Manning Ch. D., Raghavan P., Sch?tze H. Introduction to Information Retrieval - Введение в информационный поиск
Подождите немного. Документ загружается.

Online edition (c)2009 Cambridge UP
146 7 Computing scores in a complete search system
3.
If we still have fewer than ten results, run the vector space query consist-
ing of the three individual query terms.
Each of these steps (if invoked) may yield a list of scored documents, for
each of which we compute a score. This score must combine contributions
from vector space scoring, static quality, proximity weighting and potentially
other factors – particularly since a document may appear in the lists from
multiple steps. This demands an aggregate scoring function that accumulatesEVIDENCE
ACCUMULATION
evidence of a document’s relevance from multiple sources. How do we devise
a query parser and how do we devise the aggregate scoring function?
The answer depends on the setting. In many enterprise settings we have
application builders who make use of a toolkit of available scoring opera-
tors, along with a query parsing layer, with which to manually configure
the scoring function as well as the query parser. Such application builders
make use of the available zones, metadata and knowledge of typical doc-
uments and queries to tune the parsing and scoring. In collections whose
characteristics change infrequently (in an enterprise application, significant
changes in collection and query characteristics typically happen with infre-
quent events such as the introduction of new document formats or document
management systems, or a merger with another company). Web search on
the other hand is faced with a constantly changing document collection with
new characteristics being introduced all the time. It is also a setting in which
the number of scoring factors can run into the hundreds, making hand-tuned
scoring a difficult exercise. To address this, it is becoming increasingly com-
mon to use machine-learned scoring, extending the ideas we introduced in
Section 6.1.2, as will be discussed further in Section 15.4.1.
7.2.4 Putting it all together
We have now studied all the components necessary for a basic search system
that supports free text queries as well as Boolean, zone and field queries. We
briefly review how the various pieces fit together into an overall system; this
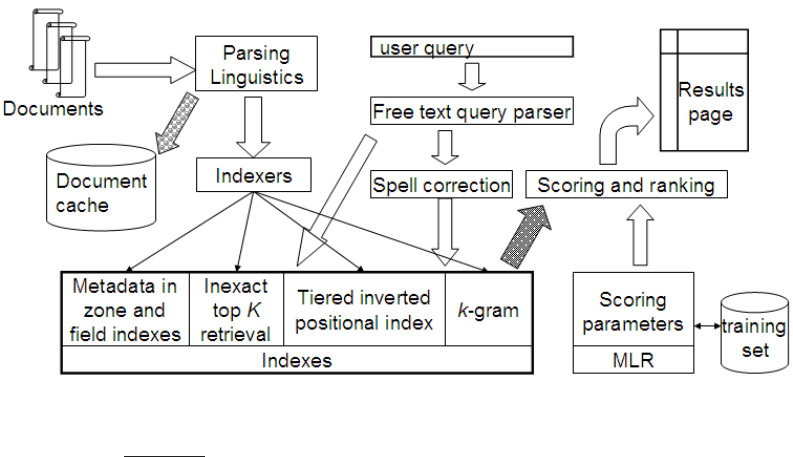
is depicted in Figure 7.5.
In this figure, documents stream in from the left for parsing and linguis-
tic processing (language and format detection, tokenization and stemming).
The resulting stream of tokens feeds into two modules. First, we retain a
copy of each parsed document in a document cache. This will enable us
to generate results snippets: snippets of text accompanying each document
in the results list for a query. This snippet tries to give a succinct explana-
tion to the user of why the document matches the query. The automatic
generation of such snippets is the subject of Section
8.7. A second copy
of the tokens is fed to a bank of indexers that create a bank of indexes in-
cluding zone and field indexes that store the metadata for each document,
Online edition (c)2009 Cambridge UP
7.3 Vector space scoring and query operator interaction 147
◮
Figure 7.5 A complete search system. Data paths are shown primarily for a free
text query.
(tiered) positional indexes, indexes for spelling correction and other tolerant
retrieval, and structures for accelerating inexact top-K retrieval. A free text
user query (top center) is sent down to the indexes both directly and through
a module for generating spelling-correction candidates. As noted in Chap-
ter
3 the latter may optionally be invoked only when the original query fails
to retrieve enough results. Retrieved documents (dark arrow) are passed
to a scoring module that computes scores based on machine-learned rank-
ing (MLR), a technique that builds on Section
6.1.2 (to be further developed
in Section 15.4.1) for scoring and ranking documents. Finally, these ranked
documents are rendered as a results page.
?
Exercise 7.9
Explain how the postings intersection algorithm first introduced in Section 1.3 can be
adapted to find the smallest integer ω that contains all query terms.
Exercise 7.10
Adapt this procedure to work when not all query terms are present in a document.
7.3 Vector space scoring and query operator interaction
We introduced the vector space model as a paradigm for free text queries.
We conclude this chapter by discussing how the vector space scoring model
Online edition (c)2009 Cambridge UP
148 7 Computing scores in a complete search system
relates to the query operators we have studied in earlier chapters. The re-
lationship should be viewed at two levels: in terms of the expressiveness
of queries that a sophisticated user may pose, and in terms of the index that
supports the evaluation of the various retrieval methods. In building a search
engine, we may opt to support multiple query operators for an end user. In
doing so we need to understand what components of the index can be shared
for executing various query operators, as well as how to handle user queries
that mix various query operators.
Vector space scoring supports so-called free text retrieval, in which a query
is specified as a set of words without any query operators connecting them. It
allows documents matching the query to be scored and thus ranked, unlike
the Boolean, wildcard and phrase queries studied earlier. Classically, the
interpretation of such free text queries was that at least one of the query terms
be present in any retrieved document. However more recently, web search
engines such as Google have popularized the notion that a set of terms typed
into their query boxes (thus on the face of it, a free text query) carries the
semantics of a conjunctive query that only retrieves documents containing
all or most query terms.
Boolean retrieval
Clearly a vector space index can be used to answer Boolean queries, as long
as the weight of a term t in the document vector for d is non-zero when-
ever t occurs in d. The reverse is not true, since a Boolean index does not by
default maintain term weight information. There is no easy way of combin-
ing vector space and Boolean queries from a user’s standpoint: vector space
queries are fundamentally a form of evidence accumulation, where the pres-
ence of more query terms in a document adds to the score of a document.
Boolean retrieval on the other hand, requires a user to specify a formula
for selecting documents through the presence (or absence) of specific com-
binations of keywords, without inducing any relative ordering among them.
Mathematically, it is in fact possible to invoke so-called p-norms to combine
Boolean and vector space queries, but we know of no system that makes use
of this fact.
Wildcard queries
Wildcard and vector space queries require different indexes, except at the
basic level that both can be implemented using postings and a dictionary
(e.g., a dictionary of trigrams for wildcard queries). If a search engine allows
a user to specify a wildcard operator as part of a free text query (for instance,
the query rom* restaurant), we may interpret the wildcard component of the
query as spawning multiple terms in the vector space (in this example, rome
Online edition (c)2009 Cambridge UP
7.4 References and further reading 149
and roman would be two such terms) all of which are added to the query
vector. The vector space query is then executed as usual, with matching
documents being scored and ranked; thus a document containing both rome
and roma is likely to be scored higher than another containing only one of
them. The exact score ordering will of course depend on the relative weights
of each term in matching documents.
Phrase queries
The representation of documents as vectors is fundamentally lossy: the rel-
ative order of terms in a document is lost in the encoding of a document as
a vector. Even if we were to try and somehow treat every biword as a term
(and thus an axis in the vector space), the weights on different axes not in-
dependent: for instance the phrase German shepherd gets encoded in the axis
german shepherd, but immediately has a non-zero weight on the axes german
and shepherd. Further, notions such as idf would have to be extended to such
biwords. Thus an index built for vector space retrieval cannot, in general, be
used for phrase queries. Moreover, there is no way of demanding a vector
space score for a phrase query — we only know the relative weights of each
term in a document.
On the query german shepherd, we could use vector space retrieval to iden-
tify documents heavy in these two terms, with no way of prescribing that
they occur consecutively. Phrase retrieval, on the other hand, tells us of the
existence of the phrase german shepherd in a document, without any indi-
cation of the relative frequency or weight of this phrase. While these two
retrieval paradigms (phrase and vector space) consequently have different
implementations in terms of indexes and retrieval algorithms, they can in
some cases be combined usefully, as in the three-step example of query pars-
ing in Section
7.2.3.
7.4 Refe rences and further reading
Heuristics for fast query processing with early termination are described by
Anh et al. (2001), Garcia et al. (2004), Anh and Moffat (2006b), Persin et al.
(1996). Cluster pruning is investigated by Singitham et al. (2004) and by
Chierichetti et al. (2007); see also Section
16.6 (page 372). Champion lists are
described in Persin (1994) and (under the name top docs) in Brown (1995),TOP DOCS
and further developed in Brin and Page (1998), Long and Suel (2003). While
these heuristics are well-suited to free text queries that can be viewed as vec-
tors, they complicate phrase queries; see Anh and Moffat (2006c) for an index
structure that supports both weighted and Boolean/phrase searches. Carmel
et al. (2001) Clarke et al. (2000) and Song et al. (2005) treat the use of query
Online edition (c)2009 Cambridge UP
150 7 Computing scores in a complete search system
term proximity in assessing relevance. Pioneering work on learning of rank-
ing functions was done by Fuhr (1989), Fuhr and Pfeifer (1994), Cooper et al.
(1994), Bartell (1994), Bartell et al. (1998) and by Cohen et al. (1998).
Online edition (c)2009 Cambridge UP
DRAFT! © April 1, 2009 Cambridge University Press. Feedback welcome. 151
8
Evaluatio n in info r mation
re t rieval
We have seen in the preceding chapters many alternatives in designing an IR
system. How do we know which of these techniques are effective in which
applications? Should we use stop lists? Should we stem? Should we use in-
verse document frequency weighting? Information retrieval has developed
as a highly empirical discipline, requiring careful and thorough evaluation to
demonstrate the superior performance of novel techniques on representative
document collections.
In this chapter we begin with a discussion of measuring the effectiveness
of IR systems (Section 8.1) and the test collections that are most often used
for this purpose (Section
8.2). We then present the straightforward notion of
relevant and nonrelevant documents and the formal evaluation methodol-
ogy that has been developed for evaluating unranked retrieval results (Sec-
tion
8.3). This includes explaining the kinds of evaluation measures that
are standardly used for document retrieval and related tasks like text clas-
sification and why they are appropriate. We then extend these notions and
develop further measures for evaluating ranked retrieval results (Section
8.4)
and discuss developing reliable and informative test collections (Section 8.5).
We then step back to introduce the notion of user utility, and how it is ap-
proximated by the use of document relevance (Section
8.6). The key utility
measure is user happiness. Speed of response and the size of the index are
factors in user happiness. It seems reasonable to assume that relevance of
results is the most important factor: blindingly fast, useless answers do not
make a user happy. However, user perceptions do not always coincide with
system designers’ notions of quality. For example, user happiness commonly
depends very strongly on user interface design issues, including the layout,
clarity, and responsiveness of the user interface, which are independent of
the quality of the results returned. We touch on other measures of the qual-
ity of a system, in particular the generation of high-quality result summary
snippets, which strongly influence user utility, but are not measured in the
basic relevance ranking paradigm (Section 8.7).
Online edition (c)2009 Cambridge UP
152 8 Evaluation in information retrieval
8.1 Information retrieval system evaluation
To measure ad hoc information retrieval effectiveness in the standard way,
we need a test collection consisting of three things:
1. A document collection
2. A test suite of information needs, expressible as queries
3. A set of relevance judgments, standardly a binary assessment of either
relevant or nonrelevant for each query-document pair.
The standard approach to information retrieval system evaluation revolves
around the notion of relevant and nonrelevant documents. With respect to aRELEVANCE
user information need, a document in the test collection is given a binary
classification as either relevant or nonrelevant. This decision is referred to as
the gold standard or ground truth judgment of relevance. The test documentGOLD STANDARD
GROUND TRUTH
collection and suite of information needs have to be of a reasonable size:
you need to average performance over fairly large test sets, as results are
highly variable over different documents and information needs. As a rule
of thumb, 50 information needs has usually been found to be a sufficient
minimum.
Relevance is assessed relative to an information need, not a query. ForINFORMATION NEED
example, an information need might be:
Information on whether drinking red wine is more effective at reduc-
ing your risk of heart attacks than white wine.
This might be translated into a query such as:
wine AND red AND white AND heart AND attack AND effective
A document is relevant if it addresses the stated information need, not be-
cause it just happens to contain all the words in the query. This distinction is
often misunderstood in practice, because the information need is not overt.
But, nevertheless, an information need is present. If a user types python into a
web search engine, they might be wanting to know where they can purchase
a pet python. Or they might be wanting information on the programming
language Python. From a one word query, it is very difficult for a system to
know what the information need is. But, nevertheless, the user has one, and
can judge the returned results on the basis of their relevance to it. To evalu-
ate a system, we require an overt expression of an information need, which
can be used for judging returned documents as relevant or nonrelevant. At
this point, we make a simplification: relevance can reasonably be thought
of as a scale, with some documents highly relevant and others marginally
so. But for the moment, we will use just a binary decision of relevance. We
Online edition (c)2009 Cambridge UP
8.2 Standard test collections 153
discuss the reasons for using binary relevance judgments and alternatives in
Section
8.5.1.
Many systems contain various weights (often known as parameters) that
can be adjusted to tune system performance. It is wrong to report results on
a test collection which were obtained by tuning these parameters to maxi-
mize performance on that collection. That is because such tuning overstates
the expected performance of the system, because the weights will be set to
maximize performance on one particular set of queries rather than for a ran-
dom sample of queries. In such cases, the correct procedure is to have one
or more develop ment test collections, and to tune the parameters on the devel-DEVELOPMENT TEST
COLLECTION
opment test collection. The tester then runs the system with those weights
on the test collection and reports the results on that collection as an unbiased
estimate of performance.
8.2 Standard test collections
Here is a list of the most standard test collections and evaluation series. We
focus particularly on test collections for ad hoc information retrieval system
evaluation, but also mention a couple of similar test collections for text clas-
sification.
The Cranfield collection. This was the pioneering test collection in allowingCRANFIELD
precise quantitative measures of information retrieval effectiveness, but
is nowadays too small for anything but the most elementary pilot experi-
ments. Collected in the United Kingdom starting in the late 1950s, it con-
tains 1398 abstracts of aerodynamics journal articles, a set of 225 queries,
and exhaustive relevance judgments of all (query, document) pairs.
Text Retrieval Conference (TREC). The U.S. National Institute of StandardsTREC
and Technology (NIST) has run a large IR test bed evaluation series since
1992. Within this framework, there have been many tracks over a range
of different test collections, but the best known test collections are the
ones used for the TREC Ad Hoc track during the first 8 TREC evaluations
between 1992 and 1999. In total, these test collections comprise 6 CDs
containing 1.89 million documents (mainly, but not exclusively, newswire
articles) and relevance judgments for 450 information needs, which are
called topics and specified in detailed text passages. Individual test col-
lections are defined over different subsets of this data. The early TRECs
each consisted of 50 information needs, evaluated over different but over-
lapping sets of documents. TRECs 6–8 provide 150 information needs
over about 528,000 newswire and Foreign Broadcast Information Service
articles. This is probably the best subcollection to use in future work, be-
cause it is the largest and the topics are more consistent. Because the test
Online edition (c)2009 Cambridge UP
154 8 Evaluation in information retrieval
document collections are so large, there are no exhaustive relevance judg-
ments. Rather, NIST assessors’ relevance judgments are available only for
the documents that were among the top k returned for some system which
was entered in the TREC evaluation for which the information need was
developed.
In more recent years, NIST has done evaluations on larger document col-
lections, including the 25 million page GOV2 web page collection. FromGOV2
the beginning, the NIST test document collections were orders of magni-
tude larger than anything available to researchers previously and GOV2
is now the largest Web collection easily available for research purposes.
Nevertheless, the size of GOV2 is still more than 2 orders of magnitude
smaller than the current size of the document collections indexed by the
large web search companies.
NII Test Collections for IR Systems (NTCIR). The NTCIR project has builtNTCIR
various test collections of similar sizes to the TREC collections, focus-
ing on East Asian language and cross-language information retrieval, whereCROSS-LANGUAGE
INFORMATION
RETRIEVAL
queries are made in one language over a document collection containing
documents in one or more other languages. See: http://research.nii.ac.jp/ntcir/data/data-
en.html
Cross Language Evaluation Forum (CLEF). This evaluation series has con-CLEF
centrated on European languages and cross-language information retrieval.
See: http://www.clef-campaign.org/
Reuters-21578 and Reuters-RCV1. For text classification, the most used testREUTERS
collection has been the Reuters-21578 collection of 21578 newswire arti-
cles; see Chapter
13, page 279. More recently, Reuters released the much
larger Reuters Corpus Volume 1 (RCV1), consisting of 806,791 documents;
see Chapter 4, page 69. Its scale and rich annotation makes it a better basis
for future research.
20 N ewsgroups. This is another widely used text classification collection,20 NEWSGROUPS
collected by Ken Lang. It consists of 1000 articles from each of 20 Usenet
newsgroups (the newsgroup name being regarded as the category). After
the removal of duplicate articles, as it is usually used, it contains 18941
articles.
8.3 Evaluation of unranked retrieval sets
Given these ingredients, how is system effectiveness measured? The two
most frequent and basic measures for information retrieval effectiveness are
precision and recall. These are first defined for the simple case where an

Online edition (c)2009 Cambridge UP
8.3 Evaluation of unranked retrieval sets 155
IR system returns a set of documents for a query. We will see later how to
extend these notions to ranked retrieval situations.
Precision (P) is the fraction of retrieved documents that are relevantPRECISION
Precision =
#(relevant items retrieved)
#(retrieved items)
= P(relevant|retrieved)
(8.1)
Recall (R) is the fraction of relevant documents that are retrievedRECALL
Recall =
#(relevant items retrieved)
#(relevant items)
= P(retrieved|relevant)
(8.2)
These notions can be made clear by examining the following contingency
table:
(8.3)
Relevant Nonrelevant
Retrieved true positives (tp) false positives (fp)
Not retrieved false negatives (fn) true negatives (tn)
Then:
P = tp/(tp + f p)
(8.4)
R = tp/(tp + f n)
An obvious alternative that may occur to the reader is to judge an infor-
mation retrieval system by its accuracy, that is, the fraction of its classifica-ACCURACY
tions that are correct. In terms of the contingency table above, accuracy =
(tp + tn)/(tp + f p + f n + tn). This seems plausible, since there are two ac-
tual classes, relevant and nonrelevant, and an information retrieval system
can be thought of as a two-class classifier which attempts to label them as
such (it retrieves the subset of documents which it believes to be relevant).
This is precisely the effectiveness measure often used for evaluating machine
learning classification problems.
There is a good reason why accuracy is not an appropriate measure for
information retrieval problems. In almost all circumstances, the data is ex-
tremely skewed: normally over 99.9% of the documents are in the nonrele-
vant category. A system tuned to maximize accuracy can appear to perform
well by simply deeming all documents nonrelevant to all queries. Even if the
system is quite good, trying to label some documents as relevant will almost
always lead to a high rate of false positives. However, labeling all documents
as nonrelevant is completely unsatisfying to an information retrieval system
user. Users are always going to want to see some documents, and can be