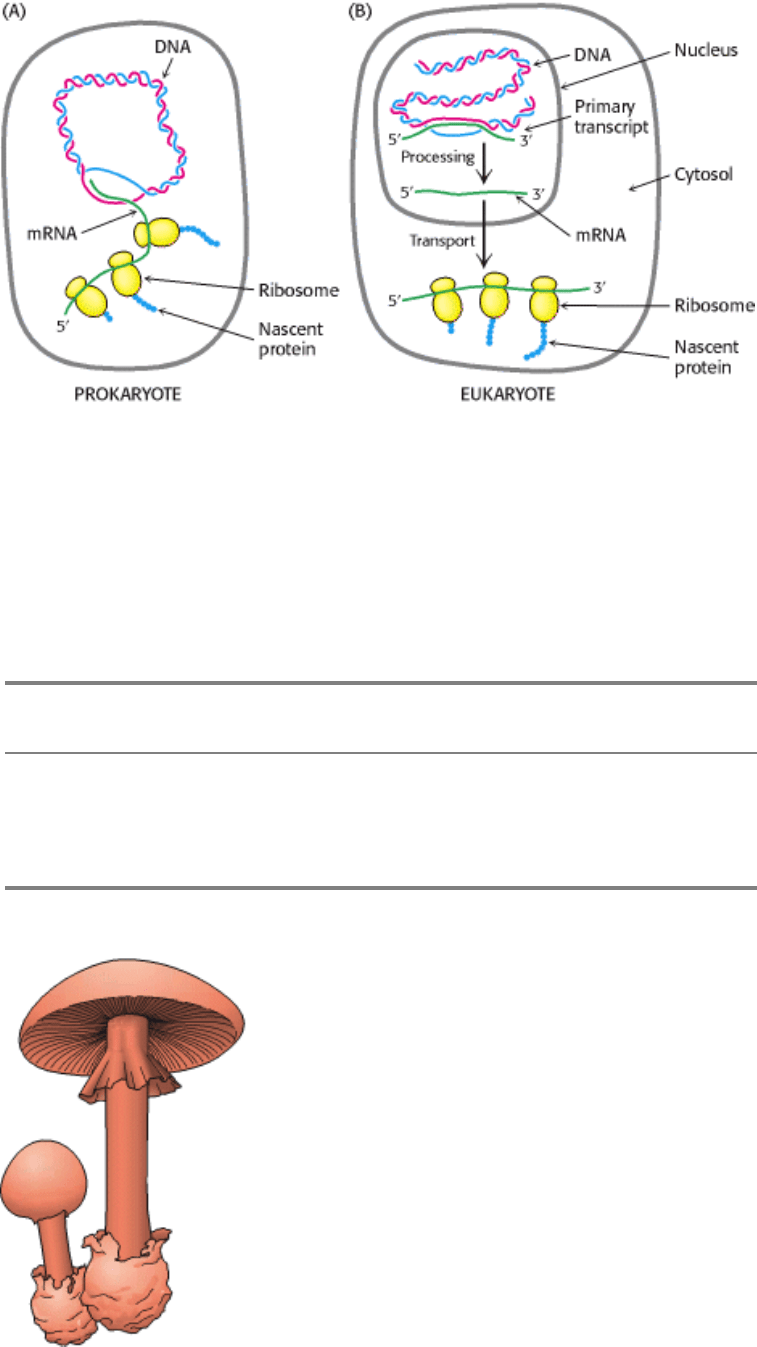
Figure 28.15. Transcription and Translation. These two processes are closely coupled in prokaryotes, whereas they
are spacially and temporally separate in eukaryotes. (A) In prokaryotes, the primary transcript serves as mRNA and is
used immediately as the template for protein synthesis. (B) In eukaryotes, mRNA precursors are processed and spliced in
the nucleus before being transported to the cytosol for translation into protein. [After J. Darnell, H. Lodish, and D.
Baltimore. Molecular Cell Biology, 2d ed. (Scientific American Books, 1990), p. 230.]
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Table 28.2. Eukaryotic RNA polymerases
Type Location Cellular transcripts
Effects of α-amanitin
I Nucleolus 18S, 5.8S, and 28S rRNA Insensitive
II Nucleoplasm mRNA precursors and snRNA Strongly inhibited
III Nucleoplasm tRNA and 5S rRNA Inhibited by high concentrations
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.16. RNA Polymerase Poison. Amanita phalloides, a poisonous mushroom that produces α-amanitin. [After
G. Lincoff and D. H. Mitchel, Toxic and Hallucinogenic Mushroom Poisoning (Van Nostrand Reinhold, 1977), p. 30.]
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.17. TATA Box. Comparisons of the sequences of more than 100 eukaryotic promoters led to the consensus
sequence shown. The subscripts denote the frequency (%) of the base at that position.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.18. CAAT Box and GC Box. Consensus sequences for the CAAT and GC boxes of eukaryotic promoters for
mRNA precursors.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time

Figure 28.19. Transcription Initiation. Transcription factors TFIIA, B, D, E, and F are essential in initiating
transcription by RNA polymerase II. The step-by-step assembly of these general transcription factors begins with the
binding of TFIID (purple) to the TATA box. The arrow marks the transcription start site. [After L. Guarente. Trends
Genet. 8(1992):28.]
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.20. Complex Formed by TATA-Box-Binding Protein and DNA.
The saddlelike structure of the protein sits
atop a DNA fragment that is both significantly unwound and bent.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.21. Assembly of the Initiation Complex.
A ternary complex between the TATA-box-binding protein
(purple), TFIIA (orange), and DNA. TFIIA interacts primarily with the other protein.
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing 28.2. Eukaryotic Transcription and Translation Are Separated in Space and Time
Figure 28.22. Transcription-Factor-Binding Sites. These multiple binding sites for transcription factors were mapped
by footprinting. (A) Binding of Sp1 (green) to the SV40 viral promoter and to the dihydrofolate reductase (DHFR)
promoter. (B) Binding of HSTF (blue) to a Drosophila heat-shock promoter. [After W. S. Dynan and R. Tjian. Nature

316(1985):774.]
III. Synthesizing the Molecules of Life 28. RNA Synthesis and Splicing
28.3. The Transcription Products of All Three Eukaryotic Polymerases Are Processed
Virtually all the initial products of transcription are further processed in eukaryotes. For example, tRNA precursors are
converted into mature tRNAs by a series of alterations: cleavage of a 5
leader sequence, splicing to remove an intron,
replacement of the 3
-terminal UU by CCA, and modification of several bases (Figure 28.23). A series of enzymes may
act on the ribonucleic acid chain or its constituent bases to achieve the final product.
28.3.1. The Ends of the Pre-mRNA Transcript Acquire a 5 Cap and a 3 Poly(A) Tail
Perhaps the most extensively modified transcription product is the product of RNA polymerase II: the majority of this
RNA will be processed to mRNA. The immediate product of an RNA polymerase is sometimes referred to as pre-mRNA.
Most pre-mRNA molecules are spliced to remove the introns. Moreover, both the 5
and the 3 ends are modified, and
both modifications are retained as the pre-mRNA is converted into mRNA (Section 28.3.3). As in prokaryotes,
eukaryotic transcription usually begins with A or G. However, the 5
triphosphate end of the nascent RNA chain is
immediately modified. First, a phosphate is released by hydrolysis. The diphosphate 5
end then attacks the α-
phosphorus atom of GTP to form a very unusual 5
-5 triphosphate linkage. This distinctive terminus is called a cap
(Figure 28.24). The N-7 nitrogen of the terminal guanine is then methylated by S-adenosylmethionine to form cap 0. The
adjacent riboses may be methylated to form cap 1 or cap 2. Transfer RNA and ribosomal RNA molecules, in contrast
with messenger RNAs and small RNAs that participate in splicing, do not have caps. Caps contribute to the stability of
mRNAs by protecting their 5
ends from phosphatases and nucleases. In addition, caps enhance the translation of mRNA
by eukaryotic proteinsynthesizing systems (Section 29.5).
As mentioned earlier, pre-mRNA is also modified at the 3
end. Most eukaryotic mRNAs contain a polyadenylate, poly
(A), tail at that end, added after transcription has ended. Thus, DNA does not encode this poly(A) tail. Indeed, the
nucleotide preceding poly(A) is not the last nucleotide to be transcribed. Some primary transcripts contain hundreds of
nucleotides beyond the 3
end of the mature mRNA.
How is the 3
end of the pre-mRNA given its final form? Eukaryotic primary transcripts are cleaved by a specific
endonuclease that recognizes the sequence AAUAAA (Figure 28.25). Cleavage does not occur if this sequence or a
segment of some 20 nucleotides on its 3
side is deleted. The presence of internal AAUAAA sequences in some mature
mRNAs indicates that AAUAAA is only part of the cleavage signal; its context also is important. After cleavage by the
endonuclease, a poly(A) polymerase adds about 250 adenylate residues to the 3
end of the transcript; ATP is the donor in
this reaction.
The role of the poly(A) tail is still not firmly established despite much effort. However, evidence that it enhances
translation efficiency and the stability of mRNA is accumulating. Blocking the synthesis of the poly(A) tail by exposure
to 3
-deoxyadenosine (cordycepin) does not interfere with the synthesis of the primary transcript. Messenger RNA
devoid of a poly(A) tail can be transported out of the nucleus. However, an mRNA molecule devoid of a poly(A) tail is
usually a much less effective template for protein synthesis than is one with a poly(A) tail. Indeed, some mRNAs are
stored in an unadenylated form and receive the poly(A) tail only when translation is imminent. The half-life of an mRNA
molecule may also be determined in part by the rate of degradation of its poly(A) tail.
28.3.2. RNA Editing Changes the Proteins Encoded by mRNA
The sequence content of some mRNAs is altered after transcription. RNA editing is the term for a change in the base
sequence of RNA after transcription by processes other than RNA splicing. RNA editing is prominent in some systems

already discussed. Apolipoprotein B (apo B) plays an important role in the transport of triacylglycerols and cholesterol
by forming an amphipathic spherical shell around the lipids carried in lipoprotein particles (Section 26.3.1). Apo B exists
in two forms, a 512-kd apo B-100 and a 240-kd apo B-48. The larger form, synthesized by the liver, participates in the
transport of lipids synthesized in the cell. The smaller form, synthesized by the small intestine, carries dietary fat in the
form of chylomicrons. Apo B-48 contains the 2152 N-terminal residues of the 4536-residue apo B-100. This truncated
molecule can form lipoprotein particles but cannot bind to the low-density-lipoprotein receptor on cell surfaces. What is
the biosynthetic relation of these two forms of apo B? One possibility a priori is that apo B-48 is produced by proteolytic
cleavage of apo B-100, and another is that the two forms arise from alternative splicing (see Section 28.3.6). The results
of experiments show that neither occurs. A totally unexpected and new mechanism for generating diversity is at work:
the changing of the nucleotide sequence of mRNA after its synthesis (Figure 28.26). A specific cytidine residue of mRNA
is deaminated to uridine, which changes the codon at residue 2153 from CAA (Gln) to UAA (stop). The deaminase that
catalyzes this reaction is present in the small intestine, but not in the liver, and is expressed only at certain developmental
stages.
RNA editing is not confined to apolipoprotein B. Glutamate opens cation-specific channels in the vertebrate central
nervous system by binding to receptors in postsynaptic membranes. RNA editing changes a single glutamine codon
(CAG) in the mRNA for the glutamate receptor to the codon for arginine (read as CGG). The substitution of Arg for Gln
in the receptor prevents Ca
2+
, but not Na
+
, from flowing through the channel. RNA editing is likely much more common
than was previously thought. The chemical reactivity of nucleotide bases, including the susceptibility to deamination that
necessitates complex DNA-repair mechanisms (Section 27.6.3), has been harnessed as an engine for generating
molecular diversity at the RNA and, hence, protein levels.
In trypanosomes (parasitic protozoans), a different kind of RNA editing markedly changes several mitochondrial
mRNAs. Nearly half the uridine residues in these mRNAs are inserted by RNA editing. A guide RNA molecule identifies
the sequences to be modified, and a poly(U) tail on the guide donates uridine residues to the mRNAs undergoing editing.
It is evident that DNA sequences do not always faithfully disclose the sequence of encoded proteins
functionally
crucial changes to mRNA can take place.
28.3.3. Splice Sites in mRNA Precursors Are Specified by Sequences at the Ends of
Introns
Most genes in higher eukaryotes are composed of exons and introns. The introns must be excised and the exons linked to
form the final mRNA in a process called splicing. This splicing must be exquisitely sensitive: a one-nucleotide slippage
in a splice point would shift the reading frame on the 3
side of the splice to give an entirely different amino acid
sequence. Thus, the correct splice site must be clearly marked. Does a particular sequence denote the splice site? The
base sequences of thousands of intron- exon junctions within RNA transcripts are known. In eukaryotes from yeast to
mammals, these sequences have a common structural motif: the base sequence of an intron begins with GU and ends
with AG. The consensus sequence at the 5
splice in vertebrates is AGGUAAGU (Figure 28.27). At the 3 end of an
intron, the consensus sequence is a stretch of 10 pyrimidines (U or C), followed by any base and then by C, and ending
with the invariant AG. Introns also have an important internal site located between 20 and 50 nucleotides upstream of the
3
splice site; it is called the branch site for reasons that will be evident shortly. In yeast, the branch site sequence is
nearly always UACUAAC, whereas in mammals a variety of sequences are found.
Parts of introns other than the 5
and 3 splice sites and the branch site appear to be less important in determining where
splicing takes place. The length of introns ranges from 50 to 10,000 nucleotides. Much of an intron can be deleted
without altering the site or efficiency of splicing. Likewise, splicing is unaffected by the insertion of long stretches of
DNA into the introns of genes. Moreover, chimeric introns crafted by recombinant DNA methods from the 5
end of one
intron and the 3
end of a very different intron are properly spliced, provided that the splice sites and branch site are
unaltered. In contrast, mutations in each of these three critical regions lead to aberrant splicing.
Despite our knowledge of splice-site sequences, predicting splicing patterns from genomic DNA sequence information