Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.

Definition
Linear dimension reduction technique reduces the di-
mension of biometric data using a linear transform. The
linear transform is always learned by optimization of a
criterion. Biometric data are then projected on to the
range space of this transform. Subsequent processing is
then performed in that lower-dimensional space.
Introduction
In biometrics, data are invariably represented in vectors
and the dimensionality is consistently very high. It would
be computationally expensive to process them directly by
using many algorithms. Moreo ver, it is sometimes desir-
able to exact robust, informativ e or discriminative facts
contained in the data. For these reasons, a lower dimen-
sional subspace is found such that the most important
part of the data is retained for linear representation.
Among the techniques for learning such subspace, linear
dimension reduction methods are popular.
Given a set of N data samples {x
1
,..., x
N
}, where x
i
2<
n
. Linear dimension reduction technique finds a
linear transform matrix W ¼ (w
1
, ..., w
ℓ
) such that
data are projected on to the range space span{w
1
,...,
w
ℓ
}by
y
i
¼ W
T
x
i
; ð1Þ
where
T
denotes the transpose and y
i
is the representa-
tion of x
i
in the lower-dimensional space.
The linear dimension reduction technique is equal
to extraction of linear features w
1
,...,w
ℓ
. Different
linear dimension reduction techniques lie in different
goals of the information retained by these linear fea-
tures. Generally, they can be categorized into three
classes, which address the linear dimension problem
in the
▶ unsupervised, ▶ supervised, and ▶ semi-
supervised cases respectively. Some representative
algorithms of these classes are des cribed here.
When biometric data are represented in a matrix
form, line ar dimension reduction techniques can also
be extended. This kind of extension is called the two-
dimensional linear dimension reduction technique.
Unsupervised Linear Dimension
Reduction
Unsupervised linear dimension reduction aims at the
extraction of reconstructive features. Biometric data are
then linearly approximated in a lower-dimensional sub-
space spanned by the reconstructive features. Among the
popular linear algorithms used in biometrics for dimen-
sion reduction, the Principal Component Analysis (PCA)
[1] is the most representative one. The PCA finds a
lower-dimensional space that preserves the greatest
variations of data, that is, an optimal transform is
learned by maximization of the following criterion:
W
opt
¼ arg max
W
T
W¼I
traceðW
T
C
t
WÞ; ð2Þ
where C
t
is the total-class covariance matrix defined by
C
t
¼
1
N
X
N
i¼1
ðx
i
uÞðx
i
uÞ
T
; u ¼
1
N
X
N
i¼1
x
i
: ð3Þ
Eigen-decomposition is used to find w
1
,...,w
ℓ
, which
are eigenvectors corresponding to the largest ℓ eigen-
values. However, preserving the largest eigenvectors
may not be the best strategy for other applications of
the PCA, such as recognition and clustering . In these
cases, the selection of proper principal components
may be useful.
Features extracted by the PCA are statistically
uncorrelated, but they are not ensured to be statistically
independent. If it is assumed that data are approximately
linear representations of some independent sources,
then it is useful to find these independent components
for representation of data in an intrinsic subspace. The
Independent Component Analysis (ICA) [2] pursues
features in this aspect. Let X ¼ [x
1
,..., x
N
] be the
data matrix. In the IC A, data matrix X is approximated
by a multiplication of mixing matrix A and matrix S
which consists of independent components as follows
X AS: ð4Þ
Several approaches have been proposed for the estima-
tion of the ICA and the most popular of these is
FastICA [2].
In biometric learning, especially facial image anal-
ysis, has been experimentally demonstrated that the
extraction of localized features is useful for recognition
and for the interpretation and understanding of the
structure of data as well. Unlike the PCA and the ICA,
non-negative matrix factorization (NMF) [3] is a novel
technique for this purpose. In the NMF, data are
approximated only by additive combination of non-
negative components. The NMF, therefore, finds two
non-negative matrices, namely, the component matrix
W
opt
and the coefficient matrix H
opt
, which are mini-
mums of the following criterion
900
L
Linear Dimension Reduction

ðW
opt
; H
opt
Þ¼arg min
ðW;HÞ
jjX WHjj
2
F
;
s:t: W 0 & H 0:
ð5Þ
where jjjj
F
is the Frobenius norm. Other than using
the Euclidean distance, the following criterion based
on the generalized Kullback-Leibler divergence that is
lower bounded by Zoro is also popular
ðW
opt
; H
opt
Þ¼arg min
ðW;HÞ
X
i;j
X
ij
log
X
ij
ðWHÞ
ij
X
ij
þðWHÞ
ij
; s:t: W 0 & H 0:
ð6Þ
Closed forms of W
opt
and H
opt
in the NMF are difficult
to obtain. At present, the multiplicative update method
[4] has been widely used for finding a locally optimal
solution.
The former three methods do not take the geomet-
ric relationship between data into account. Assume
data are actuall y distributed on a manifold, it is natural
that the neighboring data in the input space would also
be close to each other when they are represented in the
lower rank subspace. The locality preserving projection
(LPP) [5] is a typical algorithm developed for this
purpose. It learns an optimal transform W
opt
such
that the locality relationship between data in the
input data space are preserved after dimension reduc-
tion. The cost function of a transform W for locality
preserving is modeled by
1
2
X
i;j
g
ij
jjy
i
y
j
jj
2
¼
1
2
traceðW
T
X
i;j
g
ij
ðx
i
x
j
Þðx
i
x
j
Þ
T
WÞ;
where g
ij
the affinity between samples x
i
and x
j
is
defined by
g
ij
¼
1ifx
i
2N
s
ðx
j
Þ or x
j
2N
s
ðx
i
Þ;
0 otherwise;
ð7Þ
and N
s
ðx
i
Þ is the set of s nearest neighbors of data x
i
.
Then the optimal transform explored by the LPP is
learned as follows
W
opt
¼ arg min
w
T
i
XDX
T
w
i
¼1
traceðW
T
S
p
WÞ; ð8Þ
where D¼diag(∑
j
g
1j
,...,∑
j
g
Nj
), S
p
¼ XLX
T
and L is
termed the Laplacian matrix (He and Niyogi [5]) for-
mulated by
L ¼ D G; G
ij
¼ g
ij
: ð 9Þ
Supervised Linear Dimension
Reduction
PCA, the ICA, the NMF and the LPP are methods for
learning unlabeled data. Since the features extracted
by these methods are not discriminative, they may not
be useful for recognition. When class labels of data
are known, supervised techniques for dimension re-
duction can be developed by additionally using label
information. Suppose data x
1
, ..., x
N
are drawn from
L classes, namely, classes C
1
,...,C
L
, and N
k
be the
number of samples of class C
k
, the supervised dimen-
sion reduction technique then finds a transform such
that data of the same class are close to each other
while data of different classes are scattered as far as
possible. A popular and widely applied technique is
(Generalized) Fisher’s linear discriminant analysis
(LDA) [6]. The LDA finds a lower-dimensional sub-
space in which the ratio between between-class vari-
ance and within-class variance is maximized. That is, a
discriminative linear transform W
opt
is the maximum
of the following criterion
W
opt
¼ arg max
W
traceðW
T
S
b
WÞ
traceðW
T
S
w
WÞ
; ð10Þ
where S
b
and S
w
are between-class and within-class
covariance matrices respectively, which are defined as
follows:
S
w
¼
1
N
X
L
k¼1
X
x
i
2C
k
ðx
i
u
k
Þðx
i
u
k
Þ
T
; u
k
¼
1
N
k
X
x
i
2C
k
x
i
;
S
b
¼
1
N
X
L
k¼1
N
k
ðu
k
uÞð u
k
uÞ
T
:
To obtain the optimum of a criterion [10], the
eigenvectors of S
w
1
S
b
have to be determined. As
dimensionality of data is high and training samples
are in invariably limited in biometric learning, with-
in-class covariance matrix S
w
will be singular. This
kind of singularity problem is referred to as the small
sample size problem in the LDA. Techniques used to
address this problem include, PCA+LDA [7], the Null-
space LDA (N-LDA) (Chen et al. [8]), and the regular-
ized LDA [9]. In the PCA+LDA, LDA is performed in a
principal component subspace in which within-class
covariance matrix is of full rank. In the N-LDA, the
nullspace of within-class covariance matrix S
w
is first
learned; then data are projected on to that subspace;
finally the discriminant transform is found for
Linear Dimension Reduction
L
901
L

maximization of the variance of between-class data.
Though both the PCA+LDA and the N-LDA are
lower-rank methods that first project data onto a
lower-dimensional subspace before implementation
of any discriminant processing, they are different in
that S
w
in the PCA+LDA will be of full rank after
dimension reduction by the PCA while trace
(W
T
S
w
W) ¼ 0 after dimension reduction in the N-
LDA. Unlike the lower-rank approach, in the regular-
ized LDA (R-LDA), a regularized term, such as aI
where a > 0, is added to matrix S
w
in Eq. (10),
so that Fisher criterion is well-conditioned. Regu-
larization is a straightforward way to solve this
singularity problem, but the regularized parameter
will have a significant impact on the performance
of the R-LDA.
An alternative way to maximize between-class var-
iance as well as minimize within-class variance can be
modeled as follows:
W
opt
¼ arg max
W
traceðW
T
S
b
WÞl traceðW
T
S
w
WÞ;
ð11Þ
where l > 0. The advantage of using this model is that
computation of the inverse of S
w
is not required, but
how to determine the importance weight l could be a
problem. This criterion is known as the maximum
margin criterion [10] when l ¼ 1.
At times, unsupervised linear dimension reduction
techniques can be used as a preprocessing step before
applying supervised techniques. Methods driven in
this way are two-step dimension reduction techniques.
The PCA+LDA is typically in line with this approach.
In addition, though supervised methods are always
preferred for recognition, it is difficult to ascertain
which kind of linear dimension reduction technique
is the best. For example, the PCA may be better than
the LDA for face recognition if the number of training
samples for each class is sm all [11].
Semi-Supervised Linear Dimension
Reduction
Linear dimension reduction for partially labeled data
would be highly demanded for large scale problems,
since labeling data is an expensive task. Therefore, it is
desirable to utilize unlabeled data for extraction of
supervised features for dimension reduction. Among
the developed techniques to achieve this goal, a special
regularized LDA for performing linear dimension re-
duction on partially labeled data can be formulated as
follows [12]:
W
opt
¼ arg max
W
traceðW
T
S
b
WÞ
traceðW
T
ðS
t
þ bS
p
ÞWÞ
; ð12Þ
where S
t
¼ S
w
þ S
b
and b > 0. In this criterion, labeled
data are used to estimate superv ised class covariance
information, and the effect of unlabeled data is
reflected by the Laplacian term S
p
. The underusing
idea is that labeled data are separated in the same
way as done in the LDA while the neighboring data
including unlabeled data are nearby after dimension
reduction.
Two-Dimensional Linear Dimension
Reduction Techniques
Many well-known linear dimension reduction techni-
ques assume that input patterns are represented in vec-
tors. However, biometric data are captured in images,
and the dimensionality is very high when they are
reshaped into vectors. Unlike traditional techniques,
some linear dimension reduction techniques are devel-
oped by performing linear transformation directly
on matrix form data, such as image matrices. This is
advantageous in tackling large scale problems. Suppose
X
1
, ..., X
N
are the corresponding matrix representa-
tions of vector form data x
1
,...,x
N
, then a transform
W for dimension reduction of X
i
would perform as
follows
Y
i
¼ W
T
X
i
; ð13Þ
where Y
i
is the representatio n after dimension reduc-
tion. Among the developed techniques are two repre-
sentative algorithms: two-dimensional principal
component analysis (2D-PCA) [13] and two-dimen-
sional linear discriminant analysis (2D-LDA) [14]. The
vector-based PCA and LDA are also referred to as the
1D-PCA and 1D-LDA respectively.
The main difference between 2D-PCA and 1D-PCA
as well as between 2D-LDA and 1D-LDA lies in their
different means of covariance matrix estimation. In
two-dimensional linear reduction techniques, the co-
variance matrices are calculated directly based on data
represented in matrix form. Apart from this, the main
902
L
Linear Dimension Reduction

ideas of 2D-PCA and 2D-LDA are almost similar to
those of 1D-PCA and 1D-LDA respectively. More spe-
cifically, 2D-PCA learns the optimal transform via the
following criterion
W
2d
opt
¼ arg max
W
T
W¼I
traceðW
T
C
2d
t
WÞ; ð14Þ
where
C
2d
t
¼
1
N
X
N
i¼1
ðX
i
UÞðX
i
UÞ
T
; U ¼
1
N
X
N
i¼1
X
i
:
For 2D-LDA, the criterion is modified in a simil ar
manner as follows:
W
2d
opt
¼ arg max
W
traceðW
T
S
2d
b
WÞ
traceðW
T
S
2d
w
WÞ
; ð15Þ
where
S
2d
w
¼
1
N
X
L
k¼1
X
X
i
2C
k
ðX
i
U
k
ÞðX
i
U
k
Þ
T
;
U
k
¼
1
N
k
X
X
i
2C
k
X
i
:
S
2d
b
¼
X
L
k¼1
N
k
N
ðU
k
UÞðU
k
UÞ
T
:
The above 2D-PCA and 2D-LDA are unilateral,
which mean s only one transform matrix multiplied
on one side of the data matrix is available. To overcome
this limitation, there are generalizations such as bilat-
eral 2D-PCA [15] and bilateral 2D-LDA [16], which
learn transform matrices W
l
and W
r
on both sides of
the data matrix and perform dimension reduction for
data X
i
as follows
Y
i
¼ W
T
l
X
i
W
r
: ð16Þ
However, it would be difficult to obtain a closed solu-
tion for bilateral techniques, and alternating
optimization methods are used for finding a locally
optimized solution.
In general, two-dimensional linear dimension re-
duction techniques gain lower cost of computation,
and 2D-L DA in particular avoids the small sample
size problem. However, it is cannot be definitely said
that two-dimensional techniques are better. An in-
sightful analysis and extensive comparisons between
2D-LDA and 1D-LDA have been made by [17]. Besides
the theoretical comparisons, Zheng et al. noted that
2D-LDA is not always better than 1D-LDA when the
number of training samples for each class or the num-
ber of extracted features is small.
Summary
Linear dimension reduction is an important step for
processing of biometric data. It is equal to extraction
of a set of linear feature vectors, which span a lower-
dimensional subspace. Linear techniques for finding
the most robust, informative and discriminative
information are fundamental technologies in pattern
recognition. Besides, the development of new linear
techniques for large scale problems in biometric learning
is an important topic.
Related Entries
▶ Feature Extraction
▶ Kernel Methods
▶ LDA (Linear Discriminant Analysis)
▶ Manifold Learning
▶ PCA (Principal Comp onent Analysis)
References
1. Turk, M., Pentland, A.: Eigenfaces for recognition. J. Cogn.
Neurosci. 3(1), 71–86 (1991)
2. Hyva
¨
rinen, A., Oja, E.: Independent component analysis:
algorithms and applications. Neural Networks 13, 411–430
(2000)
3. Lee, D.D., Seung, H.S.: Learning the parts of objects by
non-negative matrix factorization. Nature 401, 788–791
(1999)
4. Lee, D.D., Seung, H.S.: Algorithms for non-negative matrix
factorization. In: Advances in Neural Information Processing
Systems, Denver, Colorado pp. 556–562 (2000)
5. He, X., Niyogi, P.: Locality preserving projections. In: Advances
in Neural Information Processing Systems, Vancauver, Canada
pp. 153–160 (2003)
6. A., F.R.: The Use of Multiple Measures in Taxonomic Problems.
Ann. Fisher, RA Eugenics 7, 179–188 (1936)
7. Belhumeour, P.N., Hespanha, J.P., Kriegman, D.J.: Eigenfaces vs.
fisherfaces: recognition using class specific linear pro-
jection. IEEE Trans. Pattern Analy. Mach. Intell. 19(7),
711–720 (1997)
Linear Dimension Reduction
L
903
L
8. Chen, L.F., Liao, H.Y.M., Ko, M.T., Lin, J.C., Yu, G.J.: A
new LDA-based face recognition system which can solve the
small sample size problem. Pattern Recogn. 33, 1713–1726
(2000)
9. Webb, A.R. (ed.): Statistical Pattern Recognition, 2nd ed. 2002.
Wiley, England (2002)
10. Li, H., Jiang, T., Zhang, K. Efficient and robust feature extraction
by maximum margin criterion. IEEE Trans. Neural Networks
17(1), 157–165 (2006)
11. Martı
´
nez, A.M., Kak, A.C.: PCA versus LDA. IEEE Trans. Pattern
Analy. Mach. Intell. 23(2), 228–233 (2001)
12. Cai, D., He, X., Han, J.: Semi-supervised Discriminant
Analysis. In: IEEE Int. Conf. Comput. Vis. Rio de Janeiro, Brazil
(2007)
13. Yang, J., Zhang, D., Frangi, A.F., Yang, J.y.: Two-dimensional
PCA: a new approach to appearance-based face representation
and recognition. IEEE Trans. Pattern Analy. Mach. Intell. 26(1),
131–137 (2004)
14. Xiong, H., Swamy, M.N.S., Ahmad, M.O.: Two-
dimensional FLD for face recognition. Pattern Recogn. 38,
1121–1124 (2005)
15. Kong, H., Li, X., Wang, L., Teoh, E.K., J.-G., W., Venkateswarlu, R.:
Generalized 2D principal component analysis. In: IEEE Interna-
tional Joint Conference on Neural Networks, vol. 1, pp. 108–113.
Oxford, UK (2005)
16. Ye, J.P., Janardan, R., Li, Q.: Two-dimensional linear discrimi-
nant analysis. In: Advances in Neural Information Processing
Systems, pp. 1569–1576 (2004)
17. Zheng, W.S., Lai, J.H., Li, S.Z.: 1D-LDA versus 2D-
LDA: when is vector-based linear discriminant analysis
better than matrix-based? Pattern Recogn. 41(7), 2156–2172
(2008)
Linear Feature Extraction
▶ Linear Dimension Reduction
Linearly Symmetric Image
An image described by f(x, y) is linearly sy mmetric if its
isocurves have a common direction, i.e., there exists a
1D function h(t) such that f(x, y)=h(kxx + kyy) for a
certain (constant) direction vector k =(kx, ky)T.
▶ Fingerprint Features
Lip Movement Recognition
PETAR S. ALEKSIC
Google Inc ., New York, NY, USA
Synonyms
Audio–visual-dynamic speaker recognition; Visual-
dynamic speaker recognition
Definition
Lip movement recognition is a speaker recognition
technique, where the identity of a speaker is deter-
mined/verified by exploiting information contained in
dynamics of changes of visual features extracted from
the mouth region. The visual features usually consist of
appropriate representations of the mouth appearance
and/or shape. This dynamic visual information can
also be used in addition to the acoustic information
in order to improve the performance of audio-only
speaker recognition systems and increase their resil-
ience to spoofing, therefore giving rise to audio–visual-
dynamic speaker recognition systems.
Introduction
Speech contains information about identity, emotion,
location, as well as linguistic information, and plays a
significant role in the development of human computer
interaction (HCI) systems, including speaker recogni-
tion systems. However, audio-only systems can per-
form poorly even at typical acoustic background
signal-to-noise ratio levels (10 to 20 dB). In addition,
they can be sensitive to microphone types (desktop,
telephone, etc.), acoustic environment (car, plane,
factory, babble, etc.), channel noise (telephone lines,
VoIP, etc.), or complexity of the scenario (speech under
stress, Lombard speech, whispered speech).
Similarly, the visual modality can be exploited to
improve HCI [1, 2]. Visual facial features extracted
from the mouth region are both correlated to the
produced audio signal [3] and also contain comple-
mentary information to it [4]. Lip movement recogni-
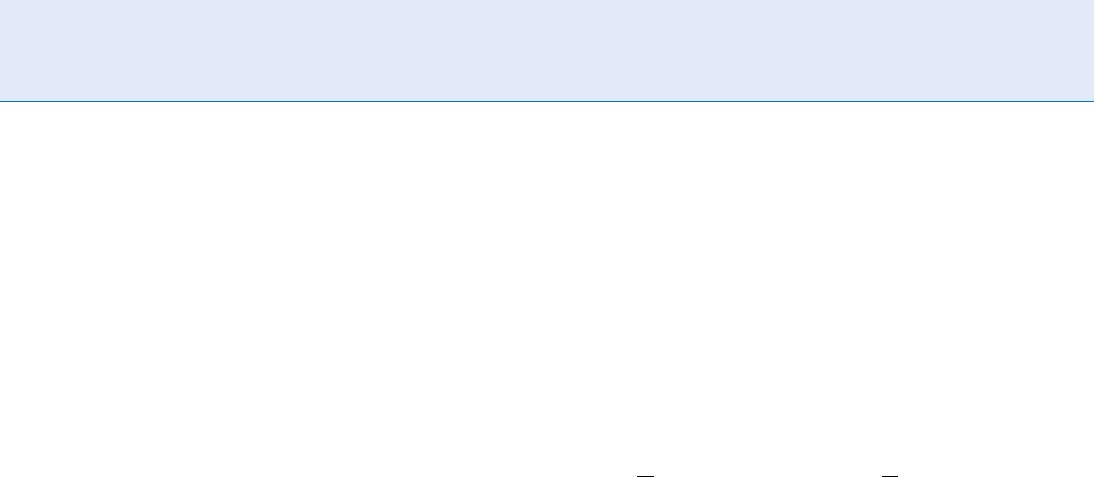
tion systems, also known as visual-dynamic speaker
904
L
Linear Feature Extraction
recognition systems, exploit information contained in
dynamics of changes of visual features extracted from
video sequences of the mouth area (see Fig. 1). Although
speaker recognition systems that utilize only visua l-
dynamic information can achieve high recognition
rates, visual-dynamic information is typically utilized
together with acoustic information to improve speaker
recognition performa nce, resulting in audio–visual-
dynamic speaker recognition systems (see Fig. 1).
There is a number of audio–visual fusion techniques
[5], that combine audio and v isual information to
achieve higher recognition performance than both
audio-only and visual-only system s. The use of visual
information improves speaker recognition perfor-
mance even in noise-free environments [ 5, 6]. The
potential for such improvements is even greater in
acoustically noisy environments, since v isual features
are typically much less affected by acoustic nois e than
the acoustic features. In addition, audio-only, as well as
static-image-based (face recognition) pers on recogni-
tion systems are vulnerable to impostor attacks (spoof-
ing), if the impostor possesses a photograph and/o r
speech recordings of the client. However, it is signifi-
cantly more difficult for an impostor to impersonate
both acoustic and dynamical-visual (lip movements)
information simultaneously. The main advantage of
audio–visual-dynamic speaker recognition systems
lies in their robustness, since each modality can pro-
vide independent and complementary information
and therefore prevent performance degradation due
to the noise present in one or both of the modalities,
as well as increase resilience to spoofing. Another ad-
vantage of audio–visual speaker recognition systems is
that they use unobtrusive and low-cost methods for
extracting biometric features, thus enabling natural
speaker recognition and reducing inconvenience.
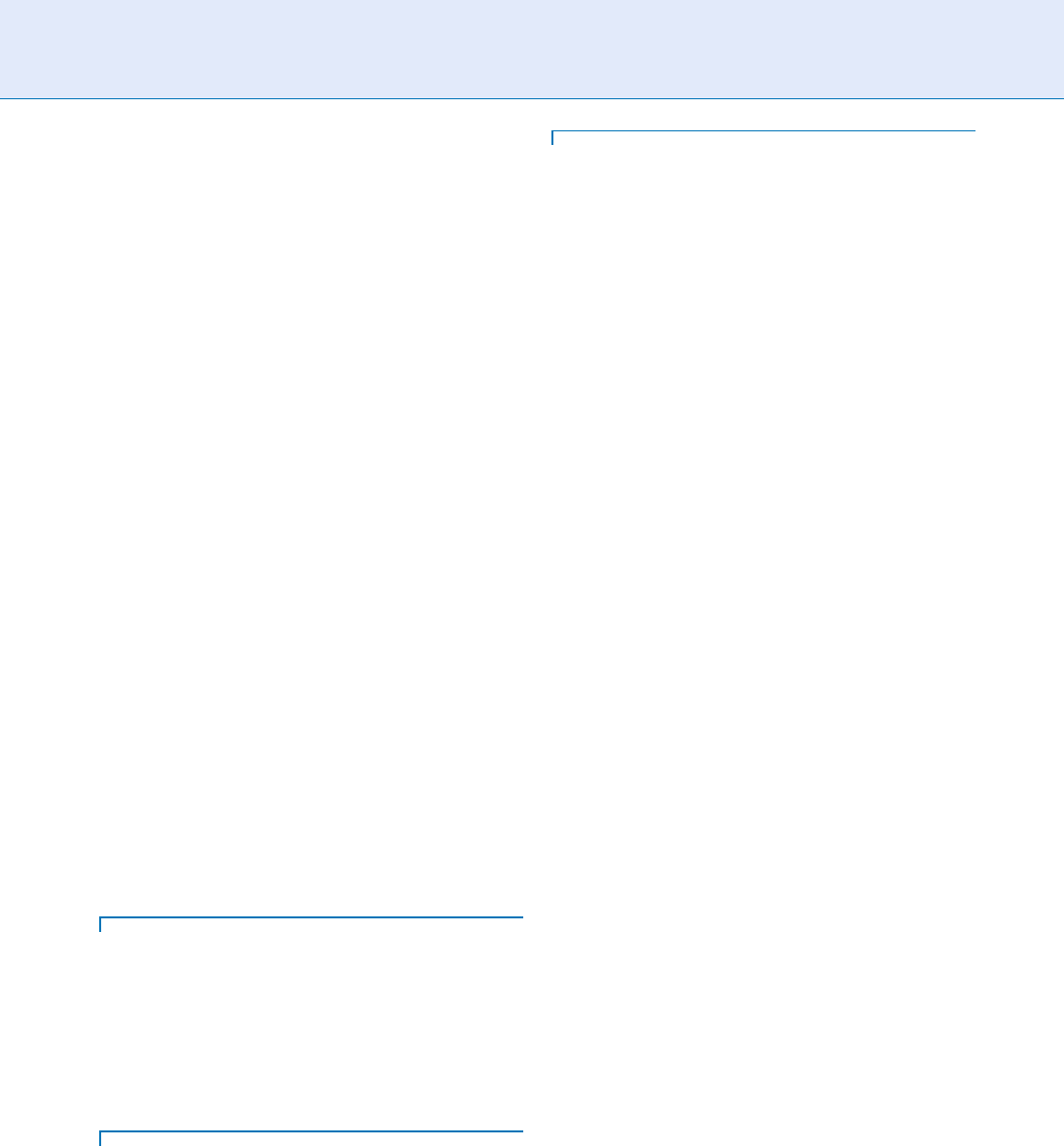
Operation of a Lip-Movement
Recognition System
The block diagram of a visual-dynamic speaker recog-
nition system is shown in Fig. 2. It consists of three
main blocks, corresponding to prepr ocessing, visual
feature extraction, and classification phases.
In the preprocessing phase, detection and tracking of
the face and the important facial features in the input
video are performed. These tasks represent challenging
problems, especially in cases where the background,
head pose, and lighting are varying [7]. The most com-
monly used face detection techniques use statistical
modeling of the face appearance to obtain a classification
Lip Movement Recognition. Figure 2 Block diagram of a visual-dynamic speaker recognition system.
Lip Movement Recognition. Figure 1 Speaker recognition systems.
Lip Movement Recognition
L
905
L
of image regions into face and non face classes. These
regions are typically represented as vectors of grayscale
or color image pixel intensities. They are often projected
onto lower dimensional spaces, and are defined over a
number of possible locations, scales, and orientations in
the video frame. One or more techniques, such as artifi-
cial neural networks (ANNs), support vector machines
(SVMs), Gaussian mixture models (GMMs), clustering
algorithms, and linear discriminants, are usually utilized
to classify these regions. Typically, face detection goes
hand-in-hand w ith tracking in which the temporal cor-
relation is taken into account.
After successful face detection, facial features, such as
mouth corners, eyes, nostrils, and chin, are detected by
utilizing prior knowledge of their relative position on the
face to simplify the search. If color information is avail-
able, it can be utilized to detect certain facial features
(especially lips). Subsequently, the mouth region-of-
interest (ROI), containing useful visual information is
extracted. The ROI is typically a rectangle containing
the mouth, possibly including larger parts of the lower
face, such as the jaw and cheeks (see Fig. 3). The nor-
malization is usually performed with respect to head-
pose information and lighting. The ROI can also be
extended into a three-dimensional rectangle, contain-
ing adjacent frame ROIs, thus capturing dynamic
visual information.
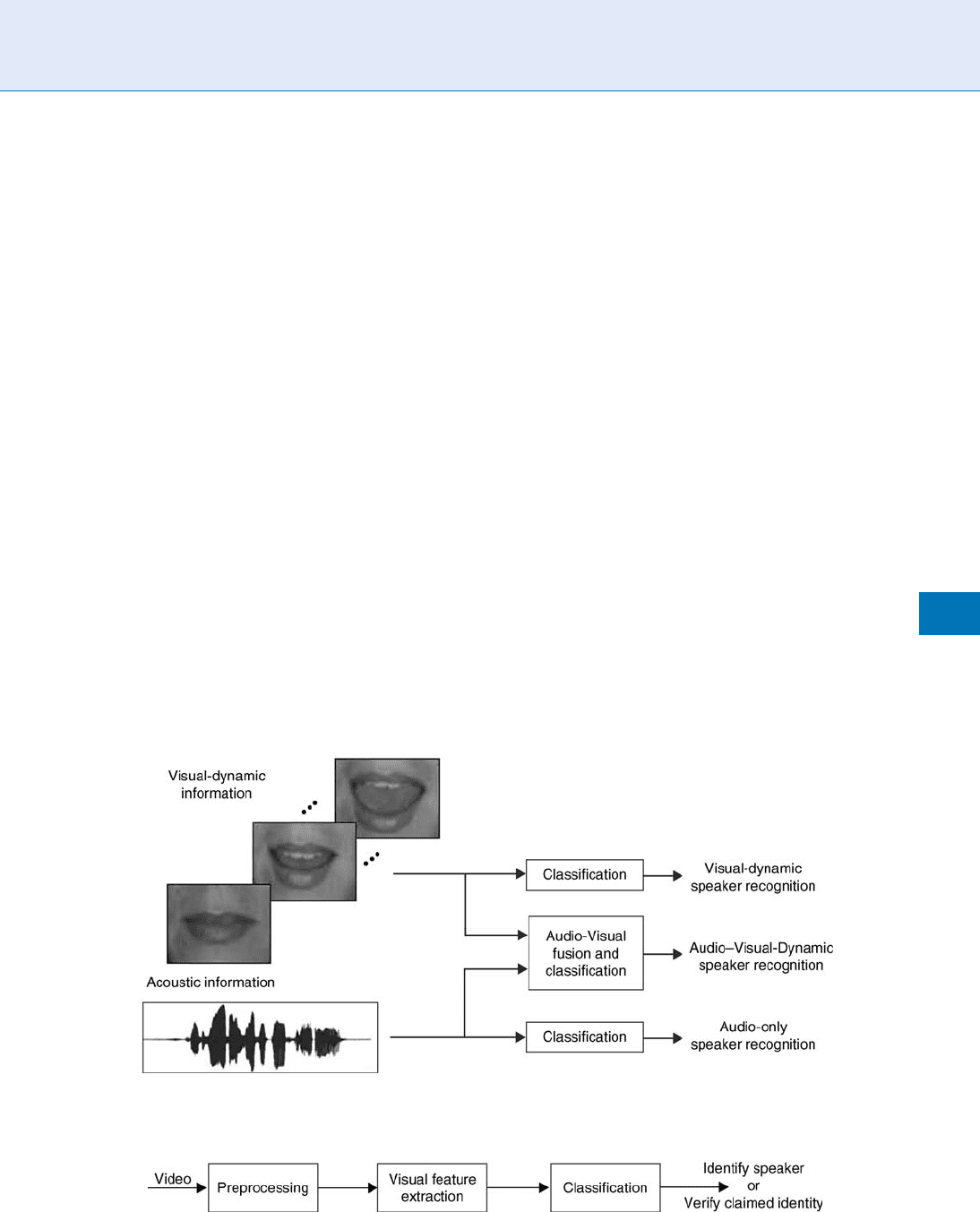
In the visual feature extraction phase, relevant visual
features from the ROI are extracted. Investigating choice
of visual features for speaker recognition is a relatively
new research topic. The various sets of the choice facial
features proposed in the literature are generally grouped
into three categories [8]: (1) appearance-based features;
(2) shape-based features; and (3) features that are a
combination of both appearance and shape features
[5]. The appearance-based visual features are extracted
from the ROI using image transforms, such as princi-
pal component analysis (PCA,) generati ng ‘‘eigenlips’’
[9], the discrete cosine transform (DCT) [10], the
discrete wavelet transform (DWT) [10], linear discrim-
inant analysis (LDA) [2, 5, 11], Fish er linear discrimi-
nant (FLD), etc. (see Fig. 3). These transforms are
applied on a feature vector, created by ordering the
grayscale pi xel values inside the ROI, and are com-
monly applied in series to cope with the ‘‘curse of
dimensionality’’ problem.
Shape-based visual mouth features are divided into
geometric, parametric, and statistical (see Fig. 3). With
shape-based features it is assumed that most of the
information is contained in the shape of the speaker’s
lips [5, 12]. Hence, such features achieve a compact
representation of mouth images using low-dimen-
sional vectors. Geometric features, such as the height,
width, perimeter of the mouth, etc., are meaningful to
humans and can be readily extracted from the mouth
images. Alternatively, model-based visual features are
typically obtained in conjunction with a parametric or
statistical facial feature extraction algorithm. With
model-based approaches, the model parameters are
directly used as visual features [5, 12]. Examples of
Lip Movement Recognition. Figure 3 Various visual facial features divided into appearance- and shape-based features.
906
L
Lip Movement Recognition

statistical models are active shape and active appear-
ance models [13].
The combination of appearance- and shape-based
visual features has also been utilized in expectation of
improving the performance of the recognition system,
since they contain respectively low- and high-
level information about the person’s lip movements.
Appearance- and shape-based features are usually just
concatenated, or a single model of face shape and
appearance is created [13]. The dynamics of the
changes of v isual features are usually captured by aug-
menting the visual feature vector by its first- and
second-order time derivatives, computed over a short
temporal window centered at the current video frame.
Finally, in the classification phase, a num ber of
classifiers can be used to model prior knowledge of
how the visual features are generated by each speaker.
They are usually statistical in nature and utilize ANNs,
SVMs, GMMs, HMMs, etc. The parameters of the
prior model are estimated during training. During
testing, based on the trained model the posterior prob-
ability is maximized, and identification/verification
decision is made.
Summary
Lip movement recognition and audio–visual-dynamic
speaker recognition are speaker recognition technolo-
gies that are user-friendly, low-cost, and resilient to
spoofing. There are many biometric applications,
such as, sport venue entrance check, access to desktop,
building access, etc., in which it is very impor tant to
use unobtrusive methods for extracting biometric fea-
tures, thus enabling natural person recognition and
reducing inconvenience. Low cost of audio and video
biometric sensors and the ease of acquiring audio and
video signals (even without assistance from the client),
makes biometric technology more socially acceptable
and accelerates its integration into every day life.
Related Entries
▶ Face Recognition
▶ Face Tracking
▶ Multibiometrics
▶ Multibiometrics and Data Fusion
▶ Multimodal Systems
▶ Speaker Matching
▶ Session Effects on Speaker Modeling
▶ Speaker Recognition, Overview
▶ Speech Analysis
▶ Speech Production
▶ Spoofing
References
1. Chen, T., Rao, R.R.: Audio-visual integration in multimodal
communication. Proc. IEEE 86(5), 837–852 (1998)
2. Aleksic, P.S., Potamianos, G., Katsaggelos, A.K.: Exploiting visual
information in automatic speech processing. In: Bovik, A.L.
(ed.) Handbook of Image and Video Processing. Academic,
London (2005)
3. Aleksic, P.S., Katsaggelos, A.K.: Speech-to-video synthesis using
MPEG-4 compliant visual features. IEEE Trans CSVT, Special
Issue on Audio and Video Analysis for Multimedia Interactive
Services, pp. 682–692, May (2004)
4. Summerfield, A.Q.: Some preliminaries to a comprehensive
account of audio-visual speech perception. In: Campbell, R.,
Dodd, B. (eds.) Hearing by Eye: The Psychology of Lip-Reading,
pp. 3–51. Lawrence Erlbaum, London, United Kingdom (1987)
5. Aleksic, P.S. Katsaggelos, A.K.: Audio-visual biometrics. IEEE
Proc 94(11), 2025–2044 (2006)
6. Chaudhari, U.V., Ramaswamy, G.N., Potamianos, G., Neti, C.:
Audio-visual speaker recognition using time-varying stream re-
liability prediction. IEEE Proc. Int. Conf. Acoustics Speech Sig-
nal Process. (Hong Kong, China) 5, V-712–15 (2003)
7. Hjelmas, E., Low, B.K.: Face detection: A survey. Computer
Vision. Image Understand. 83(3), 236–274 (2001)
8. Hennecke, M.E., Stork, D.G., Prasad, K.V.: Visionary speech:
Looking ahead to practical speechreading systems. In: Stork,
D.G., Hennecke, M.E. (eds.) Speechreading by Humans and
Machines, pp. 331–349. Springer, Berlin (1996)
9. Aleksic, P.S., Katsaggelos, A.K.: Comparison of low- and high-
level visual features for audio-visual continuous automatic
speech recognition. IEEE Proc. Int. Conf. Acoustics Speech
Signal Process. (Montreal, Canada) 5, 917–920 (2004)
10. Potamianos, G., Graf, H.P., Cosatto, E.: An image transform
approach for HMM based automatic lipreading. Paper presented
at the Proceedings of the International Conference on Image
Processing, vol. 1, pp. 173–177. Chicago, IL, 4–7 Oct. 1998
11. Wark, T., Sridharan, S., Chandran, V.: Robust speaker verifica-
tion via fusion of speech and lip modalities. Proc. Int. Conf.
Acoustics Speech Signal Process. Phoenix 6, 3061–3064 (1999)
12. Aleksic, P.S., Katsaggelos, A.K.: An audio-visual person identifi-
cation and verification system using FAPs as visual features.
Paper presented at the Proceedings of Works. Multimedia User
Authentication, pp. 80–84. Santa Barbara, CA (2003)
13. Cootes, T.F., Edwards, G.J., Taylor, C.J.: Active appearance mod-
els. Paper presented at the Proceedings of European Conference
on Computer Vision, pp. 484–498. Freiburg, Germany (1998)
Lip Movement Recognition
L
907
L
Lip-Radiation Effect
The lip-radiation effect corresponds to changing the
volume velocity waveform at the lips to a speech pressure
signal in a free field at a certain distance from the speaker.
▶ Speech Production
Liquid Crystal Displays (LCD)
Liquid crystal display (LCD) is a digital display that
uses liquid crystal cells whose reflectiv ity varies accord-
ing to the voltage applied to them. Liquid crystal is a
substance that flows like liquid but maintains some of
the ordered structure characteristic of the crystals.
▶ Digitizing Table t
Liveness Detection
▶ Fingerprint Fake Detection
▶ Liveness Iris
Liveness Assurance in Face
Authentication
MIC HAEL WAGN E R ,GIR IJA CHETTY
School of Information Sciences, University of
Canberra, Australia
Synonyms
Face authentication; Face recognition; Face verification
Definition
The process of verifying whether the face image pre-
sented to an authentication system is real (i.e., alive),
or whether it is reproduced or synthetic, and thus
fraudulent. When a face authentication system is to
recognize the face of a person by means of an electronic
camera and associated image recognition software, it is
important to be sure that the person seeking the au-
thentication actually presents his or her face to the
camera at the time and place of the authentication
request. The face is presented live as on live television
as distinct from a movie or cartoon programme. In
contrast, an impostor could try to present a photo-
graph, or a video recording, of a legitimate client to the
camera in order to be falsely authenticated by the
system as that client. That kind of threat to aut henti-
cation systems is known generally as
▶ replay attack.In
turn, liveness assurance uses a range of measures to
reduce the vulnerability of face authentication systems
to the threats of replay attack.
Introduction
The primary design objective for a face recognition
system is its ability to distinguish, as clearly as possible,
between different persons on the basis of their facial
images. As is described in detail in sections
▶ Face
Recognition, Overv iew, a good face recognition
system utilizes a suitable feature set, employs sophisti-
cated pattern recognition algorithms and sets decision
thresholds appropriate for the specific application
context. Nevertheless, current face recognition tech-
nology is vulnerable on several fronts: on one hand,
different persons like twins, especially identical twins,
other siblings, parents and children can have quite
similar facial appearance, while on the other hand the
same person can appear quite dissimilar at different
times owing to facial hair and hairstyle, make-up,
cosmetic surgery, eye glasses, and even just due to
their physical or emotional state. Figure 1 shows an
example of the faces of two identical twins being almost
indistinguishable and Fig . 2, in contrast, shows the
large difference between two images of the same person
who changed his facial app earance drastically. Face
recognition also has robustness issues unless environ-
ment variables such as lighting of the face and pose
with respect to the camera are controlled meticulously.
In addition, face authenticati on systems are vulner-
able to impostors who present a photograph of a
legitimate client to the system camera and may be
falsely accepted as that client by the system [1]. Gener-
ally, such an attack on a biometric authentication
908
L
Lip-Radiation Effect

system is known as a replay attack. Replay attacks can
be carried out by presenting a printed photograph to
the system camera or by holding a computer screen
showing a photo or video recording in front of the
camera. However, replay attacks are also possible by
injecting a suitable recorded signal or data file at other
points within the authentication system. All replay
attacks have in common that, at the time of the au-
thentication they play back to the system a signal that
was recorded from the client at an earlier time.
Liveness Assurance in Face Authentication. Figure 2 Dissimilarity of two facial images of the same person
(downloaded from http://news.bbc.co.uk).
Liveness Assurance in Face Authentication. Figure 1 Similarity of the facial images of two different persons
(downloaded from http://www.mary-kateandashley.com).
Liveness Assurance in Face Authentication
L
909
L