Kallen A. Understanding Biostatistics
Подождите немного. Документ загружается.


90 THE ANATOMY OF A STATISTICAL TEST
Box 4.1 Calibrating a screening test based on costs
How should we choose the cut-off point for a diagnostic test? One approach is to use
the expected cost C of the test, which can be computed from
C = c
0
+ c
TS
P(TS) + c
T
c
S
P(T
c
S) + c
TS
c
P(TS
c
) + c
T
c
S
c
P(T
c
S
c
),
where T denotes a positive test, S means that there is a signal, c
0
is some overhead
cost, and the remaining coefficients c
XY
represent the costs for the events XY. The cost
C should not only be monetary, but also include patient discomfort and other aspects,
though they need to be given a price tag.
Introducing conditional probabilities and after some algebra, we can rewrite C as
C = c
0
+ c
TS
P(T |S)P(S) + c
T
c
S
P(S) − c
T
c
S
c
P(T |S
c
)P(S
c
) + c
T
c
S
c
P(S
c
),
where we have introduced the cost differences
c
TS
= c
TS
− c
T
c
S
,c
T
c
S
c
= c
T
c
S
c
− c
TS
c
.
The ROC curve is such that if x = P (T |S
c
), then ROC(x) = P(T |S). We therefore have
the cost as a function of x:
C(x) = c
0
+ (c
TS
ROC(x) + c
T
c
S
)P(S) − c
T
c
S
c
x + c
T
c
S
c
)P(S
c
).
The best test should be the one when this is at a minimum, which occurs when C
(x) = 0.
The condition for this is that
ROC
(x) =
c
T
c
S
c
c
TS
P(S
c
)
P(S)
,
which means that we should find the point on the ROC curve for which the slope equals
what is at the right-hand side. We see that the right-hand side is inversely proportional to
the odds for the disease, so for a rare disease we need a point with a steep gradient, which
means being close to the origin in Figure 4.1. We must minimize our false positives,
even at the expense of missing true positives.
may lead to an earlier diagnosis, not all screening tests have been shown to benefit the person
being screened; over-diagnosis, misdiagnosis, and creation of a false sense of security are
some potential adverse effects of screening. With respect to prostate cancer screening, it has
been observed in autopsy studies that a high proportion of men, who have died for other
reasons, have prostate cancer when the prostate is examined under a microscope. This has
led some to conclude that ‘most men die with prostate cancer, not from it’, though the jury is
still out. Therefore screening is not as uncontroversial as it may appear at first; while some
types of screening are helpful – measuring blood pressure may be an example – others may
be harmful. What are the issues involved?
Once the diagnostic test is defined, the population will be divided into four groups
which can be described in a 2 × 2 table, based on whether they have the disease or not, and
whether the test is positive or negative. We denote a positive test by T (so a negative test
is T
c
), and the situation where the subject actually has the disease by S (so absence of the
THE LAW: A NON-QUANTITATIVE ANALOGUE 91
disease is denoted by S
c
). The terminology introduced in the previous section is that the
probability P(T |S) (the test is positive if the subject has the disease) is the test sensitivity,
whereas the probability P(T
c
|S
c
) (the test is negative in a subject without the disease) is the
test specificity.
Specificity and sensitivity may be interesting properties of the test, but what matters to
the individual is how likely it is that he has the disease, when the test is positive (in fact, also
if the test is negative). This probability, P(S|T ), is called the predictive value of the test. The
test does good for the subject if it correctly predicts that he has the disease (provided that this
information is useful to have). The test is bad for the subject when it wrongly says that he has
the disease. In that case he or she may undergo some risky surgery or treatment unnecessarily.
From the perspective of the individual, a large predictive value is the key ingredient of a
screening test.
However, the predictive value of a screening test is not computable from knowledge of the
sensitivity and specificity alone. It also requires knowledge about the disease prevalence; the
proportion in the population with the disease. Let us continue the example with the serum GT
test using a cut-off limit of 2 .1 μkat/L as a screening test for alcoholism. Recall that the test had
a sensitivity of 0.45, meaning that 45% of all alcoholics have a positive test, and a specificity
of 0.90, meaning that only 10% of non-alcoholics end up with a positive test. Now assume that
we have 10% alcoholics in the population. To compute the predictive value, consider a sample
of 1000 people from the population. We expect 100 of them to be alcoholics, contributing 45
positive tests. At the same time we have 900 non-alcoholics, contributing 90 positive tests. It
follows that only one third of the positive tests come from the alcoholics. From the perspective
of the screened individual, there is a fair risk that the wrong conclusion is drawn.
Under the same assumption, we can compute the probability that the subject is not an
alcoholic if the test is negative. Arguing as above, our 1000 subjects produce 55 negative tests
among the alcoholics and 0.9 · 900 = 810 among the non-alcoholics, so the likelihood that a
negative test comes from someone who is not alcoholic is 810/(810 + 55) = 0.94. In other
words, among the people with a negative test we find only 6% alcoholics, those who were
missed by the test.
For these reasons a test used in a screening program, especially for a disease with low
incidence, must have good specificity in addition to acceptable sensitivity. But even that may
not be sufficient. Suppose that we have a test for a particular drug, say a narcotic, that has
both a specificity and a sensitivity of 99%. If a big company starts to test all its employees
for this drug, a drug that is actually used by only 1% of them, we see that for a subject with
a positive test, there is only a 50–50 chance he actually is a drug user. Is that an acceptable
false-positive rate? The calculations performed above are formalized in mathematical terms
in what is called Bayes’ theorem (see Box 4.2), and which forms the foundation of Bayesian
statistics (to be discussed later in this chapter).
4.4 The law: a non-quantitative analogue
What is the counterpart of all this for the legal problem? In the law setting the test diagnostic is
some measure of ‘appearance of guilt’. If this could be quantified, it would have a distribution
in the population. Innocent people may appear guilty to some degree; they may just happen
to be in the wrong place at the wrong time, or they can have a history of similar crimes. The
amount of guilt appearance therefore varies between individuals and defines a distribution

92 THE ANATOMY OF A STATISTICAL TEST
Box 4.2 Bayes’ theorem
In 1763 an essay with the title An Essay towards Solving a Problem in the Doctrine of
Chances was posthumously published. The author was Thomas Bayes, a Presbyterian
minister in England, and the essay contained a theorem which is named for him. Actually,
he never wrote down the theorem explicitly, only the ideas. The actual theorem was first
formulated by Laplace some forty years later and is therefore sometimes called the
Bayes–Laplace theorem. It lies at the heart, mathematically, of Bayesian statistics.
The theorem is obtained by using the symmetry in A and C in the left-hand side of
the formula P(AC) = P (A|C)P(C), to derive the expression
P(C|A) =
P(AC)
P(A)
=
P(A|C)P (C)
P(A)
.
This is combined with the equally simple observation that if A has occurred, it must
have done so together with one of the events C and C
c
, so that P(A) = P(AC) +
P(AC
c
) = P(A|C)P (C) + P(A|C
c
)P(C
c
). Combining these observations gives us
Bayes’ theorem,
P(C|A) =
P(A|C)P (C)
P(A|C)P (C) + P(A|C
c
)(1 − P(C))
,
which relates the conditional probability P(C|A) to that of the inverse conditional
probabilities P(A|C) and P(A|C
c
). But to carry out the computations we need to
know P(C).
In Bayesian statistics the theorem is applied in situations where we want to make
statements about a parameter θ from an observation x. The A above then refers to
probability statements about the observation and C to probability statements about θ.
We then get an expression of the form
dP(θ|x) =
dF (x|θ)dQ(θ)
dF (x|θ)dQ(θ)
,
which will be further explained in Section 4.6.2.
which corresponds to the distribution for the non-alcoholics in Figure 4.1. The criminals,
those who commit the crimes, also differ in their appearance of guilt, which corresponds
to the distribution for the alcoholics in Figure 4.1. The standard of judgement in the court
corresponds to the cut-off point to be used when handing down the verdict of guilty or
not guilty.
The main problem in the law situation is that it is not possible to identify any of the
distribution functions involved, so we cannot produce Figure 4.1 and the whole problem
becomes one of an overall judgement. It is, however, instructive to see the connection with the
diagnostic tests above, since the implications of the standard of judgement in the courtroom are
readily understood. In fact, in many judicial systems there are three different requirements on
the evidence for guilt, constituting different levels of the legal burden of proof : (1) ‘probable
cause’ is a relatively low standard of the evidence which determines if an arrest can be made
or a case tried at court; (2) ‘clear and convincing evidence’ is a level employed in civil courts

RISKS IN STATISTICAL TESTING 93
and for criminal cases with less serious punishments; while (3) evidence ‘beyond reasonable
doubt’ is required for more serious punishments, including capital ones in some countries.
Definitions differ, but the message is that more drastic actions require more confidence that
the action to be taken is the right one.
A particular piece of evidence, denoted A, is presented in court, corresponding to a partic-
ular level of appearance of guilt. Let G be the event that a particular individual is guilty. The
argument in court may then be that the probability of A for an innocent person, the probability
P(A|G
c
), is so low that the person must be guilty. This is an indirect argument, similar to
how we use p-values in statistics. There is a difficulty in finding the correct probability model
for a court case, but that has not always stopped prosecutors and lawyers from using them,
sometimes with serious effects, as the infamous case described in Box 4.3 shows.
However, the main point of confusion here is perhaps that the indirect evidence probability
P(A|G
c
) is sometimes taken to be the probability that the person in question is guilty given
the evidence. In other words, it is mistaken for the probability P(G|A). In this context this
confusion is called the prosecutor’s fallacy. From Bayes’ theorem we know that in order to
be able to assess this probability we need to know the probability of guilt P(G) in the absence
of this particular piece of evidence; the a priori probability of guilt. (We also need to know
P(A|G), but that should be close to one if A is to be taken as evidence of guilt.) For more on
this, see Section 4.8.
4.5 Risks in statistical testing
4.5.1 Does tonsillectomy increase the risk of Hodgkin’s lymphoma?
In statistics the situation is similar to the use of reference ranges for medical diagnostics
in that there is a focus on control of the Type I risk. The Type II risk is addressed when
we plan the experiment and guides us in designing it (in the choice of sample size). To
introduce statistical testing, we first use an example which investigates the relationship
of an exposure E to an outcome C, with data that can be summarized in a 2 × 2 table
as follows:
EE
c
Total
Cx
11
x
12
n
1+
C
c
x
21
x
22
n
2+
Total n
+1
n
+2
n
Here the notation in the margins represents the appropriate sum of x
ij
s. We want to describe
any potential association between the exposure and the outcome.
In a cross-sectional study, data are obtained by picking n subjects and classifying them
into the groups CE, C
c
E, CE
c
and C
c
E
c
. In such a case, we have an observation of a
multinomial distribution
(X
11
,X
12
,X
21
,X
22
) ∈ Mult
4
(n, p
11
,p
12
,p
21
,p
22
).
For the definition of this distribution, see Box 4.4. Here p
ij
denotes the probability that a
randomly sampled individual belongs to cell ij (p
11
= P(CE), etc.) which is the fraction of
patients in the whole population that belong to this group. The sum over all the p
ij
is one.

94 THE ANATOMY OF A STATISTICAL TEST
Box 4.3 The sad case of Sally Clark
In 1999 the solicitor Sally Clark stood trial for, and was convicted of, the murder of her
two children. The accusation was that she killed her first son when he was 11 weeks old,
and then killed her second son when he was 8 weeks old. The defence claimed that these
were two cases of sudden infant death syndrome (SIDS). What decided the case for the
court was the testimony of expert witness Sir Roy Meadow, a pediatrician, who claimed
that the probability of two children in the same family dying from SIDS is as small as
1 in 73 million. Since this is so small, the court argued, the hypothesis of SIDS deaths
must be rejected, and from this it follows that it is murder (no other alternatives were
mentioned). Even though a higher court quashed Mrs Clark’s conviction in January
2003, she never recovered from the court case and died of alcoholism in her home in
March 2007, at the age of 42.
The are two flaws in the argument put to the court.
1. The figure of 1 in 73 million was derived as (1/8543)
2
, where Sir Roy drew
on published studies to obtain the frequency of one SIDS death out of 8543
births in families sharing some of the characteristics of the family on trial.
However, if we let A
1
denote the event that one child dies of SIDS and A
2
the event that two children in the same family die of SIDS, then we have that
P(A
2
) = P(A
2
|A
1
)P(A
1
), but the assumption that the conditional probability
P(A
2
|A
1
) of suffering another death in SIDS when you have already had one
is the same as the probability of a single case, P(A
1
), may not be true. This
is an assumption of independence, but there may well be environmental or ge-
netic factors in play, so that in fact the probability of two SIDS deaths is much
larger than the probability of one squared. However, even though this disputes
the estimate, it is not the key error made by the court.
2. The problem is that the probability P(A
2
), whatever it is, is not relevant at
all, because rare events do occur. The relevant probability is the conditional
probability that the mother murdered her children, when we know they have
died. Since we have two alternatives, SIDS or murder, given that two deaths
have occurred, which is the most likely alternative?
Before the event, double SIDS and double murder are both very unlikely events.
But that is irrelevant, since we are faced with the fact that two babies have died. Which
is then the most likely, SIDS or murder? We do not know. But the argument put forward
in court is not valid.
Note that for the cross-sectional study, p
ij
is naturally estimated by x
ij
/n. The same 2 × 2
table can be obtained in other study designs as well:
1. For a cohort study, including the randomized parallel group experiment, we fix the
number of exposed at n
+1
and number of non-exposed at n
+2
.
2. For a case–control study we fix the margins n
1+
and n
2+
instead.

RISKS IN STATISTICAL TESTING 95
Because the method used to sample subjects is different for cohort and case–control studies
than for cross-sectional ones, the distributions involved are different. For both study types
the data are from two independent binomial distributions, but the probabilities in the cells are
estimated in a different way: in the cohort case the probability p
11
is estimated by x
11
/n
+1
,
whereas in the case–control case it is estimated by x
11
/n
1+
. But they have changed meaning
as well: in the cohort case p
11
is the conditional probability P(C|E), whereas in the case–
control case it is the conditional probability P(E|C). Note that in neither of these cases do
the four probabilities p
ij
sum to one.
If the two events E and C are not associated, they are independent. We can test for this
independence using a conditional test, called Fisher’s exact test, which is based on the fact that
if there is independence, X
11
has a hypergeometric distribution (see Box 4.4). To exemplify
this we consider a specific association, between the cancer known as Hodgkin’s lymphoma
and the medical practice of removing tonsils.
Lymph tissues constitute an important part of our immunological defense system
and include the tonsils. Sometimes the tonsils are removed in children with repeated
throat infections. Hodgkin’s disease is a cancer in the lymph glands, and one reason-
able question to ask is whether the removal of this lymphatic barrier increases the risk of
Hodgkin’s disease.
A case–control study was carried out to investigate this. A group of 109 Hodgkin’s
lymphoma patients were matched with a control group of 109 patients on characteristics
such as age, sex, general disease history, and occupation, as well as other variables that
could be prognostic for the disease. Then hospital records for each of these patients were
inspected in order to find out whether a tonsillectomy had been done or not. This was
not possible for 8 patients with Hodgkin’s disease and 2 patients in the control group, so
the investigators arrived at the following table in which E denotes tonsillectomy and C
Hodgkin’s lymphoma:
EE
c
Total
C 67 34 101
C
c
43 64 107
Total 110 98 208
The hypothesis of interest is that E and C are independent events, an assumption we can
express as the null hypothesis P(C|E) = P(C|E
c
). In words: the risk of acquiring Hodgkin’s
disease is the same whether or not the tonsils have been removed.
In Box 4.4 we see that if we assume the null hypothesis and that all margins are given,
the conditional distribution of the observation in the upper left-hand corner is an observation
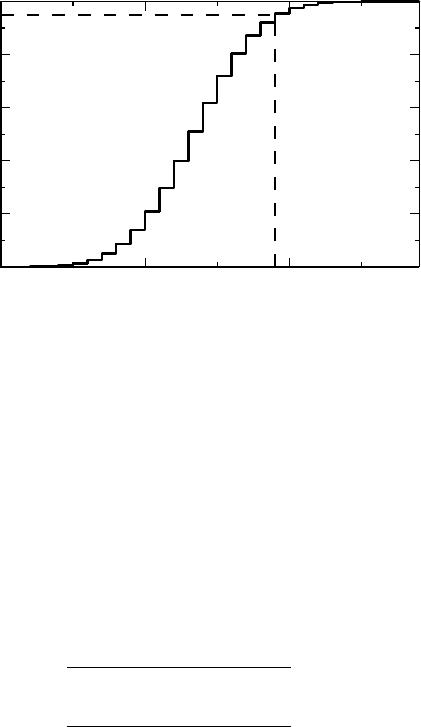
of a hypergeometric distribution, namely Hyp(101, 107, 110). The CDF of this discrete dis-
tribution is illustrated in Figure 4.2. We see that the probability that x
11
≤ 59 is 95% – which
means that if E and C are independent events, the probability of finding a number 60 or more
is as small as 5%. (Actually, since the distribution is discrete we cannot solve exactly for the
probability 95%. The first probability above is actually 95.5%, so the second is 4.5%.) We
found an even higher number, 67, for which the probability is 0.00013. Because such a large
observation is unlikely if E and C are independent, we conclude that there is an association
between Hodgkin’s lymphoma and tonsillectomy. Note that the p-values referred to above
are one-sided.

96 THE ANATOMY OF A STATISTICAL TEST
Box 4.4 The multinomial distribution and its descendants
By definition, X = (X
1
,...,X
k
) ∈ Mult
k
(n, p
1
,...,p
k
), where
j
p
j
= 1, if its
probability function is
p(x
1
,...,x
k
) =
n
x
1
...x
k
p
x
1
1
...p
x
k
k
,
where
j
x
j
= n. The two-dimensional distribution Mult
2
(n, p, 1 − p) is equivalent
to the Bin(n, p) distribution for X
1
. The coefficient
n
x
1
...x
k
denotes the number of ways
we can divide n identical elements into k subsets with x
i
elements in subset i.
The conditional distribution of the quadrinomial X = (X
1
,X
2
,X
3
,X
4
), given the
two conditions X
1
+ X
2
= n
1
and X
3
+ X
4
= n
2
, consists of two independent bino-
mial distributions, X
1
∈ Bin(n
1
,p
1
/(p
1
+ p
2
)) and X
3
∈ Bin(n
2
,p
3
/(p
3
+ p
4
)). If,
in addition, we assume that X
1
+ X
3
= r, the probability function of the conditional
distribution of X
1
is given by
P(X
1
= j)P(X
3
= r − j)
P(X
1
+ X
3
= r)
=
n
1
j
n
2
r−j
θ
j
n
1
k=0
n
1
k
n
2
r−k
θ
k
,
where θ = p
1
p
4
/p
2
p
3
is the odds ratio. We denote this distribution, called Fisher’s
non-central hypergeometric distribution, by Hyp(n
1
,n
2
,r,θ). In the special case where
θ = 1, this is the (central) hypergeometric distribution Hyp(n
1
,n
2
,r) with probability
function
n
1
j
n
2
r − j
/
n
1
+ n
2
r
.
There is a corresponding result for a trinomial: if
(X
1
,X
2
,X
3
) ∈ Mult
3
(n, p
1
,p
2
, 1 − p
1
− p
2
),
then the conditional distribution of X
1
given X
1
+ X
2
= t follows a Bin(t, p
1
/(p
1
+
p
2
)) distribution. In fact, the conditional probability that X
1
= j is
n
j (t − j)(n − t)
p
j
1
p
t−j
2
(1 − p
1
− p
2
)
n−t
n
t
(p
1
+ p
2
)
t
(1 − p
1
− p
2
)
n−t
=
t
j
p
t
1
p
t−j
2
(p
1
+ p
2
)
t
.
When the results of the above-mentioned study became public, another study was per-
formed, with a slightly different design. In this study the investigators started out with 175
Hodgkin’s lymphoma patients, for each of whom they looked for a sibling of the same sex
and with an age difference of at most 5 years. Not every patient had such a sibling, but the
investigators ended up with 85 sibling pairs where one had Hodgkin’s lymphoma and the other
did not. Let H denote the event that the Hodgkin’s lymphoma patient has had a tonsillectomy,
RISKS IN STATISTICAL TESTING 97
0
0.2
0.4
0.6
0.8
1
CDF(k)
605040
Observation k
Figure 4.2 The CDF of the Hyp(101,107,110) distribution.
and let S denote the event that the sibling has. The study outcome can be summarized in the
following four pairs:
(H, S) = 26, (H, S
c
) = 15, (H
c
,S) = 7, (H
c
,S
c
) = 37.
We can reorganize these data into a table analogous to the one analyzed above. For example,
for the cases C (Hodgkin’s lymphoma patients) we find 26 + 15 = 41 with tonsillectomy and
7 + 37 = 44 without. The reorganized table is as follows:
EE
c
Total
C 41 44 85
C
c
33 52 85
Total 74 96 170
If we perform the same analysis as above we get a p-value of 0.14. This is not much support
for the conclusion made from the previous study. In fact, the only conclusion we can draw is
that this study does not provide sufficient evidence to conclude that E and C are associated.
There are at least three reasons for this result:
1. The events E and C are in fact independent.
2. The events are dependent, but the association is so weak that we need more data to
demonstrate it.
3. We have not used our data in an optimal way.
In this case it is mainly the last reason, because we cannot reproduce the paired data from the
reorganized table. Therefore the table we have analyzed has wasted some of the information,
and there must be a better way to analyze these data. The key step is to write down the

98 THE ANATOMY OF A STATISTICAL TEST
appropriate table, which is
SS
c
Total
H 26 15 41
H
c
737 46
Total 33 52 85
and then to pose the appropriate question: is the probability of a tonsillectomy the same for
Hodgkin’s lymphoma patients as it is for their siblings? In probability notation this means
that P(S) = P(H). But P(S) = p
11
+ p
21
and P(H) = p
11
+ p
12
, so this question is really
equivalent to the question whether the off-diagonal probabilities are equal. If they are, the
conditional distribution of x
12
, given that x
12
+ x
21
= 15 + 7 = 22, follows a Bin(22, 0.5)
distribution (see Box 4.4), from which we can compute that the probability of observing 7
or fewer among the 22 is 0.067. This is still not statistically significant at the conventional
significance level 0.05, but we see that the effect of ignoring information really did weaken
our test, and, contrary to the first analysis, we find some support for the result of the first study
also in this study. The test we used here is called McNemar’s test.
For future reference let us note the following. The odds ratio computed from the data of
the first study is (67 · 64)/(43 · 34) = 2.93, and the odds ratio from the corresponding analysis
of the second study is 1.47. In the second analysis of the second study, we constructed a table
for which the probability entries are as follows:
Controls (C
c
)
EE
c
Cases EP(E|C)P(E|C
c
) P(E|C)P(E
c
|C
c
)
(C) E
c
P(E
c
|C)P (E|C
c
) P(E
c
|C)P (E
c
|C
c
)
We therefore see that the ratio of the two elements off the diagonal is actually the odds
ratio, so this is estimated by 15/7 = 2.14 in this analysis. We will see later why it is that the
first estimate must be smaller than the second, and why the second is the estimate we are
looking for.
4.5.2 General discussion about statistical tests
In this section we will do the opposite to what we did in the previous section: we will
give a high-level discussion on statistical tests. This is essentially a discussion about
tails in particular CDFs. More precisely, a statistical test is based on a test statistic, for
which there are two relevant CDFs. The first is the distribution F (x) of the test statistic
under the null hypothesis. The second is the true distribution G(x) of the test statistic. In
statistics we know F (x), which can often be well approximated by one of the Gaussian
distributions defined in Box 4.5 and further discussed later in this chapter. Knowledge
about F (x) is necessary for us to be able to compute p-values etc., as was illustrated in the
previous section.
The true distribution G(x), on the other hand, is always unknown, though it is the ultimate
purpose of the experiment to learn something about it. Knowledge about G(x) would have
been useful in the design of the experiment, because it would have made it possible for us to

RISKS IN STATISTICAL TESTING 99
Box 4.5 The univariate Gaussian distribution
The most important distributions in statistics are the Gaussian distributions. The stan-
dard Gaussian, or normal, distribution is denoted by N(0, 1) and has the cumulative
distribution function
(x) =
x
−∞
1
√
2π
e
−y
2
/2
dy.
If a stochastic variable X can be written X = m + σZ, where Z has a N(0, 1) distribu-
tion, we have X ∈ N(m, σ
2
), with CDF given by
F (x) =
x − m
σ
.
We can compute the parameters m and σ from the CDF as
m =
∞
−∞
xdF(x),σ
2
=
∞
−∞
(x − m)
2
dF (x).
Here we use the concept of a Stieltjes integral (see Box 4.8). These parameters are
defined for a general distribution (provided the integrals converge) and are called the
mean and the variance of F (x).
One important reason why Gaussian distributions are so important is that they often
are reasonable approximations of distributions that are symmetric around some value
m, if we adjust σ appropriately. They also appear as approximations to the distribution
of many test statistics, because of a famous theorem called the central limit theorem
(CLT), about which we will have more to say in Section 4.7.
accurately compute the risk β of a Type II error of a particular experiment. The number 1 − β,
which we called the specificity for the diagnostic test, is called the power of the statistical
test. But since we do not know G(x) we need to approach that problem in a slightly different
way, which will be described in more detail in the next chapter. (If we actually knew G(x)
there would not be much statistics to be done.)
As already mentioned, a statistical test can be one-sided or two-sided. For a one-sided test
we compute the p-value from only one tail of F(x), whereas for a two-sided test we use both
tails. Essentially the difference is the same as the difference between the two questions ‘is A
better than B?’ (one-sided) and ‘is there a difference between A and B?’ (two-sided). If X is a
test statistic (which is a stochastic variable), let x be its observed value, computed from the data
we have collected in the experiment. For a one-sided test, for which large values of x are indica-
tive of a false null hypothesis, the p-value is computed from p = 1 − F (x−) = P(X ≥ x).
The notation F (x−) denotes the left-hand limit of F (x) and is only needed if F (x) is not con-
tinuous at the point x (by definition F (x) is continuous from the right). If instead small values
of x are indicative of a false null hypothesis we compute the p-value from p = F(x). For
the two-sided test we usually have a distribution that is symmetric around x = 0. A Gaussian
distribution with mean zero is one important example. The two-sided p-value is in such a case
computed as the probability that {X ≤−x} plus the probability that {X
≥ x}, in other words
as p = F (−x) + 1 − F (x−) = 2(1 − F (x−)) (see Box 4.6). This can often be simplified by