Greene W.H. Econometric Analysis
Подождите немного. Документ загружается.


CHAPTER 18
✦
Discrete Choices and Event Counts
829
The probability density function for y|T, w is Poisson with λ(w) = exp(x
β +δT +σ
ε
w).
Combining terms,
P(y, T|w) =
exp
[
−λ(w)
][
λ(w)
]
y
y!
(2T − 1)
z
γ + ρw
1 − ρ
2
.
This last result provides the terms that enter the log-likelihood for (β, γ , δ, ρ, σ
ε
).As
before, the unobserved heterogeneity, w, must be integrated out of the log-likelihood,
so either the quadrature or simulation method discussed in Chapter 17 is used to ob-
tain the parameter estimates. Note that this model may also be estimated in two steps,
with γ obtained in the first-step probit. The two-step method will not be appreciably
simpler, since the second term in the density must remain to identify ρ. The residual
inclusion method is not fesible here since T
∗
is not observed.
This same set of methods is used to allow for endogeneity of the participation
equation in the hurdle model in Section 18.4.8. Mechanically, the hurdle model with
endogenous participation is essentially the same as the endogenous binary variable.
[See Greene (2005, 2007).]
18.5 SUMMARY AND CONCLUSIONS
The analysis of individual decisions in microeconometrics is largely about discrete de-
cisions such as whether to participate in an activity or not, whether to make a purchase
or not, or what brand of product to buy. This chapter and Chapter 17 have developed
the four essential models used in that type of analysis. Random utility, the binary choice
model, and regression-style modeling of probabilities developed in Chapter 17 are the
three fundamental building blocks of discrete choice modeling. This chapter extended
those tools into the three primary areas of choice modeling, unordered choice mod-
els, ordered choice models, and models for counts. In each case, we developed a core
modeling framework that provides the broad platform and then developed a variety of
extensions.
In the analysis of unordered choice models, such as brand or location, the multino-
mial logit (MNL) model has provided the essential starting point. The MNL works well
to provide a basic framework, but as a behavioral model in its own right, it has some
important shortcomings. Much of the recent research in this area has focused on relax-
ing these behavioral assumptions. The most recent research in this area, on the mixed
logit model, has produced broadly flexible functional forms that can match behavioral
modeling to empirical specification and estimation.
The ordered choice model is a natural extension of the binary choice setting and
also a convenient bridge between models of choice between two alternatives and more
complex models of choice among multiple alternatives. We began this analysis with the
ordered probit and logit model pioneered by Zavoina and McKelvey (1975). Recent
developments of this model have produced the same sorts of extensions to panel data
and modeling heterogeneity that we considered in Chapter 17 for binary choice. We
also examined some multiple-equation specifications. For all its versatility, the famil-
iar ordered choice models have an important shortcoming in the assumed constancy
underlying preference behind the rating scale. The current work on differential item

830
PART IV
✦
Cross Sections, Panel Data, and Microeconometrics
functioning, such as King et al. (2004), has produced significant progress on filling this
gap in the theory.
Finally, we examined probability models for counts of events. Here, the Poisson
regression model provides the broad framework for the analysis. The Poisson model
has two shortcomings that have motivated the current stream of research. Thefunctional
form binds the mean of the random variable to its variance, producing an unrealistic
regression specification. Second, the basic model has no component that accommodates
unmeasured heterogeneity. (This second feature is what produces the first.) Current
research has produced a rich variety of models for counts, such as two-part behavioral
models that account for many different aspects of the decision-making process and the
mechanisms that generate the observed data.
Key Terms and Concepts
•
Bivariate ordered probit
•
Censoring
•
Choice-based sample
•
Conditional logit
model
•
Count data
•
Deviance
•
Differential item
functioning (DIF)
•
Event count
•
Exposure
•
Full information maximum
likelihood (FIML)
•
Heterogeneity
•
Hurdle model
•
Identification through
functional form
•
Inclusive value
•
Independence from
irrelevant alternatives (IIA)
•
Lagrange multiplier test
•
Limited information
•
Log-odds
•
Loglinear model
•
Method of simulated
moments
•
Mixed logit model
•
Multinomial choice
•
Multinomial logit model
•
Multinomial probit model
(MNP)
•
Negative binomial model
•
Negbin 1 (NB1) form
•
Negbin 2 (NB2) form
•
Negbin P (NBP) model
•
Nested logit model
•
Nonnested models
•
Ordered choice model
•
Overdispersion
•
Parallel regression
assumption
•
Poisson regression model
•
Random coefficients
•
Random parameters logit
model (RPL)
•
Revealed preference data
•
Specification error
•
Stated choice experiment
•
Subjective well-being
•
Unordered choice model
•
Willingness to pay space
•
Zero inflated Poisson model
(ZIP)
Exercises
1. We are interested in the ordered probit model. Our data consist of 250 observations,
of which the responses are
y 01234
|−−−−−−−−−−−−−
n 50 40 45 80 35
Using the preceding data, obtain maximum likelihood estimates of the unknown
parameters of the model. (Hint: Consider the probabilities as the unknown param-
eters.)
2. For the zero-inflated Poisson (ZIP) model in Section 18.4.8, we derived the condi-
tional mean function, E[y
i
|x
i
, w
i
] = (1 − F
i
)λ
i
.
a. For the same model, now obtain Var [y
i
|x
i
, w
i
]. Then, obtain τ
i
= Var[y
i
|x
i
,
w
i
]/E[y
i
|x
i
, w
i
]. Does the zero inflation produce overdispersion? (That is, is the
ratio greater than one?)
b. Obtain the partial effect for a variable z
i
that appears in both w
i
and x
i
.

CHAPTER 18
✦
Discrete Choices and Event Counts
831
3. Consider estimation of a Poisson regression model for y
i
|x
i
. The data are truncated
on the left—these are on-site observations at a recreasion site, so zeros do not
appear in the data set. The data are censored on the right—any response greater
than 5 is recorded as a 5. Construct the log-likelihood for a data set drawn under
this sampling scheme.
Applications
1. Appendix Table F17.2 provides Fair’s (1978) Redbook Magazine survey on extra-
marital affairs. The variables in the data set are as follows:
id = an identification number
C = constant, value = 1
yrb = a constructed measure of time spent in extramarital affairs
v
1
= a rating of the marriage, coded 1 to 5
v
2
= age, in years, aggregated
v
3
= number of years married
v
4
= number of children, top coded at 5
v
5
= religiosity, 1 to 4, 1 = not, 4 = very
v
6
= education, coded 9, 12, 14, 16, 17, 20
v
7
= occupation
v
8
= husband’s occupation
and three other variables that are not used. The sample contains a survey of 6,366
married women. For this exercise,we will analyze, first, the binary variable A = 1if
yr b > 0,0 otherwise. The regressors of interest are v
1
to v
8
; however, not necessarily
all of them belong in your model. Use these data to build a binary choice model for
A. Report all computed results for the model. Compute the partial effects for the
variables you choose. Compare the results you obtain for a probit model to those
for a logit model. Are there any substantial differences in the results for the two
models?
2. Continuing the analysis of the first application, we now consider the self-reported
rating, v
1
. This is a natural candidate for an ordered choice model, because the
simple five-item coding is a censored version of what would be a continuous scale on
some subjective satisfaction variable. Analyze this variable using an ordered probit
model. What variables appear to explain the response to this survey question? (Note:
The variable is coded 1, 2, 3, 4, 5. Some programs accept data for ordered choice
modeling in this form, for example, Stata, while others require the variable to be
coded 0, 1, 2, 3, 4, for example, LIMDEP. Be sure to determine which is appropriate
for the program you are using and transform the data if necessary.) Can you obtain
the partial effects for your model? Report them as well. What do they suggest about
the impact of the different independent variables on the reported ratings?
3. Several applications in the preceding chapters using the German health care data
have examined the variable DocVis, the reported number of visits to the doctor.
The data are described in Appendix Table F7.1. A second count variable in that
data set that we have not examined is HospVis, the number of visits to hospital. For
this application, we will examine this variable. To begin, we treat the full sample
(27,326) observations as a cross section.
832
PART IV
✦
Cross Sections, Panel Data, and Microeconometrics
a. Begin by fitting a Poisson regression model to this variable. The exogenous vari-
ables are listed in Appendix Table F7.1. Determine an appropriate specification
for the right-hand side of your model. Report the regression results and the
partial effects.
b. Estimate the model using ordinary least squares and compare your least squares
results to the partial effects you computed in part a. What do you find?
c. Is there evidence of overdispersion in the data? Test for overdispersion. Now,
reestimate the model using a negative binomial specification.What is the result?
Do your results change? Use a likelihood ratio test to test the hypothesis of the
negative binomial model against the Poisson.
4. The GSOEP data are an unbalanced panel, with 7,293 groups. Continue your anal-
ysis in Application 3 by fitting the Poisson model with fixed and with random ef-
fects and compare your results. (Recall, like the linear model, the Poisson fixed
effects model may not contain any time-invariant variables.) How do the panel
data results compare to the pooled results?
5. Appendix Table F18.3 contains data on ship accidents reported in McCullagh and
Nelder (1983). The data set contains 40 observations on the number of incidents of
wave damage for oceangoing ships. Regressors include “aggregate months of ser-
vice”, and three sets of dummy variables, Type (1,...,5), operation period (1960–
1974 or 1975–1979), and construction period (1960–1964, 1965–1969, or 1970–1974).
There are six missing values on the dependent variable, leaving 34 usable observa-
tions.
a. Fit a Poisson model for these data, using the log of service months, four types of
dummy variables, two construction period variables, and one operation period
dummy variable. Report your results.
b. The authors note that the rate of accidents is supposed to be per period, but the
exposure (aggregate months) differs by ship. Reestimate your model constrain-
ing the coefficient on log of service months to equal one.
c. The authors take overdispersion as a given in these data. Do you find evidence
of over dispersion? Show your results.
19
LIMITED DEPENDENT
VARIABLES—TRUNCATION,
CENSORING, AND SAMPLE
SELECTION
Q
19.1 INTRODUCTION
This chapter is concerned with truncation and censoring. As we saw in Section 18.4.6,
these features complicate the analysis of data that might otherwise be amenable to
conventional estimation methods such as regression. “Truncation” effects arise when
one attempts to make inferences about a larger population from a sample that is drawn
from a distinct subpopulation. For example, studies of income based on incomes above
or below some poverty line may be of limited usefulness for inference about the whole
population. Truncation is essentially a characteristic of the distribution from which
the sample data are drawn. Censoring is a more common feature of recent studies. To
continue the example, suppose that instead of being unobserved, all incomes below the
poverty line are reported as if they were at the poverty line. The censoring of a range
of values of the variable of interest introduces a distortion into conventional statistical
results that is similar to that of truncation. Unlike truncation, however, censoring is
essentially a defect in the sample data. Presumably, if they were not censored, the data
would be a representative sample from the population of interest. We will also examine
a form of truncation called the sample selection problem. Although most empirical
work in this area involves censoring rather than truncation, we will study the simpler
model of truncation first. It provides most of the theoretical tools we need to analyze
models of censoring and sample selection.
The discussion will examine the general characteristics of truncation, censoring,
and sample selection, and then, in each case, develop a major area of application of the
principles. The stochastic frontier model [Aigner, Lovell, and Schmidt (1977), Fried,
Lovell, and Schmidt (2008)] is a leading application of results for truncated distributions
in empirical models. Censoring appears prominently in the analysis of labor supply and
in modeling of duration data. Finally, the sample selection model has appeared in all
areas of the social sciences and plays a significant role in the evaluation of treatment
effects and program evaluation.
19.2 TRUNCATION
In this section, we are concerned with inferring the characteristics of a full population
from a sample drawn from a restricted part of that population.
833

834
PART IV
✦
Cross Sections, Panel Data, and Microeconometrics
19.2.1 TRUNCATED DISTRIBUTIONS
A truncated distribution is the part of an untruncated distribution that is above or below
some specified value. For instance, in Example 19.2, we are given a characteristic of the
distribution of incomes above $100,000. This subset is a part of the full distribution of
incomes which range from zero to (essentially) infinity.
THEOREM 19.1
Density of a Truncated Random Variable
If a continuous random variable x has pdf f (x) and a is a constant, then
1
f (x | x > a) =
f (x)
Prob(x > a)
.
The proof follows from the definition of conditional probability and amounts
merely to scaling the density so that it integrates to one over the range above a.
Note that the truncated distribution is a conditional distribution.
Most recent applications based on continuous random variables use the truncated
normal distribution.Ifx has a normal distribution with mean μ and standard deviation
σ, then
Prob(x > a) = 1 −
a − μ
σ
= 1 − (α),
where α = (a − μ)/σ and (.) is the standard normal cdf. The density of the truncated
normal distribution is then
f (x | x > a) =
f (x)
1 − (α)
=
(2πσ
2
)
−1/2
e
−(x−μ)
2
/(2σ
2
)
1 − (α)
=
1
σ
φ
x − μ
σ
1 − (α)
,
where φ(.) is the standard normal pdf. The truncated standard normal distribution, with
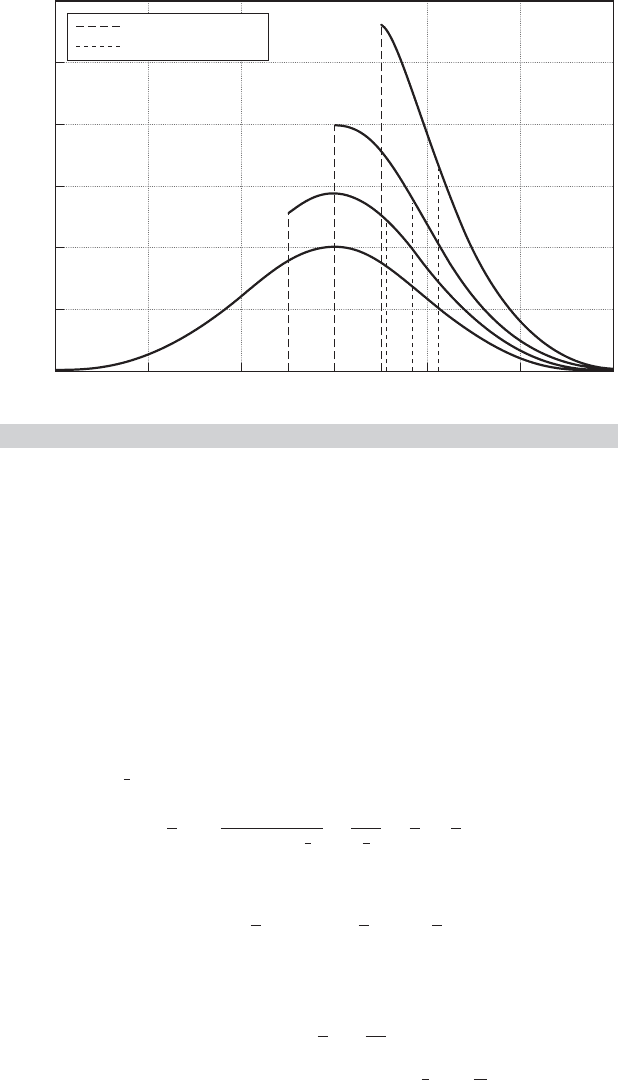
μ = 0 and σ = 1, is illustrated for a =−0.5, 0, and 0.5 in Figure 19.1. Another truncated
distribution that has appeared in the recent literature, this one for a discrete random
variable, is the truncated at zero Poisson distribution,
Prob[Y = y | y > 0] =
(e
−λ
λ
y
)/y!
Prob[Y > 0]
=
(e
−λ
λ
y
)/y!
1 − Prob[Y = 0]
=
(e
−λ
λ
y
)/y!
1 − e
−λ
,λ>0, y = 1,...
This distribution is used in models of uses of recreation and other kinds of facilities
where observations of zero uses are discarded.
2
For convenience in what follows, we shall call a random variable whose distribution
is truncated a truncated random variable.
1
The case of truncation from above instead of below is handled in an analogous fashion and does not require
any new results.
2
See Shaw (1988). An application of this model appears in Section 18.4.6 and Example 18.8.
CHAPTER 19
✦
Limited Dependent Variables
835
3 2 1 0.5 0
Density
0
0.2
0.4
0.6
0.8
1.0
1.2
x
0.5 1 2 3
Truncation point
Mean of distribution
FIGURE 19.1
Truncated Normal Distributions.
19.2.2 MOMENTS OF TRUNCATED DISTRIBUTIONS
We are usually interested in the mean and variance of the truncated random variable.
They would be obtained by the general formula:
E [x |x > a] =
'
∞
a
xf(x |x > a) dx
for the mean and likewise for the variance.
Example 19.1 Truncated Uniform Distribution
If x has a standard uniform distribution, denoted U ( 0, 1), then
f ( x) = 1, 0 ≤ x ≤ 1.
The truncated at x =
1
3
distribution is also uniform:
f
x |x >
1
3
=
f ( x)
Prob
x >
1
3
=
1
2
3
=
3
2
,
1
3
≤ x ≤ 1.
The expected value is
E
x |x >
1
3
=
'
1
1/3
x
3
2
dx =
2
3
.
For a variable distributed uniformly between L and U, the variance is (U − L)
2
/12.
Thus,
Var
x |x >
1
3
=
1
27
.
The mean and variance of the untruncated distribution are
1
2
and
1
12
, respectively.

836
PART IV
✦
Cross Sections, Panel Data, and Microeconometrics
Example 19.1 illustrates two results.
1. If the truncation is from below, then the mean of the truncated variable is greater
than the mean of the original one. If the truncation is from above, then the mean
of the truncated variable is smaller than the mean of the original one.
2. Truncation reduces the variance compared with the variance in the untruncated
distribution.
Henceforth, we shall use the terms truncated mean and truncated variance to refer to
the mean and variance of the random variable with a truncated distribution.
For the truncated normal distribution, we have the following theorem:
3
THEOREM 19.2
Moments of the Truncated Normal Distribution
If x ∼ N[μ, σ
2
] and a is a constant, then
E [x |truncation] = μ + σ λ(α), (19-1)
Var[x |truncation] = σ
2
[1 − δ(α)], (19-2)
where α = (a − μ)/σ, φ(α) is the standard normal density and
λ(α) = φ(α)/[1 −(α)] if truncation is x > a, (19-3a)
λ(α) =−φ(α)/(α) if truncation is x < a, (19-3b)
and
δ(α) = λ(α)[λ(α) − α]. (19-4)
An important result is
0 <δ(α)<1 for all values of α,
which implies point 2 after Example 19.1. A result that we will use at several points below
is dφ(α)/dα =−αφ(α). The function λ(α) is called the inverse Mills ratio. The function
in (19-3a) is also called the hazard function for the standard normal distribution.
Example 19.2 A Truncated Lognormal Income Distribution
“The typical ‘upper affluent American’ ...makes $142,000 per year . . . . The people surveyed
had household income of at least $100,000.”
4
Would this statistic tell us anything about the
“typical American”? As it stands, it probably does not (popular impressions notwithstanding).
The 1987 article where this appeared went on to state, “If you’re in that category, pat yourself
on the back—only 2 percent of American households make the grade, according to the
survey.” Because the degree of truncation in the sample is 98 percent, the $142,000 was
probably quite far from the mean in the full population.
Suppose that incomes, x, in the population were lognormally distributed—see Sec-
tion B.4.4. Then the log of income, y, had a normal distribution with, say, mean μ and
3
Details may be found in Johnson, Kotz, and Balakrishnan (1994, pp. 156–158). Proofs appear in Cameron
and Trivedi (2005).
4
See New York Post (1987).

CHAPTER 19
✦
Limited Dependent Variables
837
standard deviation, σ . Suppose that the survey was large enough for us to treat the sam-
ple average as the true mean. Assuming so, we’ll deduce μ and σ and then determine the
population mean income.
Two useful numbers for this example are In 100 = 4.605 and In 142 = 4.956. The article
states that
Prob[x ≥ 100] = Prob[exp( y) ≥ 100] = 0.02,
or
Prob( y < 4.605) = 0.98.
This implies that
Prob[( y − μ) /σ < (4.605 − μ)/σ ] = 0.98.
Because [(4.605 − μ)/σ ] = 0.98, we know that
−1
(0.98) = 2.054 = (4.605 − μ)/σ,
or
4.605 = μ + 2.054σ.
The article also states that
E[x |x > 100] = E[exp( y) |exp( y) > 100] = 142,
or
E[exp( y) | y > 4.645] = 142.
To proceed, we need another result for the lognormal distribution:
If y ∼ N[μ, σ
2
], then E[exp( y) | y > a] = exp(μ + σ
2
/2) ×
(σ − (a − μ)/σ )
1 − ((a − μ)/σ )
.
[See Johnson, Kotz, and Balakrishnan (1995, p. 241).] For our application, we would equate
this expression to 142, and a to In 100 = 4.605. This provides a second equation. To estimate
the two parameters, we used the method of moments. We solved the minimization problem
Minimize
μ,σ
[4.605 −(μ +2.054σ)]
2
+[142((μ −4.605)/σ ) −exp(μ +σ
2
/2)( σ −(4.605 −μ) /σ )]
2
.
The two solutions are 2.89372 and 0.83314 for μ and σ , respectively. To obtain the mean
income, we now use the result that if y ∼ N[μ, σ
2
] and x = exp( y) , then E[x] = exp(μ + σ
2
/2).
Inserting our values for μ and σ gives E[x] = $25,554. The 1987 Statistical Abstract of
the United States gives the mean of household incomes across all groups for the United
States as about $25,000. So, the estimate based on surprisingly little information would have
been relatively good. These meager data did, indeed, tell us something about the average
American.
19.2.3 THE TRUNCATED REGRESSION MODEL
In the model of the earlier examples, we now assume that
μ
i
= x
i
β
is the deterministic part of the classical regression model. Then
y
i
= x
i
β + ε
i
,

838
PART IV
✦
Cross Sections, Panel Data, and Microeconometrics
where
ε
i
|x
i
∼ N[0,σ
2
],
so that
y
i
|x
i
∼ N[x
i
β,σ
2
]. (19-5)
We are interested in the distribution of y
i
given that y
i
is greater than the truncation
point a. This is the result described in Theorem 19.2. It follows that
E [y
i
| y
i
> a] = x
i
β + σ
φ[(a − x
i
β)/σ ]
1 − [(a − x
i
β)/σ ]
. (19-6)
The conditional mean is therefore a nonlinear function of a,σ,x, and β.
The partial effects in this model in the subpopulation can be obtained by writing
E [y
i
| y
i
> a] = x
i
β + σ λ(α
i
), (19-7)
where now α
i
= (a − x
i
β)/σ . For convenience, let λ
i
= λ(α
i
) and δ
i
= δ(α
i
). Then
∂E [y
i
| y
i
> a]
∂x
i
= β + σ(dλ
i
/dα
i
)
∂α
i
∂x
i
= β + σ
λ
2
i
− α
i
λ
i
(−β/σ )
= β
1 − λ
2
i
+ α
i
λ
i
= β(1 −δ
i
).
(19-8)
Note the appearance of the scale factor 1 − δ
i
from the truncated variance. Because
(1 −δ
i
) is between zero and one, we conclude that for every element of x
i
, the marginal
effect is less than the corresponding coefficient. There is a similar attenuation of the
variance. In the subpopulation y
i
> a, the regression variance is not σ
2
but
Var[y
i
| y
i
> a] = σ
2
(1 − δ
i
). (19-9)
Whether the partial effect in (19-7) or the coefficient β itself is of interest depends on the
intended inferences of the study. If the analysis is to be confined to the subpopulation,
then (19-7) is of interest. If the study is intended to extend to the entire population,
however, then it is the coefficients β that are actually of interest.
One’s first inclination might be to use ordinary least squares to estimate the param-
eters of this regression model. For the subpopulation from which the data are drawn,
we could write (19-6) in the form
y
i
| y
i
> a = E [y
i
| y
i
> a] + u
i
= x
i
β + σλ
i
+ u
i
, (19-10)
where u
i
is y
i
minus its conditional expectation. By construction, u
i
has a zero mean,
but it is heteroscedastic:
Var[u
i
] = σ
2
1 − λ
2
i
+ λ
i
α
i
= σ
2
(1 − δ
i
),