Manning Ch. D., Raghavan P., Sch?tze H. Introduction to Information Retrieval - Введение в информационный поиск
Подождите немного. Документ загружается.

Online edition (c)2009 Cambridge UP
76 4 Index construction
master
assign
map
phase
reduce
phase
assign
parser
splits
parser
parser
inve rter
postings
inve rter
inve rter
a-f
g-p
q-z
a-f g-p q-z
a-f g-p q-z
a-f
segment
files
g-p q-z
◮
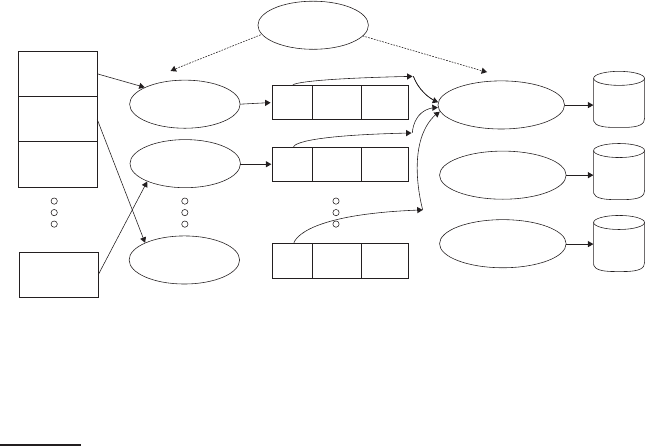
Figure 4.5 An example of distributed indexing with MapReduce. Adapted from
Dean and Ghemawat (2004).
partitioning the keys into j term partitions and having the parsers write key-
value pairs for each term partition into a separate segment file. In Figure
4.5,
the term partitions are according to first letter: a–f, g–p, q–z, and j = 3. (We
chose these key ranges for ease of exposition. In general, key ranges need not
correspond to contiguous terms or termIDs.) The term partitions are defined
by the person who operates the indexing system (Exercise
4.10). The parsers
then write corresponding segment files, one for each term partition. Each
term partition thus corresponds to r segments files, where r is the number
of parsers. For instance, Figure
4.5 shows three a–f segment files of the a–f
partition, corresponding to the three parsers shown in the figure.
Collecting all values (here: docIDs) for a given key (here: termID) into one
list is the task of the inverters in the reduce phase. The master assigns eachINVERTER
term partition to a different inverter – and, as in the case of parsers, reas-
signs term partitions in case of failing or slow inverters. Each term partition
(corresponding to r segment files, one on each parser) is processed by one in-
verter. We assume here that segment files are of a size that a single machine
can handle (Exercise
4.9). Finally, the list of values is sorted for each key and
written to the final sorted postings list (“postings” in the figure). (Note that
postings in Figure
4.6 include term frequencies, whereas each posting in the
other sections of this chapter is simply a docID without term frequency in-
formation.) The data flow is shown for a–f in Figure
4.5. This completes the
construction of the inverted index.

Online edition (c)2009 Cambridge UP
4.4 Distributed indexing 77
Schema of map and reduce functions
map: input list(k, v)
reduce: (k,list(v)) output
Instantiation of the schema for index construction
map: web collection list(termID, docID)
reduce: ( termID ,
1
list(docID) , termID ,
2
list(docID) , ...) (postings
list list
1
,postings
2
, ...)
Example for index construction
map: d
2
: Cdied. d
1
: C came,Cc’ed. ( C, d
2
, died,d
2
, C,d
1
, came,d
1
, C,d
1
, 〈c’ed,d
1
〉)
reduce: ( C,(d
2
,d
1
,d
1
) , died,(d
2
) , came,(d
1
) , c’ed,(d
1
) ) (〈C,(d
1
:2,d
2
:1)〉, 〈died,(d
2
:1)〉, 〈came,(d
1
:1)〉, 〈c’ed,(d
1
:1)〉 )
〉 〉
〉 〉 〉 〉
〉〉〉〉 〉
〈
〈 〈
〈 〈 〈
〈〈〈〈 〈
→
→
→
→
→
→
◮
Figure 4.6 Map and reduce functions in MapReduce. In general, the map func-
tion produces a list of key-value pairs. All values for a key are collected into one
list in the reduce phase. This list is then processed further. The instantiations of the
two functions and an example are shown for index construction. Because the map
phase processes documents in a distributed fashion, termID–docID pairs need not be
ordered correctly initially as in this example. The example shows terms instead of
termIDs for better readability. We abbreviate Caesar as C and conquered as c’ed.
Parsers and inverters are not separate sets of machines. The master iden-
tifies idle machines and assigns tasks to them. The same machine can be a
parser in the map phase and an inverter in the reduce phase. And there are
often other jobs that run in parallel with index construction, so in between
being a parser and an inverter a machine might do some crawling or another
unrelated task.
To minimize write times before inverters reduce the data, each parser writes
its segment files to its local disk. In the reduce phase, the master communi-
cates to an inverter the locations of the relevant segment files (e.g., of the r
segment files of the a–f partition). Each segment file only requires one se-
quential read because all data relevant to a particular inverter were written
to a single segment file by the parser. This setup minimizes the amount of
network traffic needed during indexing.
Figure 4.6 shows the general schema of the MapReduce functions. In-
put and output are often lists of key-value pairs themselves, so that several
MapReduce jobs can run in sequence. In fact, this was the design of the
Google indexing system in 2004. What we describe in this section corre-
sponds to only one of five to ten MapReduce operations in that indexing
system. Another MapReduce operation transforms the term-partitioned in-
dex we just created into a document-partitioned one.
MapReduce offers a robust and conceptually simple framework for imple-
menting index construction in a distributed environment. By providing a
semiautomatic method for splitting index construction into smaller tasks, it
can scale to almost arbitrarily large collections, given computer clusters of
Online edition (c)2009 Cambridge UP
78 4 Index construction
sufficient size.
?
Exercise 4.3
For n = 15 splits, r = 10 segments, and j = 3 term partitions, how long would
distributed index creation take for Reuters-RCV1 in a MapReduce architecture? Base
your assumptions about cluster machines on Table
4.1.
4.5 Dynamic indexing
Thus far, we have assumed that the document collection is static. This is fine
for collections that change infrequently or never (e.g., the Bible or Shake-
speare). But most collections are modified frequently with documents being
added, deleted, and updated. This means that new terms need to be added
to the dictionary, and postings lists need to be updated for existing terms.
The simplest way to achieve this is to periodically reconstruct the index
from scratch. This is a good solution if the number of changes over time is
small and a delay in making new documents searchable is acceptable – and
if enough resources are available to construct a new index while the old one
is still available for querying.
If there is a requirement that new documents be included quickly, one solu-
tion is to maintain two indexes: a large main index and a small auxiliary indexAUXILIARY INDEX
that stores new documents. The auxiliary index is kept in memory. Searches
are run across both indexes and results merged. Deletions are stored in an in-
validation bit vector. We can then filter out deleted documents before return-
ing the search result. Documents are updated by deleting and reinserting
them.
Each time the auxiliary index becomes too large, we merge it into the main
index. The cost of this merging operation depends on how we store the index
in the file system. If we store each postings list as a separate file, then the
merge simply consists of extending each postings list of the main index by
the corresponding postings list of the auxiliary index. In this scheme, the
reason for keeping the auxiliary index is to reduce the number of disk seeks
required over time. Updating each document separately requires up to M
ave
disk seeks, where M
ave
is the average size of the vocabulary of documents in
the collection. With an auxiliary index, we only put additional load on the
disk when we merge auxiliary and main indexes.
Unfortunately, the one-file-per-postings-list scheme is infeasible because
most file systems cannot efficiently handle very large numbers of files. The
simplest alternative is to store the index as one large file, that is, as a concate-
nation of all postings lists. In reality, we often choose a compromise between
the two extremes (Section
4.7). To simplify the discussion, we choose the
simple option of storing the index as one large file here.

Online edition (c)2009 Cambridge UP
4.5 Dynamic indexing 79
LMERGEADDTOKEN(indexes, Z
0
, token)
1 Z
0
← MERGE(Z
0
, {token})
2 if |Z
0
| = n
3 t hen for i ← 0 to ∞
4 do if I
i
∈ indexes
5 then Z
i+1
← MERGE(I
i
, Z
i
)
6 (Z
i+1
is a temporary index on disk.)
7 indexes ← indexes − {I
i
}
8 else I
i
← Z
i
(Z
i
becomes the permanent index I
i
.)
9 indexes ← indexes ∪ {I
i
}
10 BREAK
11 Z
0
← ∅
LOGARITHMICMERGE()
1 Z
0
← ∅ (Z
0
is the in-memory index.)
2 indexe s ← ∅
3 while true
4 do LMERGEADDTOKEN(indexes, Z
0
, GETNEXTTOKEN())
◮
Figure 4.7 Logarithmic merging. Each token (termID,docID) is initially added to
in-memory index Z
0
by LMERGEADDTOKEN. LOGARITHMICMERGE initializes Z
0
and indexes.
In this scheme, we process each posting ⌊T/n⌋ times because we touch it
during each of ⌊T/n⌋ merges where n is the size of the auxiliary index and T
the total number of postings. Thus, the overall time complexity is Θ(T
2
/n).
(We neglect the representation of terms here and consider only the docIDs.
For the purpose of time complexity, a postings list is simply a list of docIDs.)
We can do better than Θ(T
2
/n) by introducing log
2
(T/n) indexes I
0
, I
1
,
I
2
, . .. of size 2
0
×n, 2
1
× n, 2
2
×n . . . . Postings percolate up this sequence of
indexes and are processed only once on each level. This scheme is called log-LOGARITHMIC
MERGING
arithmic merging (Figure
4.7). As before, up to n postings are accumulated in
an in-memory auxiliary index, which we call Z
0
. When the limit n is reached,
the 2
0
× n postings in Z
0
are transferred to a new index I
0
that is created on
disk. The next time Z
0
is full, it is merged with I
0
to create an index Z
1
of size
2
1
× n. Then Z
1
is either stored as I
1
(if there isn’t already an I
1
) or merged
with I
1
into Z
2
(if I
1
exists); and so on. We service search requests by query-
ing in-memory Z
0
and all currently valid indexes I
i
on disk and merging the
results. Readers familiar with the binomial heap data structure
2
will recog-
2. See, for example, (Cormen et al. 1990, Chapter 19).

Online edition (c)2009 Cambridge UP
80 4 Index construction
nize its similarity with the structure of the inverted indexes in logarithmic
merging.
Overall index construction time is Θ(T log(T/n)) because each posting
is processed only once on each of the log(T/n) levels. We trade this effi-
ciency gain for a slow down of query processing; we now need to merge
results from log(T/n) indexes as opposed to just two (the main and auxil-
iary indexes). As in the auxiliary index scheme, we still need to merge very
large indexes occasionally (which slows down the search system during the
merge), but this happens less frequently and the indexes involved in a merge
on average are smaller.
Having multiple indexes complicates the maintenance of collection-wide
statistics. For example, it affects the spelling correction algorithm in Sec-
tion
3.3 (page 56) that selects the corrected alternative with the most hits.
With multiple indexes and an invalidation bit vector, the correct number of
hits for a term is no longer a simple lookup. In fact, all aspects of an IR
system – index maintenance, query processing, distribution, and so on – are
more complex in logarithmic merging.
Because of this complexity of dynamic indexing, some large search engines
adopt a reconstruction-from-scratch strategy. They do not construct indexes
dynamically. Instead, a new index is built from scratch periodically. Query
processing is then switched from the new index and the old index is deleted.
?
Exercise 4.4
For n = 2 and 1 ≤ T ≤ 30, perform a step-by-step simulation of the algorithm in
Figure
4.7. Create a table that shows, for each point in time at which T = 2 ∗ k tokens
have been processed (1 ≤ k ≤ 15), which of the three indexes I
0
, . . . , I
3
are in use. The
first three lines of the table are given below.
I
3
I
2
I
1
I
0
2 0 0 0 0
4
0 0 0 1
6
0 0 1 0
4.6 Other types of indexes
This chapter only describes construction of nonpositional indexes. Except
for the much larger data volume we need to accommodate, the main differ-
ence for positional indexes is that (termID, docID, (position1, position2, . . . ))
triples, instead of (termID, docID) pairs have to be processed and that tokens
and postings contain positional information in addition to docIDs. With this
change, the algorithms discussed here can all be applied to positional in-
dexes.
In the indexes we have considered so far, postings lists are ordered with
respect to docID. As we see in Chapter 5, this is advantageous for compres-
Online edition (c)2009 Cambridge UP
4.6 Other types of indexes 81
users
documents
0/1
doc e., 1 otherwis
0 if user can’t read
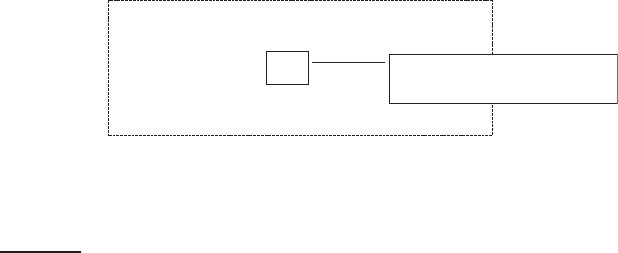
◮
Figure 4.8 A user-document matrix for access control lists. Element (i, j) is 1 if
user i has access to document j and 0 otherwise. During query processing, a user’s
access postings list is intersected with the results list returned by the text part of the
index.
sion – instead of docIDs we can compress smaller gaps between IDs, thus
reducing space requirements for the index. However, this structure for the
index is not optimal when we build ranked (Chapters 6 and 7) – as opposed toRANKED
Boolean – retrieval systems. In ranked retrieval, postings are often ordered ac-RETRIEVAL SYSTEMS
cording to weight or impact, with the highest-weighted postings occurring
first. With this organization, scanning of long postings lists during query
processing can usually be terminated early when weights have become so
small that any further documents can be predicted to be of low similarity
to the query (see Chapter
6). In a docID-sorted index, new documents are
always inserted at the end of postings lists. In an impact-sorted index (Sec-
tion 7.1.5, page 140), the insertion can occur anywhere, thus complicating the
update of the inverted index.
Securityis an important consideration for retrieval systems in corporations.SECURITY
A low-level employee should not be able to find the salary roster of the cor-
poration, but authorized managers need to be able to search for it. Users’
results lists must not contain documents they are barred from opening; the
very existence of a document can be sensitive information.
User authorization is often mediated through access control lists or ACLs.ACCESS CONTROL LISTS
ACLs can be dealt with in an information retrieval system by representing
each document as the set of users that can access them (Figure 4.8) and then
inverting the resulting user-document matrix. The inverted ACL index has,
for each user, a “postings list” of documents they can access – the user’s ac-
cess list. Search results are then intersected with this list. However, such
an index is difficult to maintain when access permissions change – we dis-
cussed these difficulties in the context of incremental indexing for regular
postings lists in Section 4.5. It also requires the processing of very long post-
ings lists for users with access to large document subsets. User membership
is therefore often verified by retrieving access information directly from the
file system at query time – even though this slows down retrieval.

Online edition (c)2009 Cambridge UP
82 4 Index construction
◮
Table 4.3 The five steps in constructing an index for Reuters-RCV1 in blocked
sort-based indexing. Line numbers refer to Figure 4.2.
Step Time
1 reading of collection (line 4)
2 10 initial sorts of 10
7
records each (line 5)
3 writing of 10 blocks (line 6)
4 total disk transfer time for merging (line 7)
5 time of actual merging (line 7)
total
◮
Table 4.4 Collection statistics for a large collection.
Symbol Statistic Value
N # documents 1,000,000,000
L
ave
# tokens per document 1000
M # distinct terms 44,000,000
We discussed indexes for storing and retrieving terms (as opposed to doc-
uments) in Chapter 3.
?
Exercise 4.5
Can spelling correction compromise document-level security? Consider the case where
a spelling correction is based on documents to which the user does not have access.
?
Exercise 4.6
Total index construction time in blocked sort-based indexing is broken down in Ta-
ble
4.3. Fill out the time column of the table for Reuters-RCV1 assuming a system
with the parameters given in Table
4.1.
Exercise 4.7
Repeat Exercise 4.6 for the larger collection in Table 4.4. Choose a block size that is
realistic for current technology (remember that a block should easily fit into main
memory). How many blocks do you need?
Exercise 4.8
Assume that we have a collection of modest size whose index can be constructed with
the simple in-memory indexing algorithm in Figure
1.4 (page 8). For this collection,
compare memory, disk and time requirements of the simple algorithm in Figure
1.4
and blocked sort-based indexing.
Exercise 4.9
Assume that machines in MapReduce have 100 GB of disk space each. Assume fur-
ther that the postings list of the term the has a size of 200 GB. Then the MapReduce
algorithm as described cannot be run to construct the index. How would you modify
MapReduce so that it can handle this case?
Online edition (c)2009 Cambridge UP
4.7 References and further reading 83
Exercise 4.10
For optimal load balancing, the inverters in MapReduce must get segmented postings
files of similar sizes. For a new collection, the distribution of key-value pairs may not
be known in advance. How would you solve this problem?
Exercise 4.11
Apply MapReduce to the problem of counting how often each term occurs in a set of
files. Specify map and reduce operations for this task. Write down an example along
the lines of Figure
4.6.
Exercise 4.12
We claimed (on page 80) that an auxiliary index can impair the quality of collec-
tion statistics. An example is the term weighting method idf, which is defined as
log(N/df
i
) where N is the total number of documents and df
i
is the number of docu-
ments that term i occurs in (Section
6.2.1, page 117). Show that even a small auxiliary
index can cause significant error in idf when it is computed on the main index only.
Consider a rare term that suddenly occurs frequently (e.g., Flossie as in Tropical Storm
Flossie).
4.7 Refe rences and further reading
Witten et al. (1999, Chapter 5) present an extensive treatment of the subject of
index construction and additional indexing algorithms with different trade-
offs of memory, disk space, and time. In general, blocked sort-based indexing
does well on all three counts. However, if conserving memory or disk space
is the main criterion, then other algorithms may be a better choice. See Wit-
ten et al. (1999), Tables 5.4 and 5.5; BSBI is closest to “sort-based multiway
merge,” but the two algorithms differ in dictionary structure and use of com-
pression.
Moffat and Bell (1995) show how to construct an index “in situ,” that
is, with disk space usage close to what is needed for the final index and
with a minimum of additional temporary files (cf. also Harman and Candela
(1990)). They give Lesk (1988) and Somogyi (1990) credit for being among
the first to employ sorting for index construction.
The SPIMI method in Section
4.3 is from (Heinz and Zobel 2003). We have
simplified several aspects of the algorithm, including compression and the
fact that each term’s data structure also contains, in addition to the postings
list, its document frequency and house keeping information. We recommend
Heinz and Zobel (2003) and Zobel and Moffat (2006) as up-do-date, in-depth
treatments of index construction. Other algorithms with good scaling prop-
erties with respect to vocabulary size require several passes through the data,
e.g., FAST-INV (Fox and Lee 1991, Harman et al. 1992).
The MapReduce architecture was introduced by Dean and Ghemawat (2004).
An open source implementation of MapReduce is available at http://lucene.apache.org/hadoop/.
Ribeiro-Neto et al. (1999) and Melnik et al. (2001) describe other approaches
Online edition (c)2009 Cambridge UP
84 4 Index construction
to distributed indexing. Introductory chapters on distributed IR are (Baeza-
Yates and Ribeiro-Neto 1999, Chapter 9) and (Grossman and Frieder 2004,
Chapter 8). See also Callan (2000).
Lester et al. (2005) and Büttcher and Clarke (2005a) analyze the proper-
ties of logarithmic merging and compare it with other construction methods.
One of the first uses of this method was in Lucene (http://lucene.apache.org).
Other dynamic indexing methods are discussed by Büttcher et al. (2006) and
Lester et al. (2006). The latter paper also discusses the strategy of replacing
the old index by one built from scratch.
Heinz et al. (2002) compare data structures for accumulating the vocabu-
lary in memory. Büttcher and Clarke (2005b) discuss security models for a
common inverted index for multiple users. A detailed characterization of the
Reuters-RCV1 collection can be found in (Lewis et al. 2004). NIST distributes
the collection (see http://trec.nist.gov/data/reuters/reuters.html).
Garcia-Molina et al. (1999, Chapter 2) review computer hardware relevant
to system design in depth.
An effective indexer for enterprise search needs to be able to communicate
efficiently with a number of applications that hold text data in corporations,
including Microsoft Outlook, IBM’s Lotus software, databases like Oracle
and MySQL, content management systems like Open Text, and enterprise
resource planning software like SAP.
Online edition (c)2009 Cambridge UP
DRAFT! © April 1, 2009 Cambridge University Press. Feedback welcome. 85
5 Index compression
Chapter
1 introduced the dictionary and the inverted index as the central
data structures in information retrieval (IR). In this chapter, we employ a
number of compression techniques for dictionary and inverted index that
are essential for efficient IR systems.
One benefit of compression is immediately clear. We need less disk space.
As we will see, compression ratios of 1:4 are easy to achieve, potentially cut-
ting the cost of storing the index by 75%.
There are two more subtle benefits of compression. The first is increased
use of caching. Search systems use some parts of the dictionary and the index
much more than others. For example, if we cache the postings list of a fre-
quently used query term t, then the computations necessary for responding
to the one-term query t can be entirely done in memory. With compression,
we can fit a lot more information into main memory. Instead of having to
expend a disk seek when processing a query with t, we instead access its
postings list in memory and decompress it. As we will see below, there are
simple and efficient decompression methods, so that the penalty of having to
decompress the postings list is small. As a result, we are able to decrease the
response time of the IR system substantially. Because memory is a more ex-
pensive resource than disk space, increased speed owing to caching – rather
than decreased space requirements – is often the prime motivator for com-
pression.
The second more subtle advantage of compression is faster transfer of data
from disk to memory. Efficient decompression algorithms run so fast on
modern hardware that the total time of transferring a compressed chunk of
data from disk and then decompressing it is usually less than transferring
the same chunk of data in uncompressed form. For instance, we can reduce
input/output (I/O) time by loading a much smaller compressed postings
list, even when you add on the cost of decompression. So, in most cases,
the retrieval system runs faster on compressed postings lists than on uncom-
pressed postings lists.
If the main goal of compression is to conserve disk space, then the speed