Емельянов В.Ю. Методы моделирования стохастических систем управления
Подождите немного. Документ загружается.


53
могут задаваться
i
=,
i
= или
i
=i
.
. Подробный анализ таких процес-
сов содержится, например, в [1,40].
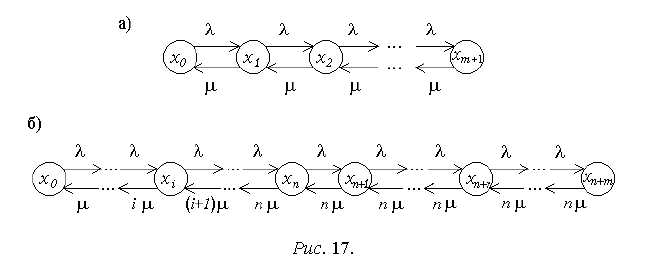
Для одноканальной и многоканальной систем массового обслуживания
(СМО) с отказами (рис. 16) номер состояния соответствует числу занятых
каналов, - интенсивность потока заявок, - производительность канала.
Для одноканальной СМО с ожиданием и ограниченной очередью дли-
ной m (рис. 17, а) состояния вводятся следующим образом: x
0
- канал свобо-
ден; x
1
- канал занят, очереди нет; x
2
- канал занят, одна заявка в очереди;
x
m+1
- канал занят, m заявок в очереди.
Для n-канальной СМО с ожиданием и ограниченной очередью дли-
ной m (рис. 17,б) состояния вводятся следующим образом: x
0
- все каналы
свободны; x
1
- занят один канал, остальные свободны; x
n
- все каналы заняты,
очереди нет; x
n+k
- все каналы заняты, k заявок в очереди; x
n+m
- все каналы и
места в очереди заняты.
Существует широкое разнообразие вариантов построения моделей
СМО (Q-схем). В них рассматриваются неоднородность потока заявок, нали-
чие последействия, параллельная работа нескольких простейших вариантов
54
СМО (рис. 16, 17) с определенной логикой распределения входного потока
заявок и др. Процессы во многих из них не могут быть описаны уравнения-
ми типа (2.19) и могут быть исследованы лишь путем имитационного моде-
лирования.
Для лучшего понимания и более подробного знакомства с рассмотрен-
ной темой рекомендуются книги [9,40].
2.6. Алгоритмы реализации моделей
Помимо физического облика модели и положенной в ее основу мате-
матической схемы, важное значение для обеспечения наилучшего соотно-
шения ее точности и трудоемкости имеет выбор алгоритма ее реализации,
особенно для стохастических систем.
Задача определения любого показателя качества стохастической систе-
мы, как правило, сводится к оценке среднего значения (математического
ожидания) некоторой характеристики ее функционирования. При этом, оч е-
видно, имеется в виду многократное применение системы или наблюдение
ее работы на достаточно продолжительном интервале времени. Минимиза-
ция необходимого объема моделирования обеспечивается рациональным
выбором алгоритма реализации модели.
Для математических моделей в ряде случаев на основе методов линей-
ной алгебры, статистической линеаризации, преобразований Фурье, Лапласа
и других результат удается получить в аналитическом виде. Примеры анали-
тических моделей:
1. Модели для расчета средних характеристик стационарных случайных
процессов в системах управления на основе спектрального метода.
55
2. Модели СМО для установивших режимов, обеспечивающие опреде-
ление характеристик их пропускной способности путем решения систем
линейных алгебраических уравнений.
3. Модели для расчета характеристик нестационарных случайных про-
цессов в динамических системах по на основе методов “динамики средних”
или весовых функций.
Оценка искомых показателей качества на основе аналитических моделей
обычно сводится к решению некоторых систем, чаще всего алгебраических,
уравнений или вычислению определенных интегралов. В наиболее сложных
случаях приходится применять приближенные численные методы, реализуе-
мые на ЦВМ. Несмотря на это, аналитические модели характеризуются ми-
нимальной трудоемкостью.
Для математических моделей стохастических систем, не допускающих
аналитических преобразований, а также для физических, полунатурных и
других моделей, возможны два подхода к построению алгоритмов реализа-
ции.
Это, во-первых, статистическое имитационное моделирование - много-
кратное воспроизведение процесса в системе с накоплением и последующей
обработкой статистических данных о значениях ее характеристик. Такой под-
ход пригоден для моделей любой физической природы и любых математиче-
ских схем. Главный его недостаток - повышение точности связано со значи-
тельным увеличением количества опытов.
Во-вторых, использование специальных методов рациональной органи-
зации эксперимента с целенаправленным выбором параметров моделируе-
мой ситуации. К ним относятся, например, метод эквивалентных возмуще-
ний, интерполяционный метод Чернецкого, методы планирования экспери-
мента, нестохастического имитационного моделирования [2, 13, 16, 31, 32, 38,
45].
3. МЕТОД СТАТИСТИЧЕСКОГО МОДЕЛИРОВАНИЯ
Метод статистического моделирования, называемый также методом ста-
тистических испытаний или методом Монте-Карло, является универсальным
методом исследования стохастических систем и процессов. Он свободен от
каких-либо теоретических ограничений и одинаково пригоден для моделей
любой физической природы. Данный метод оказывается полезным также для
решения ряда детерминированных задач, требующих сложных вычислений.
Термином "метод Монте-Карло" обычно принято обозначать решение де-

56
терминированной вычислительной задачи путем определения статистических
характеристик искусственно организованного случайного процесса.
3.1. Теоретические основы метода статистического моделирования
Метод статистического моделирования в целом базируется на положе-
ниях и результатах теории вероятностей и математической статистики [10, 15,
20, 35]. Рассмотрим ряд основных понятий и теорем, называемых пр едель-
ными и объединяемых обычно общим названием - закон больших чисел, на
которых основаны центральные идеи метода статистического моделирова-
ния.
В рамках закона больших чисел используется понятие предела по вероят-
ности, отличающееся от обычного понятия предела, рассматриваем ого в
дифференциальном исчислении, и определяемое следующим образом.
Последовательность случайных величин {y
n
} = y
1
,y
2
,…,y
n
,… сходится
по вероятности к случайной величине y, если вероятность того, что y
n
отлича-
ется от y на любое конечное число, стремится к нулю при неограниченном
увеличении n:
yy
n
вер
при n→∞, если
0lim
n
n
yyP
для любого >0.
Решение любой задачи статистического моделирования сводится к ус-
реднению результатов некоторой последовательности, или совокупности,
опытов. Итоговые результаты определяются в виде вероятностей, моментов
или законов распределения. Обычно принято рассматривать в качестве ос-
новных две задачи: определение вероятности случайного события в рамках
схемы Бернулли и определение математического ожидания случайной вели-
чины.
Схема Бернулли состоит в проведении независимых опытов в однород-
ных условиях, в результате каждого из которых может быть зафиксировано
или не зафиксировано наступление некоторого события A. Событие A явля-
ется случайным, то есть существует, но неизвестна его вероятность
P(А)=p
А
.
Если проведены n опытов по схеме Бернулли, и в n
А
из них событие A
зафиксировано, то отношение
n
А
n
h
n
(3.1)
называется относительной частотой появления события A.

57
Теорема Бернулли: последовательность относительных частот появления
события A в n независимых опытах сходится по вероятности к истинной p
А
при n→∞.
При определении математического ожидания также должны обеспечи-
ваться независимость опытов и однородность условий их проведения. При
соблюдении таких условий результаты отдельных опытов рассматриваются
как последовательность {x
n
}=x
1
,x
2
,…,x
n
,… независимых случайных ве-
личин, имеющих один и тот же закон распределения вероятностей. Если про-
ведены n таких опытов, вводится новая случайная величина
.
1
1
21
_
n
i
i
n
n
x
nn
xxx
x
(3.2)
Теорема Хинчина: если x
1
,x
2
,… – последовательность независимых
случайных величин, имеющих один и тот же закон распределения с конечным
математическим ожиданием m
x
, то последовательность средних арифметиче-
ских
n
x
_
(n = 1,2,...) сходится по вероятности к m
x
.
Существуют также другие формулировки указанных положений закона
больших чисел. Например, усиленный закон больших чисел в форме Колмо-
горова: для того чтобы среднее арифметическое независимых реализаций
случайной величины сходилось с вероятностью, равной единице, к ее матема-
тическому ожиданию, необходимо и достаточно, чтобы это математическое
ожидание существовало.
Отметим, что указанное свойство относится как к непрерывным, так и к
дискретным случайным величинам, составляющим последовательность {x
n
}.
Причем для дискретной случайной величины математическое ожидание и
среднее арифметическое могут рассматриваться как непрерывные величины.
В этом смысле результаты отдельных опытов по схеме Бернулли могут трак-
товаться как независимые реализации дискретной случайной величины x с
двумя возможными значениями 0 и 1. Среднее арифметическое n таких реа-
лизаций совпадет с относительной частотой (3.1). Подобным образом любая
другая задача статистического моделирования может быть сведена к задаче
определения математического ожидания.
Независимо от вида приведенные положения закона больших чисел вы-
ражают основную идею метода статистического моделирования: наблюдение
большого числа реализаций случайной величины позволяет сделать правиль-
ные выводы о ее средних характеристиках. Однако для решения практических
задач принципиального обоснования возможности получения результата за
58
счет неограниченного увеличения количества опытов недостаточно. Необхо-
димо иметь возможность определения требуемого количества опытов и оцен-
ки погрешности получаемого результата. Рассмотрим еще ряд положений и
предельных теорем теории вероятностей.
Важную роль в расчетных соотношениях метода статистического моде-
лирования играет одномерный нормальный закон распределения. Нормаль-
ным называется закон распределения суммы большого числа независимых
случайных величин, каждая из которых мала по сравнению с суммой. Для
непрерывной случайной величины x, распределенной по нормальному
закону, плотность распределения вероятностей (ПРВ) описывается анали-
тическим выражением:
2
2
2
2
1
x
x
mx
x
exf
, (3.3)
где m
x
– первый начальный момент распределения, или матем атическое ожи-
дание;
x
– среднеквадратическое отклонение,
xx
D
; D
x
– второй цен-
тральный момент распределения, или дисперсия. Нормальный закон распр е-
деления (3.3) полностью задается парой чисел m
x
и
x
или m
x
и D
x
.
Стандартизованным нормальным распределением называется нормаль-
ное распределение некоторой случайной величины u с нулевым математиче-
ским ожиданием и единичной дисперсией:
.
2
1
2
2
u
euf
(3.4)
Связь любой случайной величины x с нормальным законом распределе-
ния и стандартизованной нормальной случайной величины u выражается
следующими соотношениями:
x
x
mx
u
, x=m
x
+u
x
. (3.5)
Случайная величина y имеет асимптотически нормальный закон распре-
деления, если существует последовательность пар действительных чисел (m
n
,
n
), таких, что последовательность случайных величин, получаемых для от-
дельных реализаций y
n
по соотношению
,
n
nn
n
my
x

59
при n→∞, сходится по вероятности к стандартизованной нормальной слу-
чайной величине.
Одна из предельных теорем теории вероятностей гласит, что последова-
тельность относительных частот в схеме Бернулли h
n
имеет асимптотически
нормальное распределение с математическим ожиданием
А
pm
n
h
и дис-
персией
n
pp
D
nn
hh
АА
1
2
. (3.6)
В соответствии с центральной предельной теоремой последовательность
случайных величин, определяемых по (3.2), имеет асимптотичеcки нормаль-
ное распределение с математическим ожиданием, равным матем атическому
ожиданию исходной последовательности независимых случайных вели-
чин,
n
n
x
x
mm
_
и дисперсией:
n
D
n
nn
x
xx
2
2
__
, (3.7)
если только математическое ожидание
n
x
m
и дисперсия
2
n
x
существуют.
Эти две теоремы являются основой для оценки погрешностей статисти-
ческого моделирования. При этом следует иметь в виду, что понятия предела
по вероятности, асимптотически нормального распределения и все предель-
ные теоремы в строгом смысле справедливы только для бесконечного числа
опытов n. При любом реализованном на практике конечном n любое из при-
веденных выше соотношений может не подтвердиться с вероятностью, отлич-
ной от нуля.
3.2. Понятие оценки. Свойства оценок
Совокупность значений случайной величины x
1
,x
2
,…,x
n
полученных
при n независимых опытах в однородных условиях, называется случайной
выборкой. Закон распределения такой ограниченной по объему совокупно-
сти значений исследуемой случайной величины x называется выборочным
законом распределения.
Выборка бесконечного объема, распределение которой совпадает с ис-
тинным законом распределения исследуемой случайной величины x, называ-
ется генеральной совокупностью.
60
Таким образом, если будут выполнены различные серии опытов с реги-
страцией случайных значений, или реализаций, величины x, будут получены
несколько случайных выборок, выступающих как часть одной и той же гене-
ральной совокупности. Каждой из этих выборок будет соответствовать свой
выборочный закон распределения, являющийся некоторым приближением
истинного закона.
Можно выделить два основных вида задач обработки случайных выбо-
рок:
- получение выборочного закона распределения;
- определение некоторых оценок, то есть приближений моментов или па-
раметров истинного закона распределения.
Статистикой называется некоторая функция, определенная на выбор-
ке, y
n
=y(x
1
,x
2
,…,x
n
), значение которой может быть предсказано с суще-
ственно более высокой точностью, чем значение случайной величины, обр а-
зующей выборку [20].
Поясним суть такого свойства, называемого статистической устойчи-
востью, на примере.
Пусть получена выборка значений случайной величины x объемом
n=10: 1,2; 1,8; 2,2; 2,5; 2,1; 1,9; 1,8; 1,5; 1,3; 2,4.
Найдем: среднее арифметическое
87,1
10
_
x
и вероятность того, что на-
блюдаемое значение x оказывается большим 2, p
А
=P(x>2)=0,4.
Если на основе имеющейся выборки попытаться предсказать значения,
которые примут случайные величины x,
_
x
и p
А
после проведения дополни-
тельного 11-го опыта, то можно сделать следующие предположения:
1,2≤x≤2,5; 1,81≤
_
x
≤1,93; 0,36≤p
А
≤0,45.
Очевидно, при больших n прогнозируемые диапазоны для
_
x
и p
А
ока-
жутся значительно более узкими, в отличие от x. Таким образом, они действи-
тельно обладают статистической устойчивостью и могут использоваться как
статистики.
Выбор той или иной статистики в качестве оценки искомой величины в
конкретной задаче не всегда однозначен. Помимо статистической устойчиво-
сти, к оценке предъявляются следующие требования:
1. Состоятельность – оценка должна сходиться по вероятности к
оцениваемой величине. Для этого достаточно, чтобы предел дисперсии оцен-
ки был равен нулю при n→∞.
61
2. Эффективность – оценка должна иметь минимальную дисперсию
среди всех статистик, которые можно построить для определения искомой
величины.
3. Несмещенность – математическое ожидание оценки должно совпадать
с истинным математическим ожиданием оцениваемой величины.
4. Достаточность – оценка должна использовать всю информацию, со-
держащуюся в выборке.
Последними двумя требованиями иногда пренебрегают в пользу стати-
стической устойчивости и эффективности или для простоты вычислений.
Примеры оценок:
1. Оценка вероятности случайного события – относительная частота (3.1)
– отвечает всем указанным требованиям: p
A
*
= h
n
.
2. Оценка математического ожидания – выборочное среднее (3.2) – яв-
ляется состоятельной, несмещенной, достаточной и при условии конечности
дисперсии оцениваемой величины эффективной:
n
x
xm
_
.
3. Для нахождения дисперсии случайной величины x может быть по-
строена статистика, непосредственно соответствующая определению диспер-
сии и называемая выборочным стандартным отклонением:
n
i
n
i
xx
n
s
1
2
_
2
1
, (3.8)
где x
i
- значения реализаций x, образующих выборку;
n
x
_
- выборочное сред-
нее. Однако такая статистика, удовлетворяя остальным требованиям, для ко-
нечной выборки оказывается смещенной.
Несмещенная оценка дисперсии выглядит следующим образом:
.
1
1
1
2
_
n
i
n
ix
xx
n
D
(3.9)
Нетрудно убедиться, что при n>50 смещение статистики (3.8) оказывается
незначительным и ее также можно использовать для оценки дисперсии.
4. Оценка корреляционного момента связи двух случайных величин x и y,
удовлетворяющая всем указанным выше требованиям:
n
i
n
i
n
ixy
yyxx
n
K
1
__
1
1
. (3.10)

62
5. Оценки математического ожидания m
и корреляционной функции
K
() стационарного эргодического случайного процесса () могут быть
получены по случайной выборке, образованной n последовательными изме-
рениями одной реализации процесса
i
n
с шагом t:
n
i
i
n
m
1
1
, (3.11)
jn
i
jii
mm
jn
K
0
1
1
, (3.12)
где
i
(it), jt.
Оценка (3.11) удовлетворяет всем указанным выше требованиям, а оцен-
ка (3.12), не будучи несмещенной, традиционно используется при достаточно
больших n в силу простоты алгоритмической реализации.
3.3. Точность оценок и определение необходимого количества опытов
Рассмотрим задачу определения вероятности P(А)=p
А
случайного со-
бытия А на основе схемы Бернулли. В соответствии с законом больших чисел
и предельными теоремами можно принять (с достоверностью, близкой к 1),
что при достаточно больших n оценка этой вероятности p
*
А
является непре-
рывной случайной величиной, распределенной по нормальному закону со
следующими математическим ожиданием и среднеквадратическим отклоне-
нием:
АА
А
ppMm
p
,
.
1
n
pp
pD
p
АА
А
А
(3.13)
С учетом (3.13) найдем вероятность того, что при определенном n оценка
будет отличаться от истинной вероятности не более, чем на :
P(|p
*
А
– p
A
| < ∆) = P(p
A
– ∆ < p
*
А
< p
A
+ ∆) = F(p
A
+ ∆) – F(p
A
– ∆),
(3.14)
где F(x) - функция распределения вероятностей (ФРВ) случайной величины
p
*
А
. Графически вероятность (3.14) соответствует заштрихованной площади
под кривой ПРВ случайной величины p
*
А
(рис. 18).