Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.

Closely related to the replay attack is another form
of attack on a face authentication system, namely
the
▶ synthesis attack. A synthesis attack does not use
a pre-recorded signal, such as a photograph or video of
a client, directly. Instead, it uses known client data to
build a client model, for example a three-dimensional
shape and texture model of the client’s head. From
such a model, entirely artificial photographs or video
sequences with or without speech sounds can be synthe-
sized, which can closely resemble the actual client.
Replay Attack
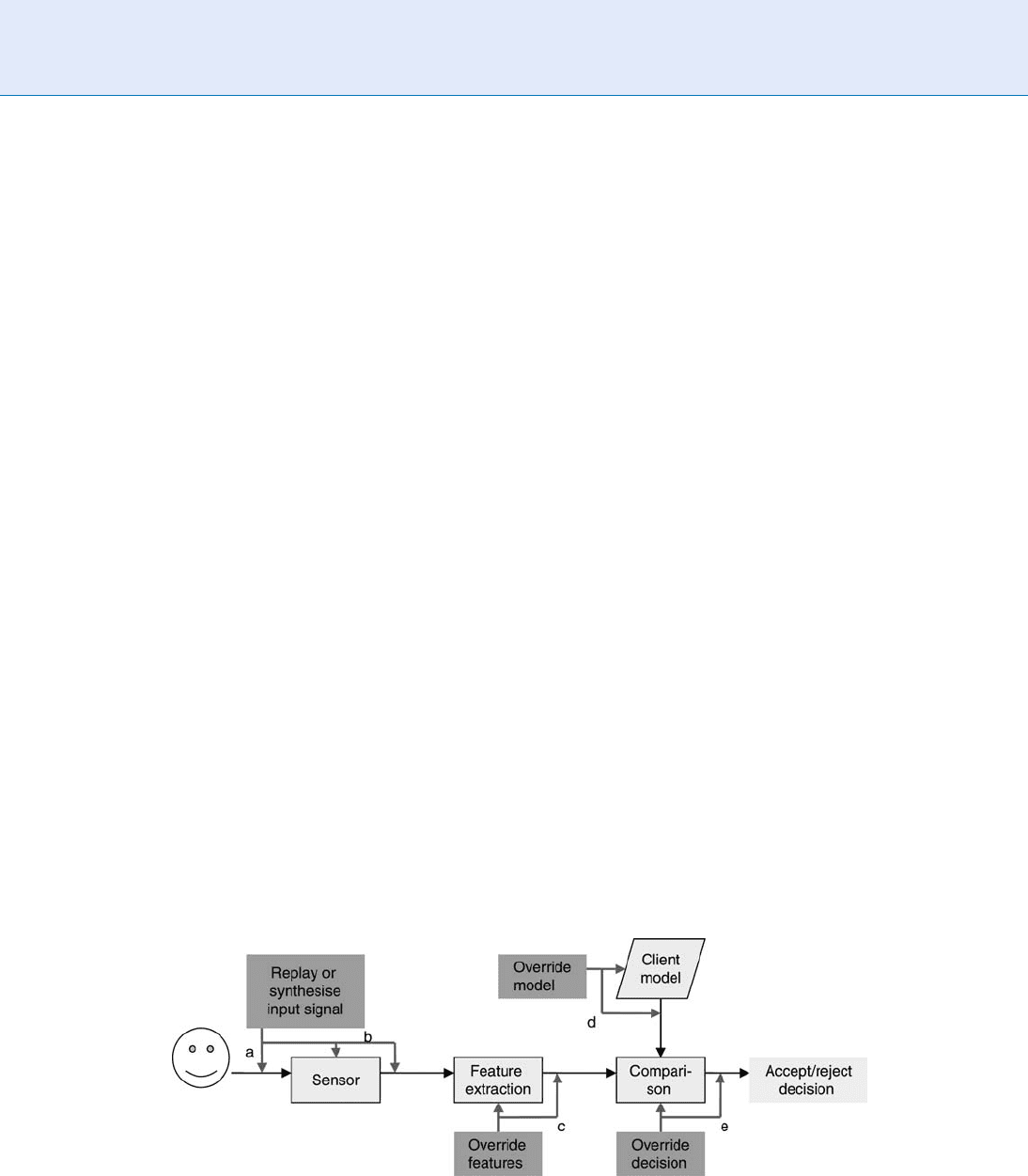
The different points at which a face recognition system
is vulnerable to replay attacks are shown in Fig. 3 .
An attacker can present a photograph or play back a
video of the face of a true client to the sensor, or
electronic camera, of the authentication system as
shown in Fig . 3(a). This point is the most vulnerable
in the authentication system because in a fully auto-
mated system, the possibility of presenting a photograph
is always available to an attacker unless the physical
space in front of the camera is supervised by a human
observer or by a second biometric modality in addition
to the facial image camera. If an attacker can gain access
to the inside of the camera or to the connection between
the camera and the back end of the system, as shown as
in Fig. 3(b), the attacker does not need to ‘‘show’’ a
physical photograph or video to the camera, but can
inject a suitable electronic signal that corresponds to the
facial image of the client into the system directly.
Since a face authentication system will invariably be
implemented as software running on a computer or
network of computers, such a system would be open to
the same threats as any other software, particularly
if it is connected to the Internet. The vulnerabilities
of computer systems to a range of threats, including
viruses, worms, Trojan Horses, or even more simply,
the disclosure or easy guess of passwords, are
well known and any biometric system is subject to
those same threats. Accordingly, if an attacker can
gain access to the face authentication system at or
beyond the feature extraction stage, as shown as in
Fig. 3c, the attacker can bypass the input of a facial
image altog ether and present the system with the
fake features of a client face. An attacker who is
able to access the stored client models of the system,
shown in Fig. 3d, will achieve the ultimate identity
theft by replacing the model of a real client with the
model of an impostor. This will have the effect that
forthwith the impostor will be falsely accepted by the
system as the client si nce the impostors face will,
of course, now be compared w ith the impostor’s own
facial model, which has been substituted for the model
of the real client.
The ultimate success for an attack of the face
authentication system lies in the attacker being able
to access the Comparison Module of the system, as
shown in Fig. 3e, since a breach of the system at that
point will enable the attacker to override the system
with his own accept or reject decision irrespective
of the face shown to the camera or the client model
that the face is compared with.
Liveness Assurance in Face Authentication. Figure 3 Potential points of vulnerability of a face authentication system:
(a) replay or synthesize the client facial image into the input sensor; (b) insert the replayed or synthesized client facial
image into vulnerable system-internal points; (c) override detected features at vulnerable system-internal points;
(d) override the client at vulnerable system-internal points; (e) override the accept/reject decision at vulnerable
system-internal points.
910
L
Liveness Assurance in Face Authentication

Liveness Assurance for Face
Authentication: Visual Sensors Only
Additional Infrared or Ultraviolet Sensors
Depending on the nature of the replay attack, different
methods of liveness assurance can be used. A still
photograph or a video presented to the system camera
as a paper print or on a computer screen will always
reflect the spectral sensitivity of the recording device.
Therefore, a system camera, which has a different spec-
tral sensitivity from that of an ordinary camera, for
example extending into either the infrared or ultravio-
let range of the spectrum, is able to distinguish a live
face from a photo or video recorded with an ordinary
camera. An infrared or ultraviolet camera can also be
employed as a secondary input device in addition to an
ordinary-spectrum camera [ 2]. Such secondary sen-
sors, which, for example, could show the temperature
profile of the face or the vein pattern underneath the
skin, are excellent liveness detectors, provided that
the training of the client models is undertaken with
the same sensor arrangement that is later used for
client authentication. However, the disadvantage of
such a sensor arrangement is that infrared and ultra-
violet sensors are expensive. Moreover, such sensors
cannot be used where the authentication system has
to rely on ordinary cameras such as webcams or
mobile phone cameras in a distributed authentication
system.
Detection of 3D Head Movement
Another method of distinguishing a live face from a
photograph or video is to ascertain that the face as it is
presented to the camera moves in a manner consistent
with the three-dimensional shape of the human head.
A rotation of a real human head in front of a camera
will reveal parts of the head that were obscured prior to
the rotation, while at the same time obscuring other
parts that were previously visible. This effect distin-
guishes the rotation of a real human head from the
rotation of a photograph or image on a computer
screen. More gen erally, the positions of facial ‘‘land-
marks,’’ such as pupils, nose tip, or mouth corners of a
three-dimensional head – and hence the distances
between such landmarks – will follow the rules of
three-dimensional trigonometry and as such can
be distinguished clearly from rotations of a two-
dimensional photo graph or computer screen.
The detection of a three-dimensional head can be
achieved either by utilising a stereo camera – or several
cameras looking at the head from different directions –
or by taking a sequence of images of the moving
head through a single camera. In the first case, the
presentation of a two-dimensional photograph or
computer screen is immediately obvious, while in
the second case the system can either make use
of inadvertent small rotations of the client’s head or
explicitly ask clients to rotate their heads in a pre-
scribed manner.
An example of a system, which uses an image
sequence collected by a single camera in order to detect
three-dimensional head movements, is described by
Kollreider et al. [3]. The system is bas ed on the obser-
vation that the two-dimensional image of a head ro-
tating around its vertical axis shows significant lateral
movement in the centre of the face while the ears,
forehead, and chin move mostly in directions per pen-
dicular to the projection. Optical flow estimation
▶ Face Recognition, 3D-Based and face part detection
are used to measure and compare the movements of
the nose and the ears, respectively, across an image
sequence of a rotating head. If the lateral movement
of the nose over the time span of the image sequence
is larger than the lateral movement of the ears, it is
assumed that a real head is rotating in three dimen-
sions rather than a two-dimensional image being
turned in front of the camera. By an appropriate
threshold on the difference of the horizontal pixel
velocities be tween the nose region and the ear
regions, video sequences of a three-dimensional rotat-
ing human head are distinguished from those of a
two-dimensional rotated photograph. Figure 4a
shows three frames of a head rotation sequence, and
Fig . 4(b) shows the corresponding optical flow
diagram.
Detection of Facial Micro-Movement
Another possibility to distinguish a live face from a
photograph is based on the assumption that an image
sequence of a live face w ill invariably show some varia-
tion of facial features. This is obviously the case when
the person is speaking and there is facial variation,
mainly in the mouth region, which corresponds to
Liveness Assurance in Face Authentication
L
911
L

the speech sounds being produced. Under an assump-
tion that a person will always exhibit some eye move-
ment over time, it is possible to distinguish a live face
from a photograph by comparing the eye regions be-
tween consecutive frames of a video sequence. A sys-
tem, which utilizes inadvertent eye movements to
distinguish between a live face and a photograph is
proposed by Jee et al. [4]. The system uses five sequen-
tial face images, then detects the centre points of both
eyes in order to extract the two eye regions. For each
of the eye regions, the 20 10 pixels of that region are
1-bit quantized to be either black or white and
Hamming distances are calculated between the five con-
secutive images of each eye region. Figure 5(a) shows the
sequences of five black and white frames for the eye
regions of still photographs, while Fig. 5(b) shows
frame sequences of the eye regions of live faces.
The figu re clearly shows a larger variation of the eye
regions of the live faces than of the still photos. Accord-
ing to Jee et al. [4], live images can be distinguished
from photographs because the average Hamming dis-
tance between the five images of a sequence is always
larger for a live face than for a still photograph pre-
sented to the cam era.
Liveness Assurance in Face Authentication. Figure 5 ( a)
Five consecutive video frames of eye regions from still
photos; (b) five consecutive video frames of eye regions
from live faces. Pixels are 1-bit quantized to black or white
([4] Courtesy World Academy of Science, Engineering
and Technology.)
Liveness Assurance in Face Authentication. Figure 4 (a) Image sequence of rotating head; (b) horizontal optical
flow magnitude showing higher pixel velocities (white) for the central area and lower pixel velocities for the peripheral
areas of the face. ([3] ß 2005 IEEE.)
912
L
Liveness Assurance in Face Authentication

Challenge-Response Paradigm
In addition, it is possible for the authentication system
to issue a ‘‘challenge’’ to the persons seeking authenti-
cation by asking them to perform some specific pre-
scribed movement, for example ‘‘tilt head to the left’’
or ‘‘blink with your right eye’’ as proposed in the Facial
Liveness Assessment System [2]. Such system requests
are akin to the prompted-text paradigm in speaker
recognition (
▶ Liveness Assurance in Voice Authenti-
cation). They provide a good defence against replay
attack, but on the system side it is necessary to design
and implement an automatic mechanism, which is able
to reliably confirm the correctness of the client’s re-
sponse to the system prompt.
Vulnerability to Replayed Video
Recordings
The above liveness assurance methods provide protec-
tion against forms of replay attack that present a
recorded image of a client’s face to the system camera.
If the attacker uses printed photographs or photo-
graphs displayed on a computer screen, particularly
on the display of an easily portable notebook computer,
all of these methods provide good distinction between
a replay attack and a client face that is presented live to
the camera. However, an attacker who is able to pres-
ent a client photograph to the system on a notebook
screen, is also likely to be capable of replaying a
recorded video sequence on such a notebook. In this
case, the single-camera 3D detection method will fail
to detect a replay attack because the recorded video
sequence has the same three-dimensional rotation
characteristic as a human head rotated live in front of
the system camera. Similarly, the detectio n of micro-
movements would fail because the video recording
contains the same facial micro-movements of the
lip and eye regions as a human face presented live
to the camera. The only system architecture that is
capable – without the presence of a human supervisor –
of distinguishing between a two-dimensional video
presentation and a three-dimens ional live presentation
of a human face, is one that has a three-dimensional
sensor arrangement with a set of cameras surrounding
the head of the client and/or obtaining a wide-angle
view of the scene, and as such is able to ‘‘look behind’’
a two-dimensional printed photograph or notebook
computer held before the cameras.
Multimodal Liveness Assurance
While it is feasible to deceive a single-camera system by
replaying a video recording on a notebook, held in
front of the camera, it is far more difficult to use the
same notebook to deceive an acoustic speaker recogni-
tion system by replaying a sound recording through
the notebook’s in-built speakers or another small loud-
speaker. From the point of view of attackers, there are
several obstacles: firstly they must not be detected
holding a computer screen in front of the camera;
secondly they must provide a high-quality loud-
speaker, which is usually bulky and not normally
found in notebook computers; and thirdly they have
to play back a recorded video with perfectly synchro-
nous facial images and speech sounds. Therefore, a
multimodal approach to liveness assurance has been
proposed, which combines the recognition of a client’s
face with the recognition of the client’s voice [5]. In a
combined face-voice authentication system it is possi-
ble to verify not just that there are some – random –
micro-movements in the lip area of the face, but that
those lip movements correspond precisely to the
speech sounds that are heard simultaneously by the
system microphone. For example, the labial consonant
/p/ in ‘‘Paris’’ would correspond to a closing followed
by an opening of the lips, while the rounded vowels /u/
in ‘‘Toulouse’’ would correspond to a rounded lip
configuration.
More generally, the assurance of liveness in a bi-
modal face-voice authentication system is based on the
fact that the articulator movements, mainly of the lips,
but also of the tip of the tongue, jaw, and cheeks are
mostly observable and correspond closely to the par-
ticular speech sounds produced. Therefore it is possi-
ble when observing a bimodal audio-video signal of
the speaking face to ascertain whether the facial dy-
namics and the sequence of speech sounds are mutu-
ally compatible and synchronous. Human observers
are finely tuned to the synchrony of acoustic and visual
signal and it is quite disconcerting when one or the
other is delayed or there is no apparent match, for
example, with an out-of-s ync television signal or w ith
a static facial image when the speaker is heard saying
Liveness Assurance in Face Authentication
L
913
L

something, but the lips are not seen to be moving.
In the field of audiovisual speech recognition, the
term ‘‘viseme’’ has been coined as the visual counter-
part of the ‘‘phoneme,’’ which denotes a single spe ech
sound
▶ Speaker Recognition, Overview. This is illu-
strated in Fig. 6, whi ch shows a set of corresponding
phonemes and visemes of English. The visemes /m/,
/u/, and /d/ (as in the word ‘‘mood’’), for example, first
show the speaker’s lips spread and closed (for /m/),
then protruded and rounded (for /u/), and finally
spread and slightly open (for /d/). It is therefore possi-
ble to detect whether corresponding sequences of
visemes and phonemes of an utterance are observed
in a bimodal audio-video signal and whether the
observed viseme and phoneme sequences are
synchronous.
In order for the synchrony of the audio and video
streams to be ascer tained, the two modalities must be
combined appropriately. Multimodal authentication
systems employ different paradigms to combine, or
‘‘fuse,’’ informati on from the different modalities. Mo-
dality fusion can happen at different stages of the
authentication process. Fusing the features of the dif-
ferent channels immediately after the feature extrac-
tion phas e is known as ‘‘feature fusion’’ or ‘‘early
fusion.’’ In this paradigm, all comparisons between
the unknown sample and the client model as well as
the decision making are based on the combined feature
vectors. The other possibility is to fuse information
from the two modalities after independent compari-
sons have been made for each modality.
For liveness assurance by means of bimodal face-
voice authentication, it is necessary to apply an early
fusion stratagem, i.e., to fuse the two modalities at the
feature level [6]. If the two modalities were to be fused
late, i.e., at the score or decision level, analysis of the
video of the speaking face would yield one decision on
the speaker’s identity and analysis of the audio of the
utterance would yield another decision on the speaker’s
identity. The two processes would run independently of
each other with no connection between them that
would allow the checking for the correspondence and
synchrony of visemes and phonemes [7].
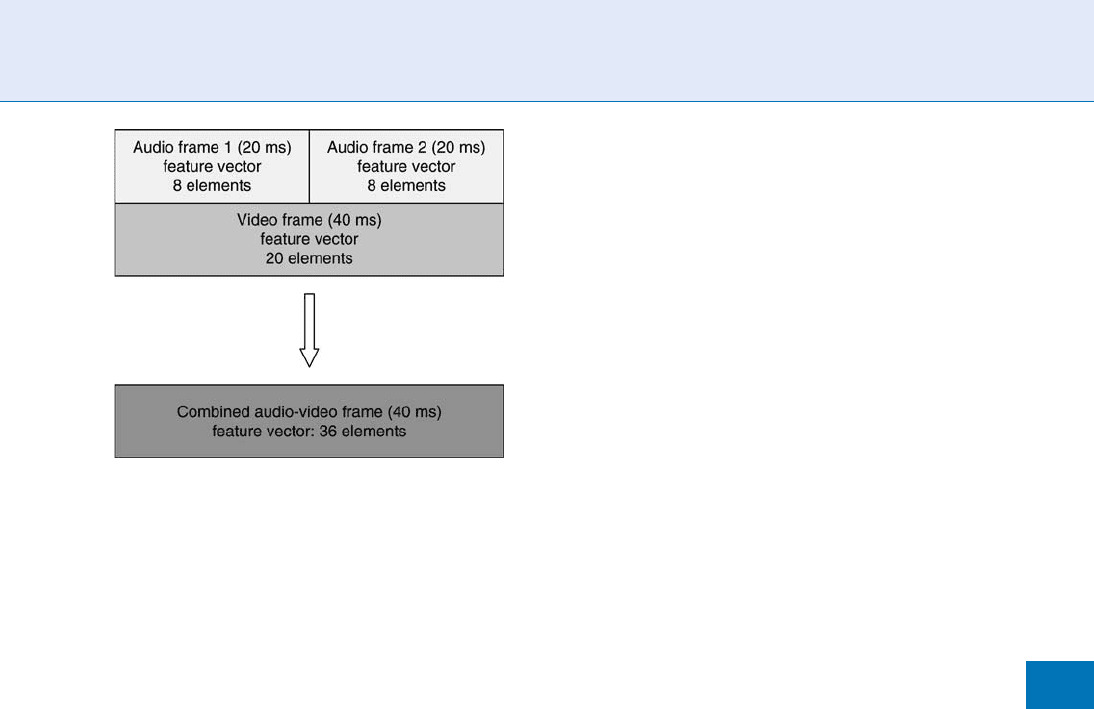
Therefore, the features that are extracted from the
audio signal on a frame-by-frame basis – usually at an
audio frame rate of about 40–100 frames per second –
must be combined with the features that are extracted
from the video signal – usually at the video frame rate of
25 or 30 frames per second. An example of how the
differing frame rates for the audio and video signals can
be accommodated is shown in Fig. 7, where the audio
frame rate is 50 frames per second, the video frame rate
is 25 frames per second, a nd the combined audiovisual
feature vector comprises the audio feature vectors of
two consecutive audio frames, combined with the sin-
gle video vector of the synchronous video frame.
The combined audiovisual feature vectors will then
reveal whether the audio and video streams are syn-
chronous, for example when the combined audiovisual
feature vectors contain the sequence of visemes /m/,
/u/, and /d/ and likewise the sequence of phonemes /m/,
/u/, and /d/. In contrast, if one of the combined audio-
visual feature vectors were to contain the visual infor-
mation for the viseme /m/ and at the same time the
Liveness Assurance in Face Authentication. Figure 6
Visemes and their corresponding phones.
914
L
Liveness Assurance in Face Authentication
audio information for the phoneme /u/, that combined
feature vector would indicate that the audio and v ideo
streams do not represent a corresponding synchronous
representation of any speech sound.
The proper sequencing of visemes and phonemes is
usually ascertained by representing the audiovisual
speech by Hidden Markov Models (HMM), which
establish the likelihoods of the different combined
audiovisual vectors and their sequences over time [8].
It is therefore possible to ascertain whether the audio
and video components of a combined audio-video
stream represent a likely live utterance. Therefore, an
attacker who attempts to impersonate a target speaker
by means of a recorded speech utterance and a still
photograph of the target speaker will be thwarted
because the system will recognize the failure of the
face to form the corresponding visemes that should
be observed synchronously with the phonemes of the
utterance. Similarly, such a system will thwart an attack
by an audiovisual speech synthesis system, unless the
synthesizer can generate the synthetic face and the
synthetic voice in nearly perfect synchrony.
The combination of face aut hentication with voice
authentication has a number of advantages beyond the
assurance of the liveness of the face-voice samples.
Firstly, the method is well supported by telecommuni-
cation devices, which are increasingly equipped with
image and sound sensors that are capable of delivering
facial images and voice samples suitable for remote
client authentication. Secondly, the combination of
two largely – but not completely! – independent
biometrics has an advantage in terms of error rates
compared with either modality employed singly.
And thirdly, the utilisation of combined image and
sound signals has a distinct advantage in robustness
when the environmental conditions are adverse to
either the face recognition system or the speaker rec-
ognition system, for example when lighting conditions
are not conducive to successful face recognition, or
when a passing train makes speaker recognition all
but impossible.
Related Entries
▶ Face Recognition, 3D Based
▶ Face Recognition, Over view
▶ Liveness: Detection Voice
▶ Optical Flow
▶ Speaker Recognition, Overview
References
1. Schuckers, S.A.C.: Spoofing and anti-spoofing measures, Infor-
mation Security Technical Report. 7(4), 56–62 (2002)
2. Facial liveness assessment system, Int. Patent WO/2005/008566,
http://www.wipo.int (27.1.2005)
3. Kollreider, K., Fronthaler, H., Bigun, J.: Evaluating liveness by
face images and the structure tensor. In: Proceedings of the
Fourth IEEE Workshop on Automatic Identification Advanced
Technologies, 17–18 Oct 2005. IEEE (2005)
4. Jee, H.-K., Jung, S.-U., Yoo, J.-H.: Liveness detection for embed-
ded face recognition system. In: Proceedings of World Academy
of Science, Engineering and Technology, vol. 18, Dec 2006, ISSN
1307–6884 (2006)
5. Chetty, G., Wagner, M.: ‘‘Liveness’’ verification in audio-video
authentication. In: Proceedings of the International Conference
on Spoken Language Processing, ICSLP-2004, Jeju, Korea, 4–7
Oct 2004, vol. III, pp 2509–2512 (2004)
6. Chetty, G., Wagner, M.: Investigating feature level fusion for
checking liveness in face voice authentication. In: Proceedings
of the Eighth International Symposium on Signal Processing and
Its Applications, Sydney, 28–31 Aug 2005 (2005)
7. Bredin, H., Chollet, G.: Audiovisual speech synchrony measure:
application to biometrics. EURASIP J. Adv. Signal Process. 2007
(1), 1–11 (2007)
8. Chetty, G., Wagner M.: Speaking faces for face-voice
speaker identity verification. In: Proceedings of Interspeech-
2006 – International Conference on Spoken Language Proces-
sing, Paper Mon3A1O-6, Pittsburgh. International Speech
Communication Association (2006)
Liveness Assurance in Face Authentication. Figure 7
Feature fusion of two consecutive 20 ms audio feature
vectors with the corresponding 40 ms video feature
vector. Before fusion, the audio vectors have been reduced
to 8 dimensions each, and the video vector has been
reduced to 20 dimensions. The combined feature vector
has 36 dimensions [5].
Liveness Assurance in Face Authentication
L
915
L
Liveness Assurance in Voice
Authentication
MIC HAEL WAGN E R
School of Information Sciences, University of
Canberra, Australia
Synonyms
One-to-One Speaker recognition; Speaker verification;
Voice authentication; Voice verification
Definition
The process of verifying whether the voice sample
presented to an authentication system is real (i.e.,
alive), or whether it is replayed or synthetic, and thus
fraudulent. When authentication through a
▶ voice
authentication system is requested, it is important to
be sure that the person seeking the authentication
actually provides the required voice sample at the
time and place of the authentication request. The
voice is presented live like that of a radio presenter
during a live broadcast as distinct from a recorded
audio tape. In contrast, an impostor who seeks authen-
tication fraudulently could try to play an audio record-
ing of a legitimate client or synthesized speech that is
manufactured to resemble the speech of a legitimate
client. Such threats to the system are known as
▶ replay
attack and
▶ synthesis attack , respectively. ▶ Liveness
assurance uses a range of measures to reduce the vul-
nerability of a voice aut hentication system to the
threats of replay and synthesis attack.
Introduction
The security of a voice authentication system depends
on several factors
▶ Voice Authentication. Primarily it
is important that the system is capable of distinguish-
ing people by their voices, so that a clients who are
enrolled in, say, a telephone banking system are admit-
ted to their account reliably, while an ‘‘impostor’’ who
attempts to access the same account is rejected equally
reliably. A good voice authentication system will
thwart an impostor irrespective of whether the access
to the other person’s account is inadvertent or deliber-
ate and irrespective of whether the impostors use their
natural voice or try to improve their chances by mim-
icking the voice of the client.
However, one vulnerability common to all voice
authentication systems is the possibility that attackers,
instead of speaking to the system directly and with
their own voice, fraudulently use the recorded voice
of a true client in order to be admitted by the system.
In principle, such a ‘‘replay attack’’ can be carried out
by means of any sound recording device, analogue or
digital, through which the recorded voice of the client
is played back to the system, say, to a microphone at a
system access point or remotely into a telephone hand-
set connected to the authentication system. The secu-
rity issue in this case is that the voice used for
authentication is not the ‘‘live’’ voice of the person,
who is seeking access to the system, at the time and
place of the access request.
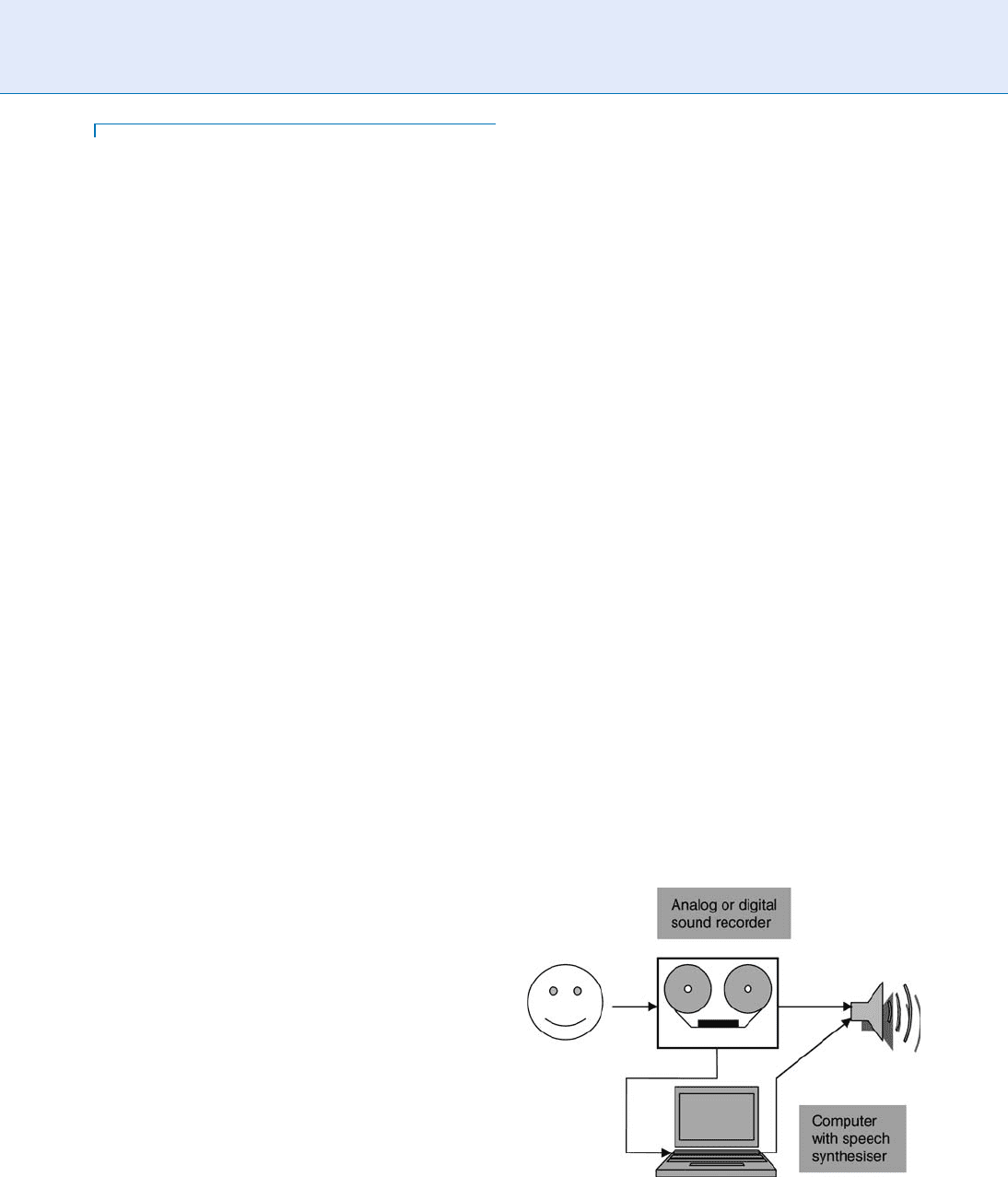
A technically sophisticated attacker may also use suit-
able computer hardware and software to create a simile of
the client’s voic e by means of speech synthesis without
having to record specific voic e samples of the client. Such
an attack will be referr ed to as a ‘ ‘ synthesis attack’ ’ in the
following. Figure 1 shows how replayed or synthesized
voice signals can be substituted for the live voice of a
client at the sensor input of the authentication system.
Replay Attack
Since voice authentication is always implemented
within the context of a computer system, it is
Liveness Assurance in Voice Authentication. Figure 1
Prerecording of client voice either for later replay or for
generating a client model, which can be used later to
synthesize the client’s voice.
916
L
Liveness Assurance in Voice Authentication
important to consider the vulnerabilities of the
entire system generally (
▶ Security and Liveness,
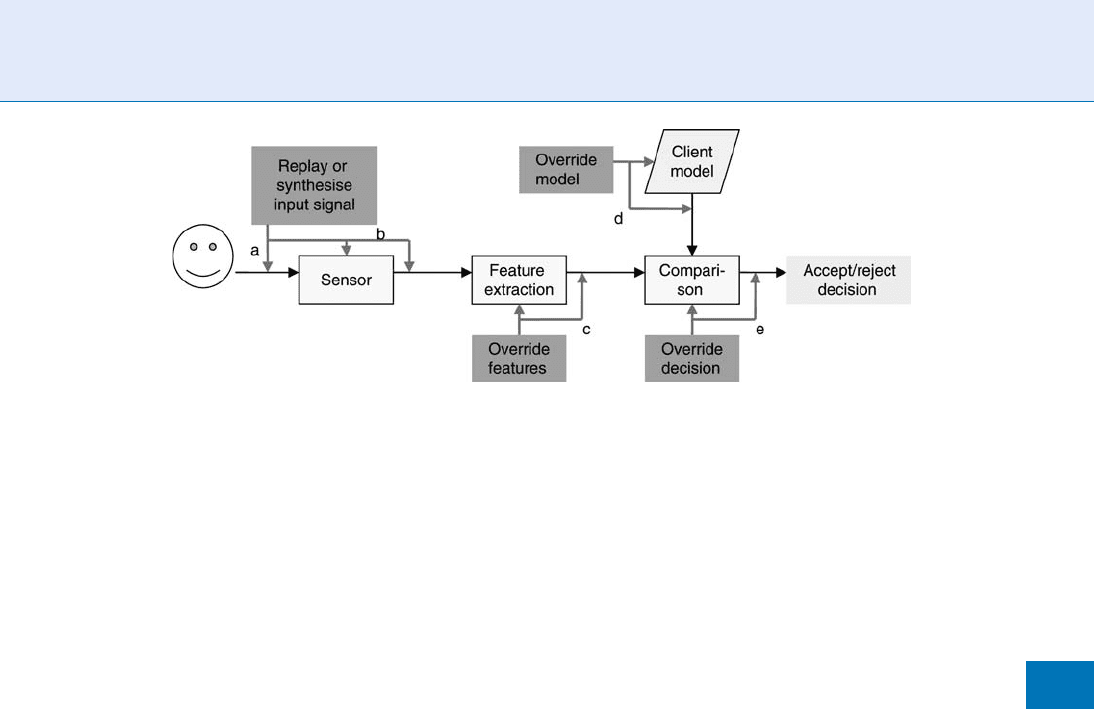
Overview). Figure 2 shows the structure of a typical
voice authentication system. During the enrolment or
training phase, the client’s voice is captured by the
microphone, salient features are extracted from the
speech signals and finally a statistical ‘‘client model’’
or template is computed, which represents the client-
specific voice characteristics according to the speech
data collected during enrolment. During the opera-
tional or testing phase when the system needs to
decide whether a speech sample belongs to the
client, the signal is also captured by the sensor and
features are extracted in the same way as they are in the
enrolment phase. Then, the features of the unknown
speech sample are compared statistically with the
model of the client that was established during enrol-
ment. Depending on how close the unknown sample
is to the client model, the system will issue either an
‘‘accept’’ or a ‘‘reject’’ decision: the person providing
the voice sample is either authenticated or considered
an impostor.
Figure 2 shows various ways in which attackers
could manipulate the outcome of the authentication,
if any of the software or hardware components of an
insecure computer system could be accessed. If it were
possible, for example, to manipulate the database of
client models, attackers could potentially replace the
voice model of a client w ith their own voice model and
subsequently gain fraudulent access to the system by
having substituted their own identity for that of the
client. Or, even more simply, if it were possible to
manipulate the decision module of the system, an
attacker could essentially bypass the entire authentica-
tion process and manufacture an ‘‘accept’’ decision of
the system without having provided any matching
voice data. Such considerations fall into the domain
of the system engineer who needs to ensure, much as
with any other secure system, that there are no bugs,
trap doors, or entry points for Trojan Horses, which
could allow an attacker to manipulate or bypass the
authentication mechanism s of the system. Since such
vulnerabilities are not specific to voice authentication
systems, they are not dealt with in this essay (
▶ Bio-
metric Vulnerabilities: Overview).
The remainder of this article discusses how a secure
voice authentication system can provide the assurance
that the voice used for an access request to the system is
‘‘live’’ at the time and place of the access request and is
neither a playback of a voice recording nor a synthe-
sized simile of a client voice. Hence, liveness assurance
is an essential aspect of the security of any voice au-
thentication system.
Liveness Assurance for Different
Authentication Protocols
Voice authentication systems operate under different
protocols and assurance of liveness is affected differ-
ently by the various authentication protocols. The three
main protocols used for voice authentication are
text-dependent speaker verification, text-independent
speaker verification, and text-prompted speaker
Liveness Assurance in Voice Authentication. Figure 2 Potential points of vulnerability of a voice biometric
authentication system: (a) replay or synthesize the client voice into the input sensor; (b) insert the replayed or synthesized
client voice into vulnerable system-internal points; (c) override detected features at vulnerable system-internal points;
(d) override the client at vulnerable system-internal points; (e) override the accept/reject decision at vulnerable
system-internal points.
Liveness Assurance in Voice Authentication
L
917
L
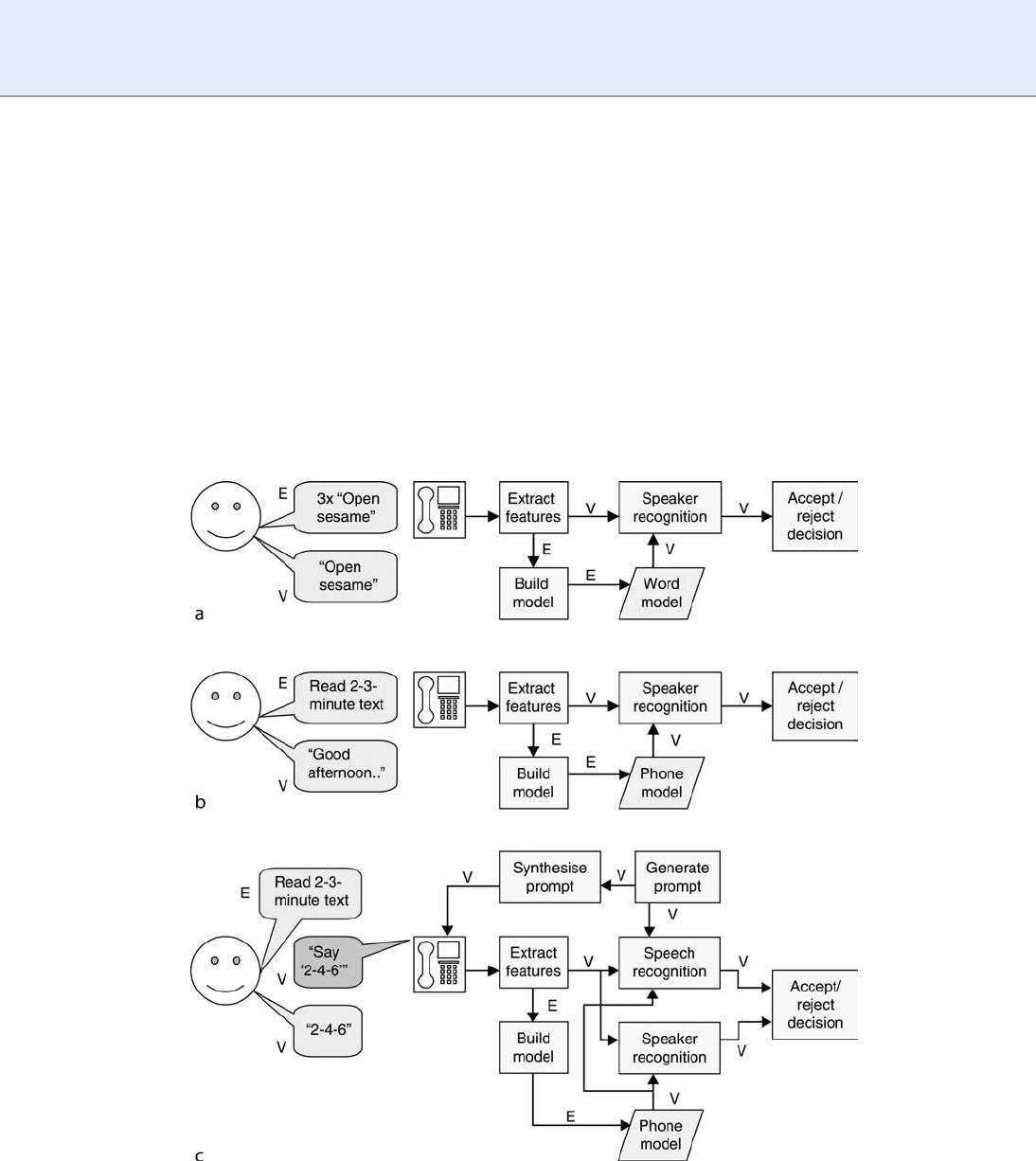
verification, as shown in Fig. 3. The earliest authenti-
cation protocol were text-dependent [1]. In this pro-
tocol, the client uses a fixed authentication phrase,
which is repeated several times during enrolment. The
repetitions are necessary so that the system ‘‘learns’’
about the range of pronunciation of the authentication
phrase by the client. Generally, speaker verification
works best if the natural variation of a speaker’s voice
is well captured during enrolment. Hence, ideally, en-
rolment should be distributed over several recording
sessions that may be spread over several days or even
weeks. The same phrase, for example, a sequence of
digits (‘‘three-five-seven-nine’’), or a password or
passphrase (‘‘Open Sesame’’) is then used again by the
client during the operational phase in order to be
authenticated by the system.
Text-dependent systems have the advantage that
the client model only needs to represent the ac oustic
information related to the relativ ely few speech sounds
of the passphrase. Enrolment, therefore, is shorter
and quicker than for other protocols, which typically
require the representation of the entire collection of
speech sounds that the client could possibly produce.
However, the text-dependent protocol has the distinct
disadvantage that clients will repeat the same phrase
every time while using the system. Consequently, there
Liveness Assurance in Voice Authentication. Figure 3 (a) Text-dependent voice authentication: (E) at enrolment
the client repeats the authentication phrase several times; (V) for verification the client speaks the same authentication
phrase. (b) Text-independent voice authentication: (E) at enrolment the client reads a 2–3-min phonetically-rich text;
(V) for verification any utterance can be used by the client. (c ) Text-prompted voice authentication: (E) at enrolment the
client reads a 2–3-min phonetically rich text; (V) for verification the client is prompted to say a given phrase, which is
verified both for the correct content and for the client’s voice characteristics.
918
L
Liveness Assurance in Voice Authentication

may be ample opportunity for an attack er, especially if
the system microphone is situated in a public area, to
plan and carry out a surreptitious recording of the pass-
phrase, uttered by the client, and to replay the recorded
client passphrase fraudulently in order to be authorized
by the system.
In contrast, text-independent voice authentication
systems [2] will aut henticate a client – and reject an
impostor – irrespective of any particular utterance
used during enrolment. Client enrolment for text-
independent systems invariably takes longer than en-
rolment for a text-dependent system and usually
involves a judiciously designed enrolment text, which
contains all, or at least most, of the speech sounds of
the language. This will ensure that the client models,
which are constructed from the enrolment speech data,
will represent to the largest extent possible the idio-
syncrasies of the client when an ar bitrary sentence or
other utterance is provided for authentication later.
Text-independent protocols offer the advantage that
authentication can be carried out without the need
for a particular passphrase, for example, as part of an
ordinary interaction between a client and a customer-
service agent or automated call centre agent, as shown
in this fictitious dialog:
Client phones XYZ Bank.
Agent: Good morning, this is XYZ Bank. How can I
help you?
Client: I would like to enquire about my account
balance.
Agent: What is your account number?
Client: It’s 123-4567-89
Agent: Good morning, Ms Applegate, the balance
of your account number 123-4567-89 is $765.43. Is
there anything else...?
The example shows a system, which combines speech
recognition with voice authentication. The speech rec-
ognizer understands what the customer wants to know
and recognizes the account number, while the authenti-
cation systems uses the text-independent protocol to
ascertain the identity of the client from the first two
responses the client gives over the telephone. These
responses would not normally have been encountered
by the system during enrolment, but the coverage of the
different speech sounds during enrolment would be
sufficient for the authentication system to verify the
client from the new phrases. The text-independent pro-
tocol offers an attacker the opportunity to record any
client utterances either in the context of the client
using the authentication system or elsewhere, and to
replay the recorded client speech in order to fraudu-
lently achieve authenticati on by the system.
A more secure variant of the text-independent pro-
tocol is the text-prompted protocol [3]. Enrolment
under this protocol is simil ar to the text-independent
protocol in that it aims to achieve a comprehensive
coverage of the different possible speech sounds of
a client so that later on any utterance can be used
for client authentication. However, during authenti-
cation the text-prompted protocol asks the user to
say a specific, randomly chosen phrase, for example,
by prompting the user ‘‘please say the number se-
quence ‘two-four-six’’’. When the client repeats the
prompted text, the system uses automatic speech rec-
ognition to verify that the client has spoken the correct
phrase. At the same time it verifies the client’s voice by
means of the text-independent voice authentication
paradigm. The text-prompted protocol makes a replay
attack more difficult because an attacker would
be unlikely to have all possible prompted texts from
the client recorded in advance. However, such
an attack would still be feasible for an attacker with
a digital playback device that could construct the
prompted text at the press of a button. For example,
an attacker who has managed surreptitiously to record
the ten digits ‘‘zero’’ to ‘‘nine’’ from a client – either on
a single occasion or on several separate occasions –
could store those recorded digits on a notebook com-
puter and then combine them to any prompted digit
sequence by simply pressing buttons on the computer.
Synthesis Attack
Even a text-prompted authentication system is vulner-
able to an attacker who uses a text-to-speech (TTS)
synthesizer. A TTS system allows a user to input any
desired text, for example, by means of a computer
keyboard, and to have that text rendered automatically
into a spoken utterance and output through a loud-
speaker or another analog or digital output channel.
The basic principle is that an attacker would program a
TTS synthe sizer in such a way that it produces similar
speech patterns as the target speaker. If that is achieved,
the attacker would only need to type the text that is
required or prompted by the authentication system in
order for the TTS synthesizer to play the equivalent
synthetic utteran ce to the authentication system in the
Liveness Assurance in Voice Authentication
L
919
L