Kallen A. Understanding Biostatistics
Подождите немного. Документ загружается.


282 ANALYSIS OF DOSE RESPONSE
Box 10.1 The concept of the minimal effective dose
In the context of dose response, it is natural to try to find the minimal effective dose
(MED), but the way this is commonly used in drug development leads to some confusion
about its true meaning. It should be a medical concept, telling us what is the lowest dose
we can give in order to achieve a clinical benefit of the drug. This dose may vary between
patients, and we may need to interpret it to mean the lowest dose which, if given to the
population, shows a sufficient effect on a population basis. The problem is to define
what this means in quantitative terms, so that we can read off the corresponding dose
from the dose–response relationship. One way to do this is to define the MED as the
dose that gives the MID value (see Box 5.5), which would make sense provided the
MID makes sense. However, the MID is a relatively recent concept, and prior to this
it was notoriously hard to agree on how to quantify the properties the looked-for dose
should have.
Because of this difficulty, the medical community often turned to statisticians for
help, who solved the problem by scanning doses top-down as long as there is a sta-
tistically significant effect (compared to placebo). When it ceases to be, the MED had
been found on the previous dose level. However, this is not a medically meaningful
dose (unless you are very lucky); it is only the lowest dose that we can claim (beyond
reasonable doubt), from this study alone, to have an effect. It therefore depends on
how many patients we studied, and what significance level we use. Such defined MEDs
cannot be expected to be the same from two different studies that vary considerably
in size.
This definition of the MED may have some relevance for a regulatory authority,
for approval purposes, but it is not a medically sensible concept to use in the clinic.
The regulator needs statistical evidence that the dose in question has an effect, which
is information obtained from a group of patients. The physician’s interest is different.
that = σ
2
, where is derived from the design matrix for the model. We assume we have
estimates not only of m, but also of . The model used to obtain these estimates depends
on what design the clinical trial had, and which covariates we chose to adjust the mean
estimates for.
Once we have done this preliminary analysis, we want to investigate more closely how
the mean of the response variable depends on the dose. For simplicity, we first consider the
log-linear dose–response model, in which we assume that the relationship is E = a + b ln D.
With θ = (a, b) this model can be written in matrix notation as
m = Bθ, where B =
⎛
⎜
⎜
⎝
1lnD
1
.
.
.
.
.
.
1lnD
d
⎞
⎟
⎟
⎠
,
and from the discussion in Section 9.5 we have the following estimator for θ:
ˆ
θ = (B
t
−1
B)
−1
B
−1
ˆm ∈ N(θ, σ
2
(B
t
−1
B)
−1
).
The next example illustrates this, and also one particular use of the dose–response function.
ESTIMATION OF THE POPULATION AVERAGED DOSE–RESPONSE RELATIONSHIP 283
Example 10.2 We have a new drug A in an old drug class; such drugs are sometimes referred
to as me-too products. We wish to find out what dose of A gives the same effect as the standard
dose of one particular competitor, already on the market, which we denote by C and call the
control. We study three doses of A, all of which we believe are on the log-linear part of the
dose–response curve, together with the control.
At this point we do not need to be specific about what design we use. It may be a parallel
group design, or it may be some crossover design. What matters is that we start out with
some model of the data that produces unbiased estimates of the means with an approximate
Gaussian distribution. Next we construct a model m = Bθ similar to the one described above,
but we now add another component to the vector θ, namely the mean for the control treatment,
m
C
. This means that we add one row (at the bottom) and one column (to the right) to the
matrix B above, such that all additional elements are zero except for a one in the lower right
corner. With this modification the formula gives an estimate of this augmented θ, together
with the distribution of the corresponding estimator.
Next we wish to use this information to find the dose D
eq
of drug A which has the same
mean effect as the control. Mathematically this means that we want to solve the equation
a + b ln D = m
C
. Therefore ln D is given as the ratio (m
C
− a)/b, and we can obtain con-
fidence limits for this parameter using Fieller intervals, if we first determine the bivariate
Gaussian distribution for η = (m
C
− a, b). For this we introduce the design matrix
D =
−101
010
,
which is such that η = Dθ. A little matrix algebra shows that
ˆη = D
ˆ
θ ∈ N(Dθ, σ
2
D(B
t
MB)
−1
D
t
),
and we can now compute the confidence interval for the ratio as indicated. The final
confidence limits for D
eq
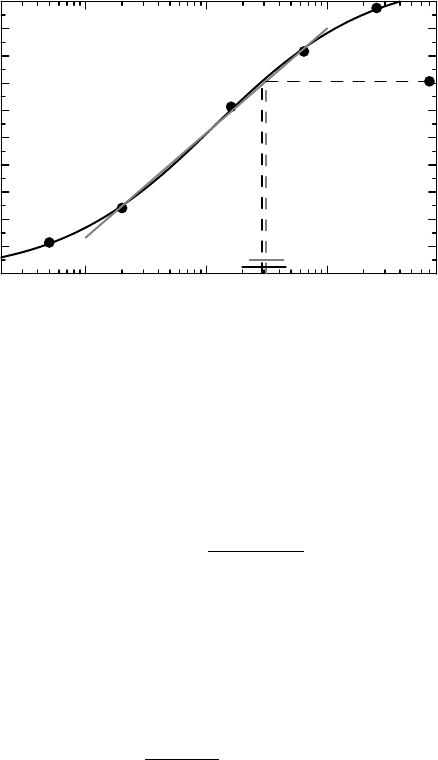
are obtained by exponentiating. The end result is illustrated in
gray in Figure 10.5, where we have plotted the straight line approximation to the middle
three mean values in the graph, as well as the mean of the control. The gray dashed lines
indicate the point estimate of D
eq
, with the corresponding confidence interval shown
close to the dose axis. The estimate and 95% confidence limits for D
eq
are 3.11 and
(2.28, 4.33), respectively.
The data used for this analysis are the data we generated in the previous section (with
measurement error), together with additional data for the control. We have used the middle
three mean values shown in Figure 10.4 to fit the straight line to, and then used this
dose–response function to estimate a quantity of some importance, namely the dose of the
new drug that gives the same mean effect as the control. Because of the nature of the data,
this analysis must have been preceded by a crossover study analysis to obtain mean and
covariance estimates.
Next we wish to do a similar analysis fitting a complete dose–response curve to all five
mean values in Figure 10.4. This analysis, to be discussed in the next example, is also illustrated
in Figure 10.5, now as the black curve and black confidence interval.
284 ANALYSIS OF DOSE RESPONSE
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Normalized effect
10
−1
10
0
10
1
Dose of drug
Figure 10.5 Illustration of two methods to estimate the dose that has a mean effect equivalent
to that of a control. The corresponding confidence intervals are shown close to the dose axis,
with the shorter gray one derived from the log-linear approximation and the black one derived
from the sigmoidal curve.
Example 10.3 In order to fit a sigmoidal curve to the response means of a series of doses,
we choose the four-parameter family of dose–response functions
E(D) = E
0
+
E
max
D
b
ED
b
50
+ D
b
as our model function. This, together with the control mean m
C
, provides us with a parameter
vector θ = (E
0
,E
max
,ED
50
,b,m
C
). Parameter estimation is performed by weighted nonlin-
ear regression to the (adjusted) means, as outlined in Section 9.5. The end result is an estimate
of θ, together with an estimate of the corresponding variance matrix. From this we wish to
estimate, with confidence limits, the parameter
ED
50
E
max
m
B
− E
0
− 1
−1/b
,
which is the solution to the equation E(D) = m
B
, and therefore the D
eq
from above. The
confidence limits for this nonlinear function are obtained in the same way as we obtained
confidence limits for functions of binomial parameters in Section 7.7, and which was outlined
on page 260 at the end of Section 9.5. Both the estimated dose–response curve and the point
estimate with 95% confidence interval for D
eq
are shown in black in Figure 10.5. Estimates
with confidence limits are 2.89 and (1.99, 4.52), respectively, which should be compared with
the result of the previous example. The new confidence interval is wider than the previous one.
When we compare the results from these two analyses, we see that we get a considerably
shorter interval with the first analysis. This is because the first analysis makes one assumption
the second does not: it assumes that the three doses we study are on a straight line. The second
analysis is not so sure about that, an uncertainty which is propagated into the corresponding
confidence interval.
ESTIMATING SUBJECT-SPECIFIC DOSE RESPONSES 285
In the examples above we used one variable to estimate D
eq
, albeit using two different
models. For many diseases the disease status is not accurately measured by only one outcome
variable. It is rather easy and direct to extend the methodology above to cover situations where
we use a number of outcome variables to simultaneously estimate a common D
eq
. We start
out with a multivariate analysis of a linear model in order to get all the mean values for all the
variables in one long vector, together with the variance matrix for this vector. That involves
some matrix algebra, but no mysteries. Then we construct the model function for these means
in such a way that there is a common D
eq
defined for all the variables. If we wish, we can
allow some of the other parameters to be variable-specific; in particular, it may be reasonable
to allow for variable-specific E
0
and E
max
, whereas variables may be assumed to have a
common slope.
10.6 Estimating subject-specific dose responses
The population averaged dose–response function in the previous section corresponds to a
randomly sampled patient who has been given a particular dose. We have seen that individual
dose–response curves may look quite different from the population averaged curve. If we have
data on different doses for individual patients it may be possible to get some information on
individual dose–response curves and how these vary in the population. In this section we will
consider two methods for estimating subject-specific dose–response curves, methods that are
similar to the method we used for the population average approach. They are methods with
limitations, and we will revisit the problem of estimating subject-specific curves again in the
final chapter of this book, in the context of the more general mixed-effects models.
Whichever estimation method we use, we first need a parametric representation of the
individual dose–response function. These should be defined from a common mathematical
formula, including subject-specific covariate information and subject-specific parameters,
which we denote ξ in this section. Next we want to describe how these subject-specific
parameters vary in the population. Conceptually the simplest approach to this is to perform
the analysis in a two-step fashion in the same way we did the meta-analysis that accounted
for heterogeneity in Section 6.8. In such a two-step approach:
1. the first step is to use data from each individual subject separately, to find the param-
eter estimate ξ
∗
i
that provides the best fit of the regression function to that particular
subject’s data;
2. the second step is to use these individual estimates to estimate a distribution for the
true model parameters ξ
i
in the population.
The complication is that ξ
∗
i
is only an estimate of the true parameter ξ
i
, but these estimates
come with an estimated standard deviation, derived from the analysis of the individual curves
and reflecting the precision with which the true parameter is estimated. If the true residual
variance for subject i is σ
2
i
, this means that V (ξ
∗
i
) = V (ξ
i
) + σ
2
i
, which must be taken into
account in the analysis.
Example 10.4 Consider again the individual data described in Section 10.4, and shown in
Figure 10.6 (a). Because of the measurement error, some observations are outside the valid
range for the true data; there are both negative values and values that are larger than one. The
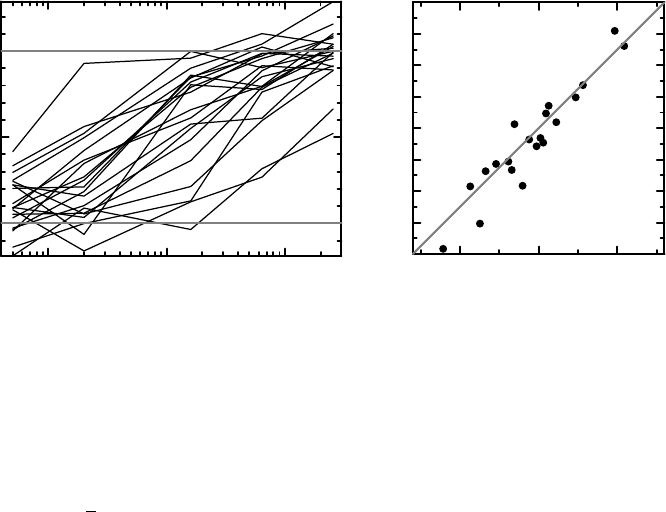
286 ANALYSIS OF DOSE RESPONSE
0
0.5
1
Effect
10
−1
10
0
10
1
Dose of drug
(a)
−4
−3
−2
−1
0
1
2
3
4
Estimated parameter value
−2.5 2.50
True parameter value
(b)
Figure 10.6 (a) shows the dose–response data as piecewise linear curves, (b) the correlation
between the (known) true parameter values and the estimated ones. Further details are given
in the text.
model assumption is that we have individual regression functions f (ξ, D) = D/(e
ξ
+ D),
with the parameter ξ assumed to follow a N(μ, η
2
) distribution (the true value of μ is zero
and that of η is
√
2). The measurement error is assumed to have the same standard deviation
σ (which we know is 0.1) across doses. Summing up, we have a model with three parameters
to estimate, constituting the vector θ = (μ, η, σ).
If we apply the two-stage method to our data, we first determine 20 subject-specific ξ
i
by
making 20 separate nonlinear regression analyses, one for each subject. The 20 dose–response
curves that we obtain are not exactly the same curves as shown in Figure 10.4, since they
use estimated parameters instead of true parameters, but they look rather similar. Since we
have simulated data, we know what the true parameter values are, and Figure 10.6 (b) shows
the relation between the true and the estimated ξ for our 20 individuals. There is a good
correlation, but some estimates do differ substantially from their true values. (Also note that
the estimated parameters span a wider range than the true ones.)
When we wish to describe the population distribution of ξ we need to take into account the
precision of the individual estimates. As already mentioned, we have encountered this problem
in Section 6.8, and doing an analogous analysis on the present data, we get the result that the
Gaussian distribution describing ξ has a mean value estimated to be μ
∗
= 0.44 and a standard
deviation estimated to be η
∗
= 1.00. We can also use this knowledge about the parameter
distribution in the population and update our estimates of the individual parameters. Such
updates are called empirical Bayes estimates, and are obtained by computing the a posteriori
distribution for the particular individual, using the Gaussian distribution N(μ
∗
,η
∗2
)asa priori
distribution, and then taking the value that maximizes this distribution as the updated estimate
of ξ for that individual.
We should note (as we did in Section 6.8) that the estimation method in the second step
in this case is not a least squares estimation, but a maximum likelihood estimation. This is
because of the way σ
2
enters the variance matrix (it is not a proportionality factor).
ESTIMATING SUBJECT-SPECIFIC DOSE RESPONSES 287
The drawback with the two-stage approach is that it requires relatively rich data for each
individual. There are, however, alternative one-step approaches that can also be carried out
with more sparse data. We will discuss here one particular one-step estimation method which
is very close in spirit to the population averaged method. It is not a method that is much
used in this context (such methods will be discussed in Section 13.5), but it represents a
relatively small conceptual leap from what we have done so far. The basic assumption is
that the distribution of ξ is described by a CDF P(ξ), which depends on some parameters; in
our case this is the CDF of the N(μ, η
2
) distribution. Under this assumption the population
average dose–response curve m(D)isgivenby
m(D) =
f (ξ, D)dP(ξ),
where f (ξ, D) is the regression function. Note that m(D) depends on parameters, both those in
the regression function and those in the distribution P(ξ), which we have suppressed from the
notation. Next we perform a weighted non-linear regression analysis, in which we fit observed
data (our estimates of the means) to this function. To do the actual fitting we need to estimate
the variance matrix for the data, which contains correlations, because some observations are
connected by being from the same individual (have the same value of ξ). The next example
gives some more mathematical details.
Example 10.5 To carry this out for the data above, we need to numerically evaluate integrals,
for which there are a few methods available. We use a classical method based on Hermite
polynomials with 100 nodes. The population mean function E(Y
i
) = m(D
i
,θ) for subjects
given the dose D
i
is then given by the integral
∞
−∞
D
i
e
μ+ξ
+ D
i
η
−1
ϕ(ξ/η)dξ = π
−1/2
∞
−∞
1
e
μ+
√
2xη−ln(D
i
)
+ 1
e
−x
2
dx,
which does not depend on the observational error variance σ
2
. The different Y
i
are correlated,
since data are observed at all five dose levels for each individual. In fact, the variance matrix
for the vector of observations for an individual is given by
V (D, θ) = π
−1/2
∞
−∞
(θ, D)
t
(θ, D)e
−x
2
dx + σ
2
I,
where (θ, D) = f (μ +
√
2xη, D) − m(D, θ). In this notation the arithmetic means are such
that ¯y ∈ N(m(D, θ),V(D, θ)/20), and parameter estimates are obtained by minimizing the
negative log-likelihood
20(¯y − m(D, θ))
t
V (D, θ)
−1
(¯y − m(D, θ)) + ln det(V (D, θ)).
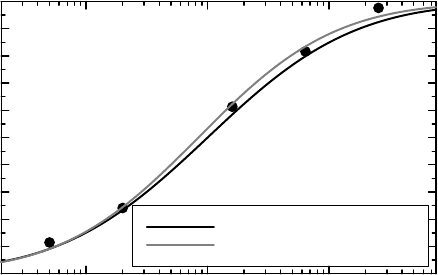
The solution to this minimization problem is μ =−0.18,η = 1.20 and σ = 0.100, and a
graphical comparison of the estimated mean curve compared to mean data as well as to the true
mean curve (available since we have simulated data) is given in Figure 10.7. The description
of the result is that the subject-specific dose–response curves look like f (ξ, D) = D/(ξ + D),
where the ξ = ED
50
follow a lognormal distribution in the population, the median of which
is given by e
−0.18
= 0.84, with a coefficient of variation of 100
e
1.20
2
− 1 = 180%.
288 ANALYSIS OF DOSE RESPONSE
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Normalized effect
10
−1
10
0
10
1
Dose of drug
True mean value curve
Estimated mean value curve
Figure 10.7 The agreement between the true dose–response curve (black) and the one
obtained from the one-step estimation method described in the text (gray).
We see that the second, technically more involved, method produced the better estimates
of the two in this case. However, as already pointed out, none of these methods is really the
preferred method to use. The preferred method is based on constructing the log-likelihood
for each individual and then constructing a global log-likelihood by summing these. Each
individual likelihood will involve an integral of the kind encountered above. Finally, we
maximize the likelihood. To get numerically feasible estimation methods, certain approximate
methods are commonly used, a topic we will discuss briefly in Section 13.5.
10.7 Comments and further reading
As in many other areas of biostatistics, there are some controversies about how to do proper
dose-finding for a drug. These controversies were not the purpose of this chapter, but the
interested reader may find an overview with references in Senn (2007,Chapter 20). Our purpose
is to use dose-finding as a role model for modeling how a particular outcome may depend on a
continuous covariate. For a classical discussion on dose–effect relationships, see Holford and
Sheiner (1981). The discussion in this chapter is closely related to the discussion in K
¨
all
´
en and
Larsson (1999). The extension of how to estimate the relative dose potency using more than
one outcome variable, mentioned on page 284, is discussed with examples in K
¨
all
´
en (2004).
References
Holford, N.H. and Sheiner, L.B. (1981) Understanding the dose-effect relationship: clinical application
of pharmacokinetic models. Clinical Pharmacokinetics, 6(6), 429–453.
K
¨
all
´
en, A. (2004) Multivariate estimation of the relative dose potency. Statistics in Medicine, 14, 2187–
2193.
K
¨
all
´
en, A. and Larsson, P. (1999) Dose response studies: how do we make them conclusive?.
Statistics in Medicine, 18, 629–641.
Senn, S. (2007) Statistical Issues in Drug Development. Chichester: John Wiley & Sons, Ltd.

11
Hazards and censored data
11.1 Introduction
In this and the next chapter we will address a different kind of data of considerable biomedical
importance. This is time-to-event data, with survival data as a role model. Such data are
special for a few reasons. One is that we often only have partial information for some of the
individuals; we may only know that the time to the event is longer than the time we have
observed the individual. Another reason is the very nature of the outcome variable, which is
time. Whereas the data we have analyzed so far are static – the observations just appear –
time-to-event data are dynamic in the sense that, in gathering them, we repeatedly ask whether
the event has occurred or not. Therefore the mathematics involved here is different from what
we have discussed so far, and the questions we ask are also different to some extent: they are
often conditional questions such as ‘given that someone is 75 years of age now, what is the
probability that he will celebrate his 90th birthday?’
In Chapter 6, which was about complete data, we indicated how we can estimate the CDF
in the presence of censoring mechanisms, using the Kaplan–Meier form of the e-CDF. Here
we will conduct a more detailed investigation into the properties of this estimator. It is a good
estimate of the CDF, or at least parts of it, because it is derived from something with a more
direct biological interpretation, the intensity, or hazard, function, which was introduced in
Section 2.7.
We also need to understand why censoring occurs. We often measure a particular kind of
survival, for example time to death in a specific cancer. A patient under study may, however,
die from another cause, such as a myocardial infarction. The presence of such competing
events poses some important questions, not only about what the Kaplan–Meier estimator
really estimates, but also about what the overall effect on the population would be if we took
action to modify one particular competing risk. If we eliminate all cancer deaths, people will
still die from other causes, so what impact would such a scientific breakthrough have on
how long we live? One of the earliest attempts to address such a question was made by the
Dutch-Swiss mathematician Daniel Bernoulli, when he investigated what the elimination of
smallpox would mean for overall mortality, in a model we will discuss below.
Understanding Biostatistics, First Edition. Anders K¨all´en.
© 2011 John Wiley & Sons, Ltd. Published 2011 by John Wiley & Sons, Ltd. ISBN: 978-0-470-66636-4
290 HAZARDS AND CENSORED DATA
The risk, or hazard, for the event is specific to the individual, and one question is how
these risks relate to the overall population risk. Heterogeneity in individual risks often distorts
the picture and dilutes the effects. The intuitive reason for this is that events that occur early
occur in frailer individuals, whereas events that occur later occur in less frail individuals,
and therefore the distribution of this frailty (the word used for heterogeneity in this context)
will have an impact on what is seen from a population perspective. But this also means that it
becomes very important to try to explain frailty in terms of covariates. Much of this discussion
will be taken up in the next chapter; here we take a preliminary look at the relationship between
individual risks and the population risk. This also includes a preliminary discussion about the
situation when we may have repeated events within subject.
The final part of this chapter is devoted to the mathematics of this kind of data. We need this
in the next chapter when we obtain confidence statements about group differences and derive
the famous Cox model. For this we need to understand the basic estimating equations and the
associated variance estimates. This is an area of mathematics called counting process theory,
and we outline some aspects of it at the end of this chapter. It is not necessary to read those parts
in order to understand the main points in the next chapter, but they provide some information
on the details of variance calculations and large-sample theory for counting processes.
11.2 Censored observations: incomplete knowledge
Data are censored when we do not know their precise value, but only have some bounds on
them. An observation t is left-censored if we only know that t<cfor some c, it is right-
censored if we only know that t>c and it is interval-censored if what we know is that
a<t<bfor some numbers a and b. Censored observations occur also for data that are not
time-to-event data, as the following example illustrates.
Example 11.1 Left-censored data occur when we measure concentrations of drugs in some
blood compartment. The assay that is used for such measurements typically has a lower
limit below which quantification is not possible (or not considered reliable), the limit of
quantification (LOQ) or lower limit of quantification (LLOQ). This limit may depend on the
blood volume taken, and may therefore vary from sample to sample.
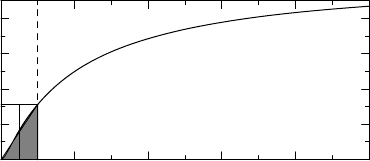
Figure 11.1 shows an example. The curve shows the CDF for the drug concentration
measured one hour after a drug was given. The vertical dashed line shows the LOQ limit,
which intersects the CDF at a level slightly greater than 0.3. If we take the data as given, and
ignore the < sign, the corresponding CDF would have a jump from zero to 0.3 at x = 0.5, and
0
0.2
0.4
0.6
0.8
543210
Dru
g
concentration
Figure 11.1 Illustration of how a distribution changes when there is a limit of quantification.
HAZARD MODELS FROM A POPULATION PERSPECTIVE 291
coincide with the original CDF for x>0.5. If we computed summary statistics on such data
we would get a mean that is larger than the true mean. To see how much, recall (see page 156)
that the mean value can be visualized as the area above the CDF curve (up to the level one).
The bias introduced when we use truncated data is therefore given by the gray area in the
graph. To reduce this bias, it is common practice to impute the value LOQ/2 for data below
the LOQ. In our case such imputation would be rather accurate in terms of mean estimation.
In fact, the (white) area above the curve in the small rectangle with base (0.25, 0.5) is of about
the same size as the gray area under the curve in the interval (0, 0.25), so these areas more or
less cancel each other out.
Data below the LOQ are really missing data, the curse of which was addressed in Sec-
tion 3.7. When we replace such data with LOQ/2 in descriptive statistics, we make an impu-
tation for missing values. However, in a statistical analysis we may not need to use imputed
data. If our choice of analysis is to do a rank test, what value we impute does not matter (as
long as the same value is imputed for all individuals and this is below the LOQ). If we use a
parametric model we can often avoid imputation altogether by using a likelihood method.
Censored data are most common in the time-to-event context. Right-censored data are
particularly relevant in that context; we may follow some patients after initiation of a new
treatment to see how long they live, but since the trial itself usually is restricted in time, we
may not be able to follow them all to their death. Instead we stop the trial at some specific
point in time, and for those still alive at that point, we only know that the survival time is
longer than the time we have observed them, not the exact value. There are a number of other
reasons why follow-up of a subject may cease before the event of interest has occurred. As
we will discuss in some detail later, for a proper analysis to be conducted, the reason why the
event has not been observed in an individual must be independent of his underlying risk for
the event (non-informative censoring), or there will be some issues around the interpretation
of the results. There will be bias in the results if there is a systematic withdrawal of either
high- or low-risk patients.
Left-censored data may also appear in this context, but not for randomized studies in which
the ‘clock starts’ at the point of randomization. In observational studies, however, when we
analyze the natural history of a disease, we might be interested in having birth as the origin
of time, and, depending on how subjects present themselves in the study, we may have left-
censored data; we may know that an event has happened prior to the first investigation, but
not when.
Interval-censored data also occur in some clinical trials. We may want to determine the
time to a particular event, but the determination of whether or not this event has occurred
can only be made at visits to the clinic, where the appropriate measurement can be obtained.
When to schedule visits to the clinic is defined in the protocol, and we may for a particular
individual only know that the event had not occurred at visit 3 after 23 days of treatment,
but had occurred at visit 4 after 56 days of treatment. This means that we know it occurred
somewhere in the time interval (23, 56) days, but not on which day.
11.3 Hazard models from a population perspective
To describe data for events that occur with a particular intensity, we first need to define
what we mean by an intensity, or hazard (these two words will be used interchangeably;