Berg J.M., Tymoczko J.L., Stryer L. Biochemistry
Подождите немного. Документ загружается.


J. Zhao, L. Hyman, and C. Moore. 1999. Formation of mRNA 3 ends in eukaryotes: Mechanism, regulation, and
interrelationships with other steps in mRNA synthesis Microbiol. Mol. Biol. Rev. 63: 405-445. (PubMed) (Full Text in
PMC)
L. Minvielle-Sebastia and W. Keller. 1999. mRNA polyadenylation and its coupling to other RNA processing reactions
and to transcription Curr. Opin. Cell Biol. 11: 352-357. (PubMed)
E. Wahle and U. Kuhn. 1997. The mechanism of 3 cleavage and polyadenylation of eukaryotic pre-mRNA Prog.
Nucleic Acid Res. Mol. Biol. 57: 41-71. (PubMed)
RNA editing
J.M. Gott and R.B. Emeson. 2000. Functions and mechanisms of RNA editing Annu. Rev. Genet. 34: 499-531. (PubMed)
L. Simpson, O.H. Thiemann, N.J. Savill, J.D. Alfonzo, and D.A. Maslov. 2000. Evolution of RNA editing in
trypanosome mitochondria Proc. Natl. Acad. Sci. USA 97: 6986-6993. (PubMed) (Full Text in PMC)
A. Chester, J. Scott, S. Anant, and N. Navaratnam. 2000. RNA editing: Cytidine to uridine conversion in apolipoprotein
B mRNA Biochim. Biophys. Acta 1494: 1-3. (PubMed)
S. Maas and A. Rich. 2000. Changing genetic information through RNA editing Bioessays 22: 790-802. (PubMed)
Splicing of mRNA precursors
H. Stark, P. Dube, R. Luhrmann, and B. Kastner. 2001. Arrangement of RNA and proteins in the spliceosomal U1 small
nuclear ribonucleoprotein particle Nature 409: 539-542. (PubMed)
E.E. Strehler and D.A. Zacharias. 2001. Role of alternative splicing in generating isoform diversity among plasma
membrane calcium pumps Physiol. Rev. 81: 21-50. (PubMed)
B.R. Graveley. 2001. Alternative splicing: Increasing diversity in the proteomic world Trends Genet. 17: 100-107.
(PubMed)
A. Newman. 1998. RNA splicing Curr. Biol. 8: R903-R905. (PubMed)
R. Reed. 2000. Mechanisms of fidelity in pre-mRNA splicing Curr. Opin. Cell Biol. 12: 340-345. (PubMed)
J.E. Sleeman and A.I. Lamond. 1999. Nuclear organization of pre-mRNA splicing factors Curr. Opin. Cell Biol. 11: 372-
377. (PubMed)
D.L. Black. 2000. Protein diversity from alternative splicing: A challenge for bioinformatics and post-genome biology
Cell 103: 367-370. (PubMed)
C.A. Collins and C. Guthrie. 2000. The question remains: Is the spliceosome a ribozyme? Nat. Struct. Biol. 7: 850-854.
(PubMed)
Self-splicing and RNA catalysis
C. Carola and F. Eckstein. 1999. Nucleic acid enzymes Curr. Opin. Chem. Biol. 3: 274-283. (PubMed)
E.A. Doherty and J.A. Doudna. 2000. Ribozyme structures and mechanisms Annu. Rev. Biochem. 69: 597-615.
(PubMed)
M.J. Fedor. 2000. Structure and function of the hairpin ribozyme J. Mol. Biol. 297: 269-291. (PubMed)
R. Hanna and J.A. Doudna. 2000. Metal ions in ribozyme folding and catalysis Curr. Opin. Chem. Biol. 4: 166-170.
(PubMed)
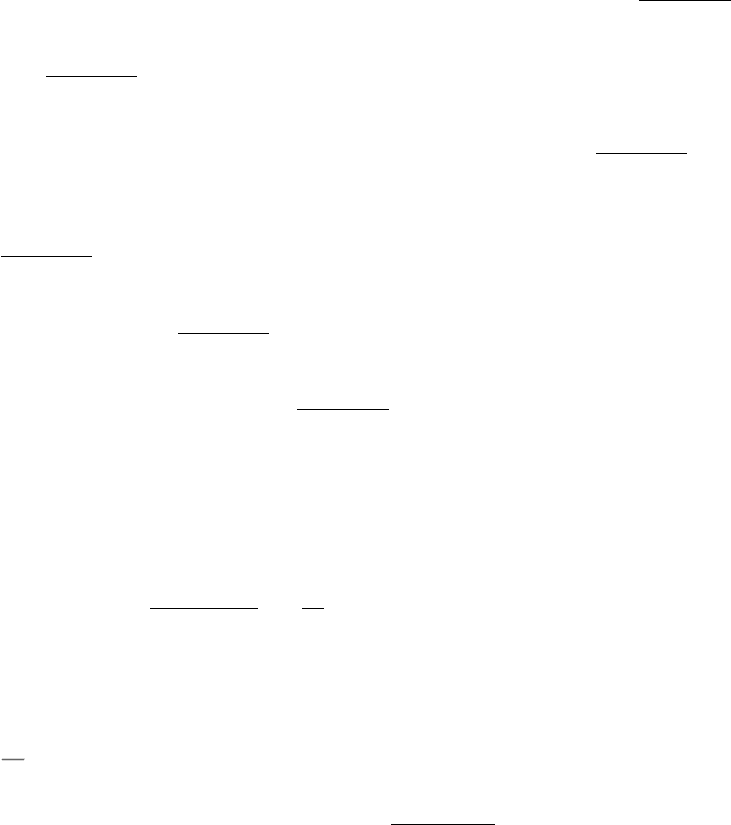
W.G. Scott. 1998. RNA catalysis Curr. Opin. Struct. Biol. 8: 720-726. (PubMed)
W.G. Scott and A. Klug. 1996. Ribozymes: Structure and mechanism in RNA catalysis Trends Biochem. Sci. 21: 220-
224. (PubMed)
T.R. Cech, D. Herschlag, J.A. Piccirilli, and A.M. Pyle. 1992. RNA catalysis by a group I ribozyme: Developing a model
for transition state stabilization J. Biol. Chem. 267: 17479-17482. (PubMed)
D. Herschlag and T.R. Cech. 1990. Catalysis of RNA cleavage by the Tetrahymena thermophila ribozyme 1: Kinetic
description of the reaction of an RNA substrate complementary to the active site Biochemistry 29: 10159-10171.
(PubMed)
J.A. Piccirilli, J.S. Vyle, M.H. Caruthers, and T.R. Cech. 1993. Metal ion catalysis in the Tetrahymena ribozyme reaction
Nature 361: 85-88. (PubMed)
J.F. Wang, W.D. Downs, and T.R. Cech. 1993. Movement of the guide sequence during RNA catalysis by a group I
ribozyme Science 260: 504-508. (PubMed)
III. Synthesizing the Molecules of Life
29. Protein Synthesis
Genetic information is most important because of the proteins that it encodes, in that proteins play most of the functional
roles in cells. In Chapters 27 and 28, we examined how DNA is replicated and how DNA is transcribed into RNA. We
now turn to the mechanism of protein synthesis, a process called translation because the four-letter alphabet of nucleic
acids is translated into the entirely different twenty-letter alphabet of proteins. Translation is a conceptually more
complex process than either replication or transcription, both of which take place within the framework of a common
base-pairing language. Befitting its position linking the nucleic acid and protein languages, the process of protein
synthesis depends critically on both nucleic acid and protein factors. Protein synthesis takes place on ribosomes
enormous complexes containing three large RNA molecules and more than 50 proteins. One of the great triumphs in
biochemistry in recent years has been the determination of the structure of the ribosome and its components so that its
function can be examined in atomic detail (Figure 29.1). Perhaps the most significant conclusion from these studies is
that the ribosome is a ribozyme; that is, the RNA components play the most fundamental roles. These observations
strongly support the notion that the ribosome is a surviving inhabitant of the RNA world. As such, the ribosome is rich in
information regarding very early steps in evolution.
Transfer RNA molecules (tRNAs), messenger RNA, and many proteins participate in protein synthesis along with
ribosomes. The link between amino acids and nucleic acids is first made by enzymes called aminoacyl-tRNA
synthetases. By specifically linking a particular amino acid to each tRNA, these enzymes implement the genetic code.
This chapter focuses primarily on protein synthesis in prokaryotes because it illustrates many general principles and is
relatively well understood. Some distinctive features of protein synthesis in eukaryotes also are presented.
III. Synthesizing the Molecules of Life 29. Protein Synthesis
Figure 29.1. Ribosome Structure.
The structure of a part of the ribosome showing the site at which peptide-bond
formation takes place. This site contains only RNA (shown in yellow), with no protein (red) within 20 Å.
III. Synthesizing the Molecules of Life 29. Protein Synthesis
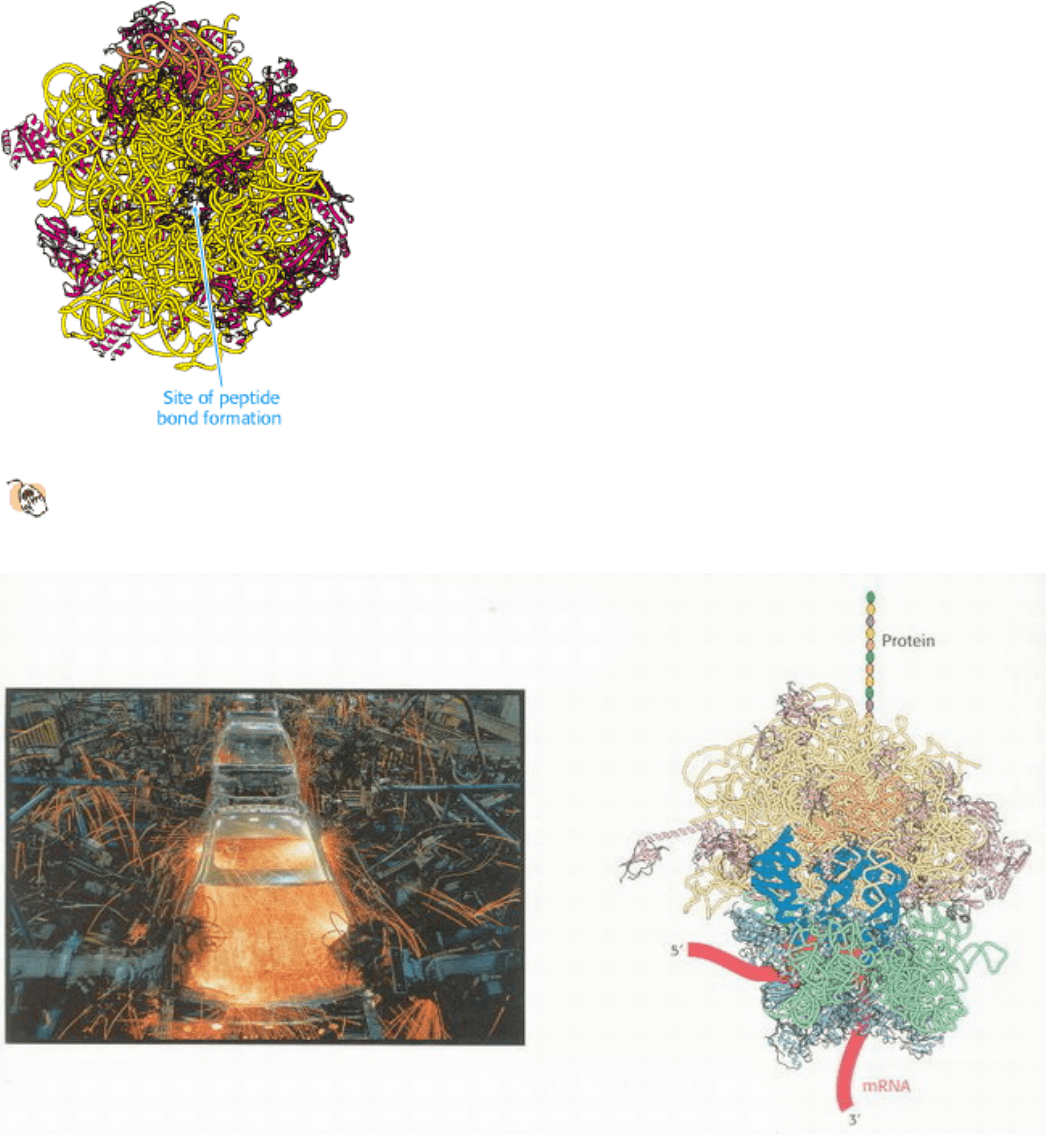
Protein Assembly. The ribosome, shown at the right, is a factory for the manufacture of polypeptides. Amino acids are
carried into the ribosome, one at a time, connected to transfer RNA molecules (blue). Each amino acid is joined to the
growing polypeptide chain, which detaches from the ribosome only once it is completed. This assembly line approach
allows even very long polypeptide chains to be assembled rapidly and with impressive accuracy. [(Left) Doug Martin/
Photo Researchers.]

III. Synthesizing the Molecules of Life 29. Protein Synthesis
29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino
Acid Sequences
The basics of protein synthesis are the same across all kingdoms of life, attesting to the fact that the protein-synthesis
system arose very early in evolution. A protein is synthesized in the amino-to-carboxyl direction by the sequential
addition of amino acids to the carboxyl end of the growing peptide chain (Figure 29.2). The amino acids arrive at the
growing chain in activated form as aminoacyl-tRNAs, created by joining the carboxyl group of an amino acid to the 3
end of a transfer RNA molecule. The linking of an amino acid to its corresponding tRNA is catalyzed by an aminoacyl-
tRNA synthetase. ATP cleavage drives this activation reaction. For each amino acid, there is usually one activating
enzyme and at least one kind of tRNA.
29.1.1. The Synthesis of Long Proteins Requires a Low Error Frequency
The process of transcription is analogous to copying, word for word, a page from a book. There is no change of alphabet
or vocabulary; so the likelihood of a change in meaning is small. Translating the base sequence of an mRNA molecule
into a sequence of amino acids is similar to translating the page of a book into another language. Translation is a
complex process, entailing many steps and dozens of molecules. The potential for error exists at each step. The
complexity of translation creates a conflict between two requirements: the process must be not only accurate, but also
fast enough to meet a cell's needs. How fast is "fast enough"? In E.coli, translation takes place at a rate of 40 amino acids
per second, a truly impressive speed considering the complexity of the process.
How accurate must protein synthesis be? Let us consider error rates. The probability p of forming a protein with no
errors depends on n, the number of amino acid residues, and ε, the frequency of insertion of a wrong amino acid:
As Table 29.1 shows, an error frequency of 10
-2
would be intolerable, even for quite small proteins. An ε value of 10
-3
would usually lead to the error-free synthesis of a 300-residue protein (~33 kd) but not of a 1000-residue protein (~110
kd). Thus, the error frequency must not exceed approximately 10
-4
to produce the larger proteins effectively. Lower error
frequencies are conceivable; however, except for the largest proteins, they will not dramatically increase the percentage
of proteins with accurate sequences. In addition, such lower error rates are likely to be possible only by a reduction in the
rate of protein synthesis because additional time for proofreading will be required. In fact, the observed values of ε are
close to 10
-
4
. An error frequency of about 10
-4
per amino acid residue was selected in the course of evolution to
accurately produce proteins consisting of as many as 1000 amino acids while maintaining a remarkably rapid rate for
protein synthesis.
29.1.2. Transfer RNA Molecules Have a Common Design
The fidelity of protein synthesis requires the accurate recognition of three-base codons on messenger RNA. Recall that
the genetic code relates each amino acid to a three-letter codon (Section 5.5.1). An amino acid cannot itself recognize a
codon. Consequently, an amino acid is attached to a specific tRNA molecule that can recognize the codon by Watson-
Crick base pairing. Transfer RNA serves as the adapter molecule that binds to a specific codon and brings with it an
amino acid for incorporation into the polypeptide chain.
Robert Holley first determined the base sequence of a tRNA molecule in 1965, as the culmination of 7 years of effort.
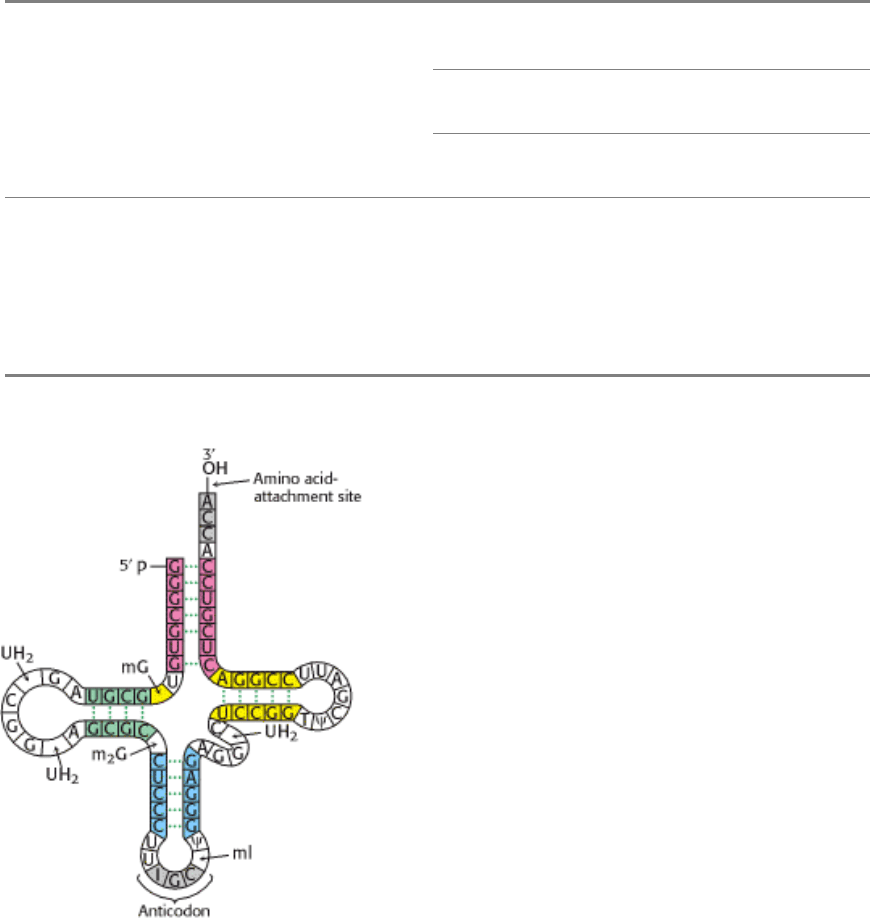
Indeed, his study of yeast alanyl-tRNA provided the first complete sequence of any nucleic acid. This adapter molecule
is a single chain of 76 ribonucleotides (Figure 29.3). The 5 terminus is phosphorylated (pG), whereas the 3 terminus has
a free hydroxyl group. The amino acid attachment site is the 3
-hydroxyl group of the adenosine residue at the 3
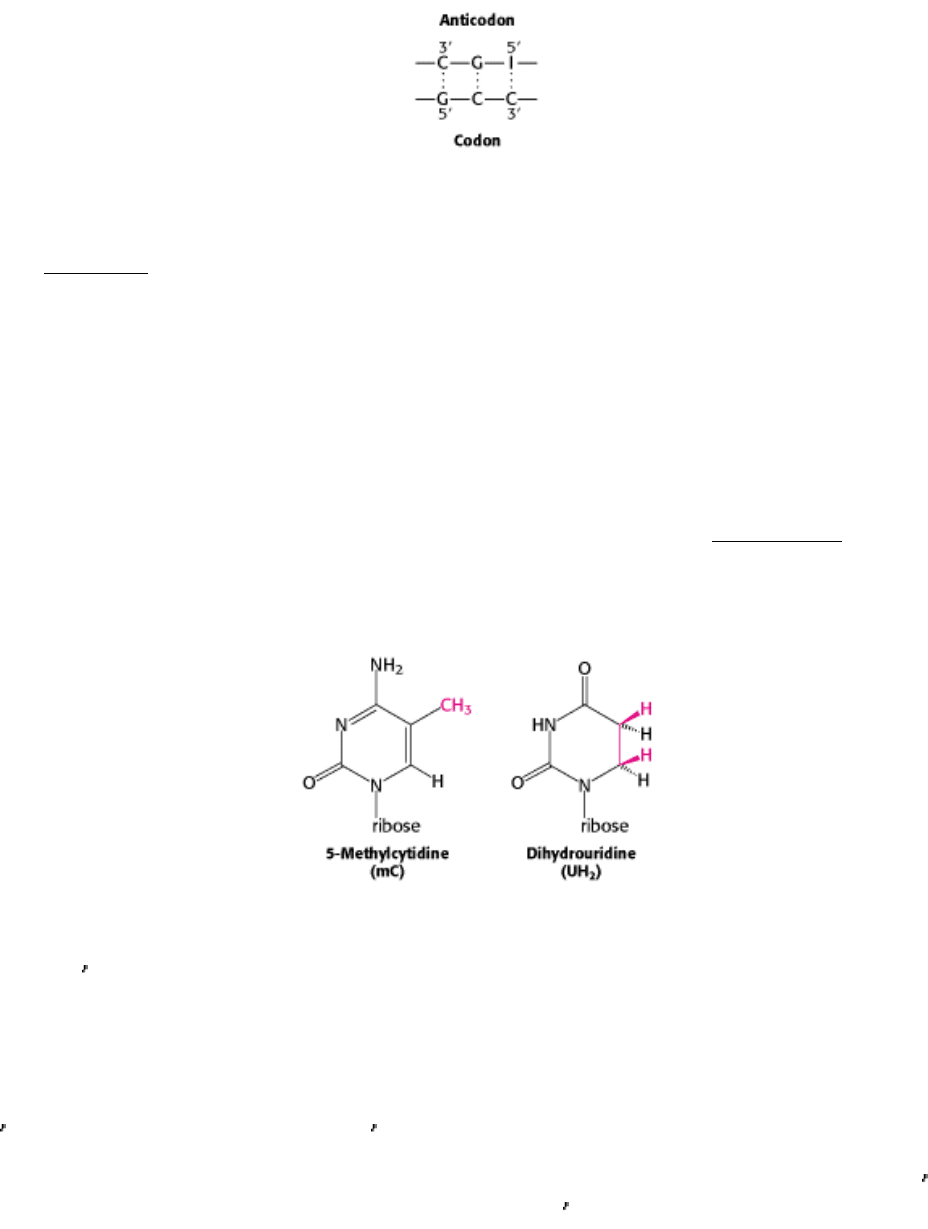
terminus of the molecule. The sequence IGC in the middle of the molecule is the anticodon. It is complementary to
GCC, one of the codons for alanine.
The sequences of several other tRNA molecules were determined a short time later. Hundreds of sequences are now
known. The striking finding is that all of them can be arranged in a cloverleaf pattern in which about half the residues are
base-paired (Figure 29.4). Hence, tRNA molecules have many common structural features. This finding is not
unexpected, because all tRNA molecules must be able to interact in nearly the same way with the ribosomes, mRNAs,
and protein factors that participate in translation.
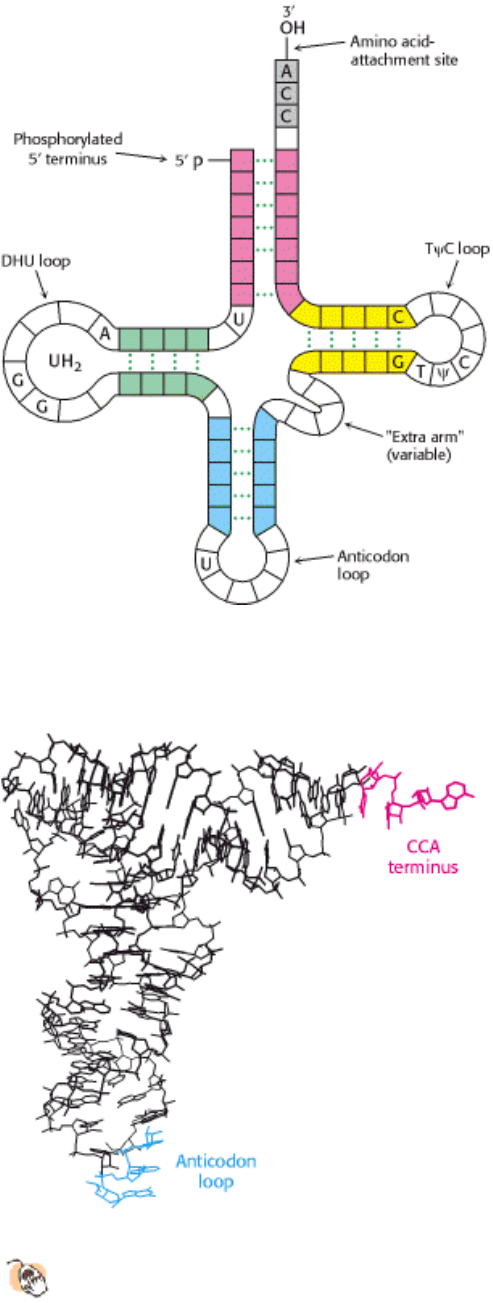
All known transfer RNA molecules have the following features:
1. Each is a single chain containing between 73 and 93 ribonucleotides (~25 kd).
2. They contain many unusual bases, typically between 7 and 15 per molecule. Some are methylated or dimethylated
derivatives of A, U, C, and G formed by enzymatic modification of a precursor tRNA (Section 28.1.8). Methylation
prevents the formation of certain base pairs, thereby rendering some of the bases accessible for other interactions. In
addition, methylation imparts a hydrophobic character to some regions of tRNAs, which may be important for their
interaction with synthetases and ribosomal proteins. Other modifications alter codon recognition, as will be discussed
shortly.
3. About half the nucleotides in tRNAs are base-paired to form double helices. Five groups of bases are not base paired
in this way: the 3 CCA terminal region, which is part of a region called the acceptor stem; the TψC loop, which
acquired its name from the sequence ribothymine-pseudouracil-cytosine; the "extra arm," which contains a variable
number of residues; the DHU loop, which contains several dihydrouracil residues; and the anticodon loop. The structural
diversity generated by this combination of helices and loops containing modified bases ensures that the tRNAs can be
uniquely distinguished, though structurally similar overall.
4. The 5 end of a tRNA is phosphorylated. The 5 terminal residue is usually pG.
5. The activated amino acid is attached to a hydroxyl group of the adenosine residue located at the end of the 3 CCA
component of the acceptor stem. This region is single stranded at the 3
end of mature rRNAs.
6. The anticodon is present in a loop near the center of the sequence.
29.1.3. The Activated Amino Acid and the Anticodon of tRNA Are at Opposite Ends of
the L-Shaped Molecule
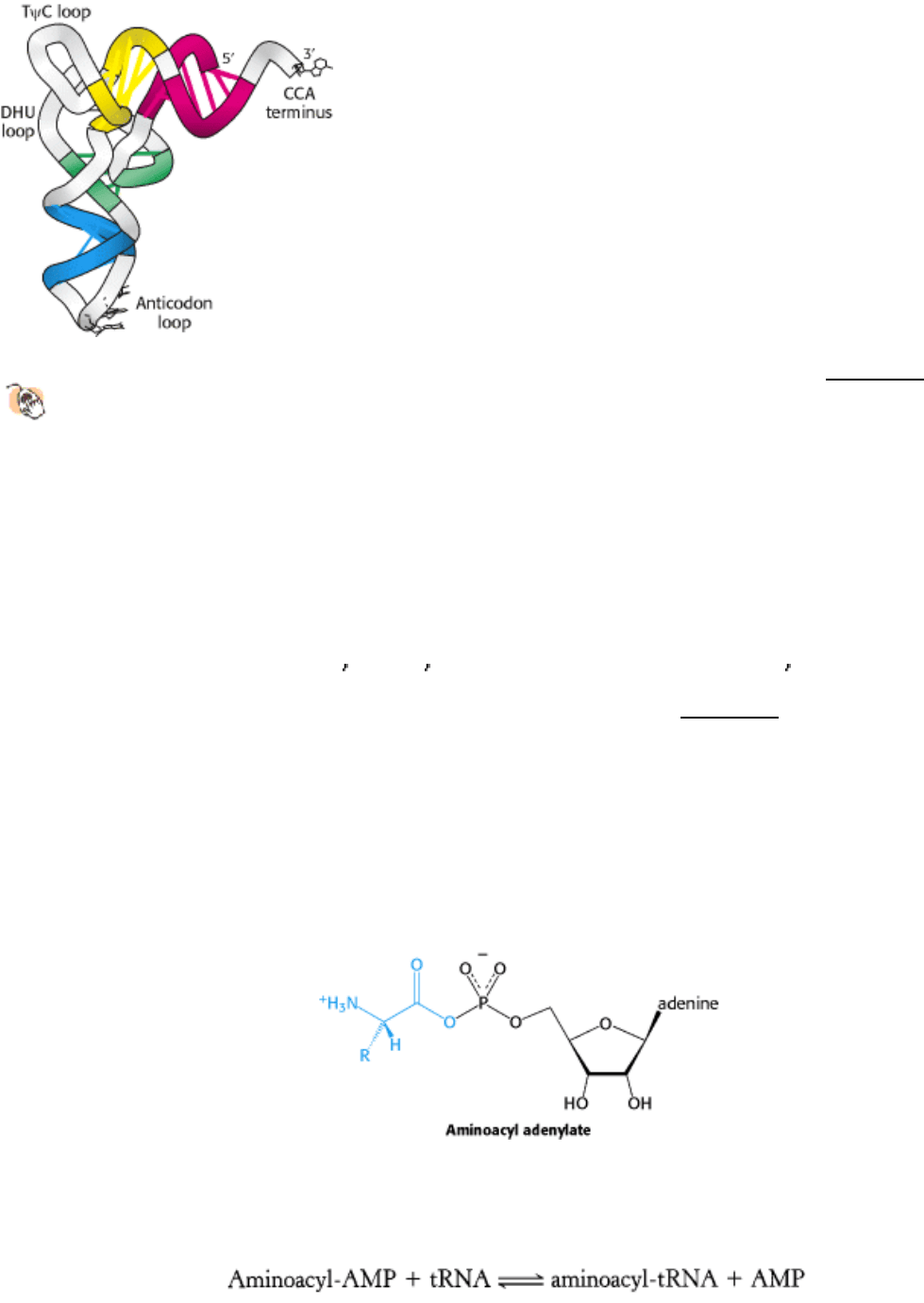
The three-dimensional structure of a tRNA molecule was first determined in 1974 through x-ray crystallographic studies
carried out in the laboratories of Alexander Rich and Aaron Klug. The structure determined, that of yeast phenylalanyl-
tRNA, is highly similar to all structures subsequently determined for other tRNA molecules. The most important
properties of the tRNA structure are:
1. The molecule is L-shaped (Figure 29.5).
2. There are two apparently continuous segments of double helix. These segments are like A-form DNA, as expected for
an RNA helix (Section 27.1.1). The base-pairing predicted from the sequence analysis is correct. The helix containing
the 5 and 3 ends stacks on top of the helix that ends in the TψC loop to form one arm of the L; the remaining two
helices stack to form the other (Figure 29.6).
3. Most of the bases in the nonhelical regions participate in hydrogenbonding interactions, even if the interactions are not
like those in Watson-Crick base pairs.
4. The CCA terminus containing the amino acid attachment site extends from one end of the L. This single-stranded
region can change conformation during amino acid activation and protein synthesis.
5. The anticodon loop is at the other end of the L, making accessible the three bases that make up the anticodon.
Thus, the architecture of the tRNA molecule is well suited to its role as adaptor; the anticodon is available to interact
with an appropriate codon on mRNA while the end that is linked to an activated amino acid is well positioned to
participate in peptide-bond formation.
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Figure 29.2. Polypeptide-Chain Growth. Proteins are synthesized by the successive addition of amino acids to the
carboxyl terminus.
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Table 29.1. Accuracy of protein synthesis
Probability of synthesizing an error-free protein
Number of amino acid residues
Frequency of inserting an incorrect amino acid 100 300 1000
10
-2
0.366 0.049 0.000
10
-3
0.905 0.741 0.368
10
-4
0.990 0.970 0.905
10
-5
0.999 0.997 0.990
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Figure 29.3. Alanine-tRNA Sequence. The base sequence of yeast alanyl-tRNA and the deduced cloverleaf secondary
structure are shown. Modified nucleosides are abbreviated as follows: methylinosine (mI), dihydrouridine (UH
2
),
ribothymidine (T), pseudouridine (Ψ), methylguanosine (mG), and dimethylguanosine (m
2
G). Inosine (I), another
modified nucleoside, is part of the anticodon.
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Figure 29.4. General Structure of tRNA Molecules. Comparison of the base sequences of many tRNAs reveals a
number of conserved features.
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Figure 29.5. L-Shaped tRNA Structure.
A skeletal model of yeast phenylalanyl-tRNA reveals the L-shaped structure.
The CCA region is at the end of one arm, and the anticodon loop is at the end of the other.
III. Synthesizing the Molecules of Life 29. Protein Synthesis 29.1. Protein Synthesis Requires the Translation of Nucleotide Sequences Into Amino Acid Sequences
Figure 29.6. Helix Stacking in tRNA.
The four helices of the secondary structure of tRNA (see Figure 29.4) stack to
form an L-shaped structure.
III. Synthesizing the Molecules of Life 29. Protein Synthesis
29.2. Aminoacyl-Transfer RNA Synthetases Read the Genetic Code
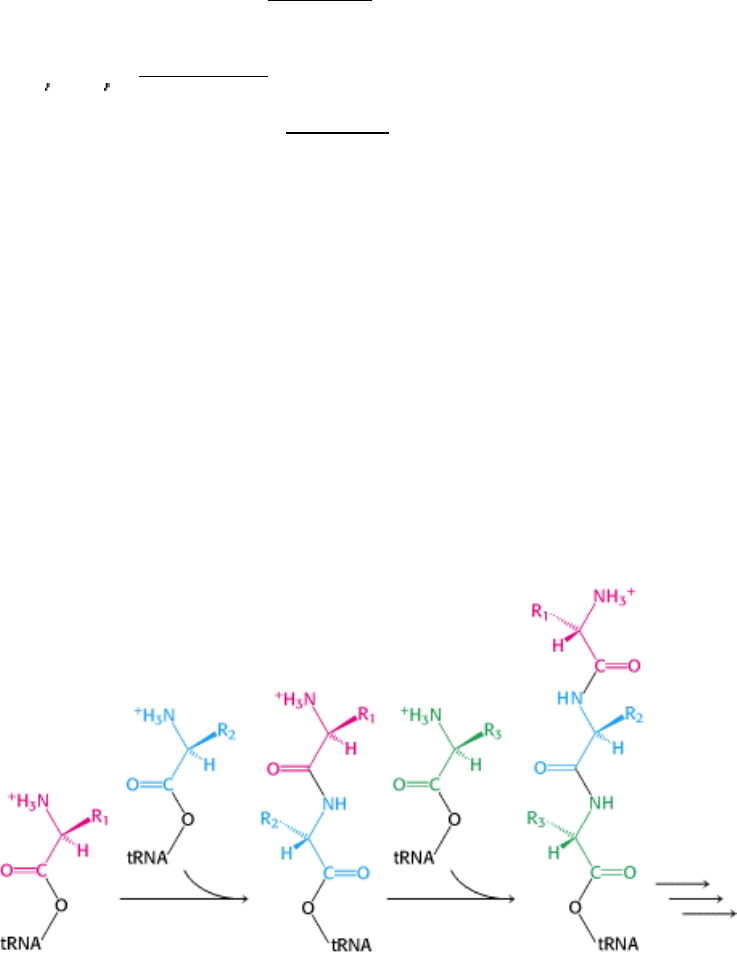
The linkage of an amino acid to a tRNA is crucial for two reasons. First, the attachment of a given amino acid to a
particular tRNA establishes the genetic code. When an amino acid has been linked to a tRNA, it will be incorporated
into a growing polypeptide chain at a position dictated by the anticodon of the tRNA. Second, the formation of a peptide
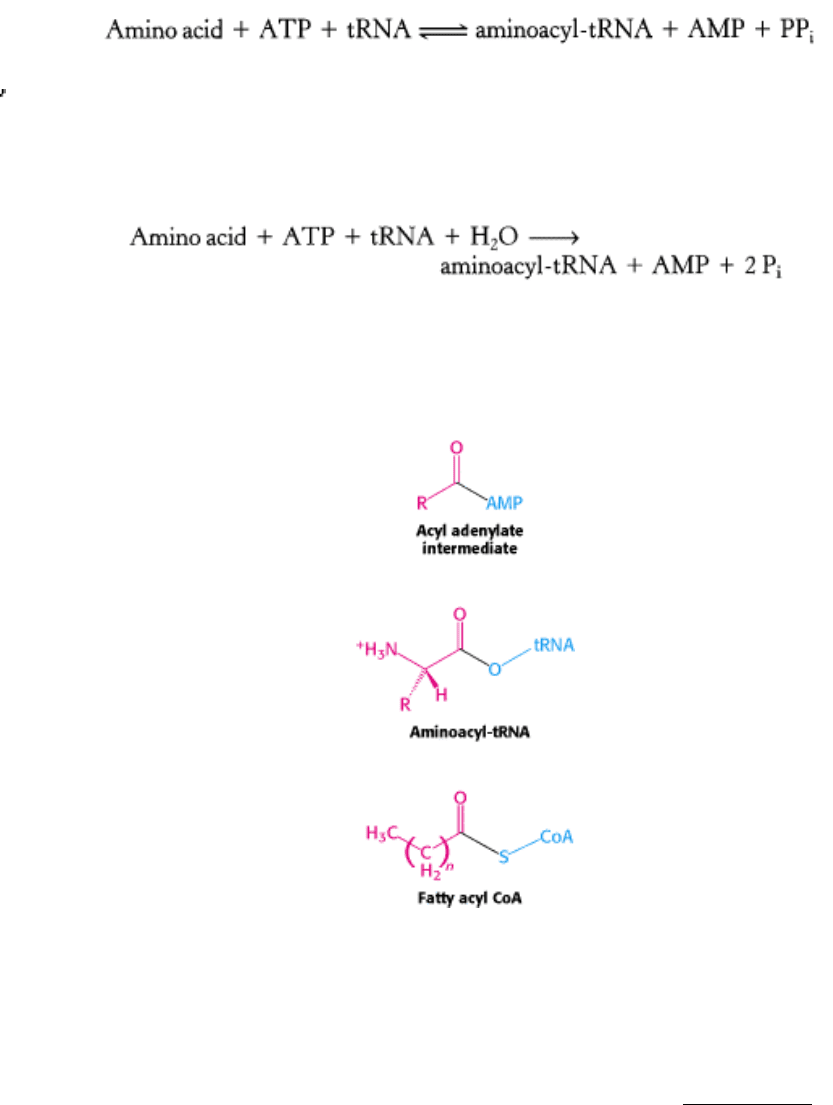
bond between free amino acids is not thermodynamically favorable. The amino acid must first be activated for protein
synthesis to proceed. The activated intermediates in protein synthesis are amino acid esters, in which the carboxyl group
of an amino acid is linked to either the 2
- or the 3 -hydroxyl group of the ribose unit at the 3 end of tRNA. An amino
acid ester of tRNA is called an aminoacyl-tRNA or sometimes a charged tRNA (Figure 29.7).
29.2.1. Amino Acids Are First Activated by Adenylation
The activation reaction is catalyzed by specific aminoacyl-tRNA synthetases, which are also called activating enzymes.
The first step is the formation of an aminoacyl adenylate from an amino acid and ATP. This activated species is a mixed
anhydride in which the carboxyl group of the amino acid is linked to the phosphoryl group of AMP; hence, it is also
known as aminoacyl-AMP.
The next step is the transfer of the aminoacyl group of aminoacyl-AMP to a particular tRNA molecule to form
aminoacyl-tRNA.
The sum of these activation and transfer steps is
The ∆ G°
of this reaction is close to 0, because the free energy of hydrolysis of the ester bond of aminoacyl-tRNA is
similar to that for the hydrolysis of ATP to AMP and PP
i
. As we have seen many times, the reaction is driven by the
hydrolysis of pyrophosphate. The sum of these three reactions is highly exergonic:
Thus, the equivalent of two molecules of ATP are consumed in the synthesis of each aminoacyl-tRNA. One of them is
consumed in forming the ester linkage of aminoacyl-tRNA, whereas the other is consumed in driving the reaction
forward.
The activation and transfer steps for a particular amino acid are catalyzed by the same aminoacyl-tRNA synthetase.
Indeed, the aminoacyl-AMP intermediate does not dissociate from the synthetase. Rather, it is tightly bound to the active
site of the enzyme by noncovalent interactions. Aminoacyl-AMP is normally a transient intermediate in the synthesis of
aminoacyl-tRNA, but it is relatively stable and readily isolated if tRNA is absent from the reaction mixture.
We have already encountered an acyl adenylate intermediate in fatty acid activation (Section 22.2.2). The major
difference between these reactions is that the acceptor of the acyl group is CoA in fatty acid activation and tRNA in
amino acid activation. The energetics of these biosyntheses are very similar: both are made irreversible by the hydrolysis
of pyrophosphate.
29.2.2. Aminoacyl-tRNA Synthetases Have Highly Discriminating Amino Acid
Activation Sites
Each aminoacyl-tRNA synthetase is highly specific for a given amino acid. Indeed, a synthetase will incorporate the
incorrect amino acid only once in 10
4
or 10
5
catalytic reactions. How is this level of specificity achieved? Each
aminoacyl-tRNA synthetase takes advantage of the properties of its amino acid substrate. Let us consider the challenge